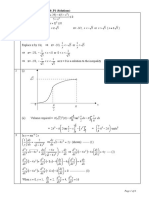
You might also like
- MJC JC2 H2 Maths 2012 Year End Exam Paper 2 Solutions PDFDocument10 pagesMJC JC2 H2 Maths 2012 Year End Exam Paper 2 Solutions PDFRyan LeeNo ratings yet
- 2014 H2 Maths Prelim Papers - NJC P1 SolutionDocument13 pages2014 H2 Maths Prelim Papers - NJC P1 Solutioncherylhzy0% (4)
- 2008 h2 Math Prelim p1 (Solns)Document19 pages2008 h2 Math Prelim p1 (Solns)Utsav NiroulaNo ratings yet
- Entropy ID3 ExerciseDocument3 pagesEntropy ID3 ExerciseVi LeNo ratings yet
- Test Bank for Precalculus: Functions & GraphsFrom EverandTest Bank for Precalculus: Functions & GraphsRating: 5 out of 5 stars5/5 (1)
- Homework For Module 3 Part 1 PDFDocument3 pagesHomework For Module 3 Part 1 PDFSai Chaitanya GudariNo ratings yet
- I211381 DSM Algo1Document8 pagesI211381 DSM Algo1I211381 Eeman IjazNo ratings yet
- Winsem2017-18 Cse4003 Eth Sjt502 Vl2017185003779 Reference Material II Ecc1-MadhuDocument100 pagesWinsem2017-18 Cse4003 Eth Sjt502 Vl2017185003779 Reference Material II Ecc1-MadhuMayank SharmaNo ratings yet
- IA-01function (1-11)Document8 pagesIA-01function (1-11)eamcetmaterialsNo ratings yet
- Q. B. Ist Semester 2019Document11 pagesQ. B. Ist Semester 2019Anuj TiwariNo ratings yet
- FunctionsDocument8 pagesFunctionsrodsingle346No ratings yet
- JJC JC 2 H2 Maths 2011 Mid Year Exam SolutionsDocument14 pagesJJC JC 2 H2 Maths 2011 Mid Year Exam SolutionsjimmytanlimlongNo ratings yet
- Applied I Work SheetDocument3 pagesApplied I Work SheetwabdushukurNo ratings yet
- Calc 1 Prelim AnswersDocument10 pagesCalc 1 Prelim AnswersNeil MonteroNo ratings yet
- Phd:304 Lab Report Advanced Mathematical Physics: Sachin Singh Rawat 16PH-06 (Department of Physics)Document12 pagesPhd:304 Lab Report Advanced Mathematical Physics: Sachin Singh Rawat 16PH-06 (Department of Physics)sachin rawatNo ratings yet
- CS 2013 SolvedDocument29 pagesCS 2013 SolvedAditya MishraNo ratings yet
- Vidyalankar Vidyalankar Vidyalankar Vidyalankar: Advanced Engineering MathematicsDocument16 pagesVidyalankar Vidyalankar Vidyalankar Vidyalankar: Advanced Engineering MathematicsPooja JainNo ratings yet
- Cape 2015 Pure Math - Unit 1 P 02 SolutionsDocument5 pagesCape 2015 Pure Math - Unit 1 P 02 Solutionskayla morrisonNo ratings yet
- Acsbr 2018 Prelim 4exp Am P1 AnsDocument6 pagesAcsbr 2018 Prelim 4exp Am P1 Ansc8ftcky9zwNo ratings yet
- 5Document10 pages5Cheryl ChongNo ratings yet
- 2013 JC2 H2 Math Post MYE Revision Paper Solns For Students PDFDocument9 pages2013 JC2 H2 Math Post MYE Revision Paper Solns For Students PDFDouglas TanNo ratings yet
- 0.1 حل الواجب .Document6 pages0.1 حل الواجب .m rmNo ratings yet
- 2006 Mathematics Extension 1 HSC Examination Terry Lee's SolutionDocument4 pages2006 Mathematics Extension 1 HSC Examination Terry Lee's SolutionYe ZhangNo ratings yet
- NJC JC 2 H2 Maths 2011 Mid Year Exam SolutionsDocument10 pagesNJC JC 2 H2 Maths 2011 Mid Year Exam SolutionsjimmytanlimlongNo ratings yet
- On The Series Å K 1 (3kk) - 1k-nxkDocument11 pagesOn The Series Å K 1 (3kk) - 1k-nxkapi-26401608No ratings yet
- 14-Elliptic Curve Cryptography (ECC) - 27!02!2024Document31 pages14-Elliptic Curve Cryptography (ECC) - 27!02!2024YashNo ratings yet
- My Calc 1 Exam#4Document8 pagesMy Calc 1 Exam#4Hassen JinyorNo ratings yet
- AP EAMCET 2018 Previous Year Question Papers With Solutions - 24th April 2018 Morning ShiftDocument202 pagesAP EAMCET 2018 Previous Year Question Papers With Solutions - 24th April 2018 Morning Shiftyashwanthkumarmannava18No ratings yet
- Short Practice Test 01 - Test Paper - Yakeen NEET 3.0 2024Document5 pagesShort Practice Test 01 - Test Paper - Yakeen NEET 3.0 2024RyzoxbeatsNo ratings yet
- Discussion 12 Fall 2019 SolutionsDocument8 pagesDiscussion 12 Fall 2019 SolutionssamNo ratings yet
- Divide-And-Conquer: 1 MergesortDocument5 pagesDivide-And-Conquer: 1 MergesortMohamed ShukurNo ratings yet
- Chapter 2.3 - Relation and FunctionDocument12 pagesChapter 2.3 - Relation and FunctionPoeil Sergio MoldezNo ratings yet
- Edu 2008 Spring C SolutionsDocument117 pagesEdu 2008 Spring C SolutionswillhsladeNo ratings yet
- On The Rapid Computation of Various Polylogarithmic ConstantsDocument13 pagesOn The Rapid Computation of Various Polylogarithmic Constantsek_rzepkaNo ratings yet
- Math 181 Weekly Problem 10Document2 pagesMath 181 Weekly Problem 10samdh0739No ratings yet
- Diffrential Equation - Fourier SeriesDocument31 pagesDiffrential Equation - Fourier SeriesjonahNo ratings yet
- 804purl PandDS TYSDocument8 pages804purl PandDS TYSVivek RanjanNo ratings yet
- 2008 2009 1 (Q+S)Document18 pages2008 2009 1 (Q+S)marwanNo ratings yet
- Math Full BookDocument2 pagesMath Full Bookm.bakhsh121412No ratings yet
- Allen: Solution (Set-2) Section - ADocument12 pagesAllen: Solution (Set-2) Section - APriya SatheeshNo ratings yet
- Chew 1505 CH2Document66 pagesChew 1505 CH2lzyabc597No ratings yet
- Repartido de Ejercicios - SoDocument5 pagesRepartido de Ejercicios - SoSantiago MateuNo ratings yet
- DPP - 8 English PC YoqvisBDocument7 pagesDPP - 8 English PC YoqvisBSuvrajyoti TaraphdarNo ratings yet
- Vector Calculus and Differential Equations: Chaitanya Bharathi Institute of TechnologyDocument2 pagesVector Calculus and Differential Equations: Chaitanya Bharathi Institute of TechnologySruthi ChallapalliNo ratings yet
- Mix Pure Math 1-2-3 MarkschemeDocument5 pagesMix Pure Math 1-2-3 MarkschemeDarlene BellesiaNo ratings yet
- Sol Adv Pure 2011 PDFDocument14 pagesSol Adv Pure 2011 PDFMargaretNo ratings yet
- MSI Calculus MemosDocument34 pagesMSI Calculus Memosymadikane38No ratings yet
- 2007 A Level Math SolnDocument25 pages2007 A Level Math SolnTan GkNo ratings yet
- CSEC ADD Maths SPECIMEN PAPER 1 PDFDocument26 pagesCSEC ADD Maths SPECIMEN PAPER 1 PDFreeta ram100% (1)
- IB 14tanget Normal (66 70)Document3 pagesIB 14tanget Normal (66 70)eamcetmaterialsNo ratings yet
- 2010 AJC Paper 1solDocument6 pages2010 AJC Paper 1solnothingtodo1992No ratings yet
- JEE Main Online Exam 2020: Question With SolutionsDocument12 pagesJEE Main Online Exam 2020: Question With SolutionsManohaR GaherwarNo ratings yet
- Let'S Do This Complete Trigonometry!: Sin Sin Cos CosDocument5 pagesLet'S Do This Complete Trigonometry!: Sin Sin Cos CosDavid AbadianoNo ratings yet
- Homework 8 Solutions: Stat 516Document2 pagesHomework 8 Solutions: Stat 516Putri NurrifkadillahNo ratings yet
- (Mathematics) PDFDocument11 pages(Mathematics) PDFL.ABHISHEK KUMARNo ratings yet
- BCS 12 - June2010 June2023Document94 pagesBCS 12 - June2010 June2023RohitNo ratings yet
- TCP2101 Algorithm Design and Analysis Lab07 - Divide-and-ConquerDocument5 pagesTCP2101 Algorithm Design and Analysis Lab07 - Divide-and-Conquerhusnazk.workNo ratings yet
- Dbns Theo Appl HandoutDocument38 pagesDbns Theo Appl HandoutAritra BanerjeeNo ratings yet
- Exploring Function Unit Kseniia SheikoDocument6 pagesExploring Function Unit Kseniia SheikoДаша СтепановаNo ratings yet
- Dynamic Programming: Example: If N 10, RDocument16 pagesDynamic Programming: Example: If N 10, RrambabudugyaniNo ratings yet
- Ten-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesFrom EverandTen-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesNo ratings yet
- V2019 en TDT4300Document10 pagesV2019 en TDT4300AbdulNo ratings yet
- The Probabilistic Relevance Framework BM25 and BeyDocument60 pagesThe Probabilistic Relevance Framework BM25 and BeyAbdulNo ratings yet
- MainDocument16 pagesMainAbdulNo ratings yet
- Order Confirmation - NODocument1 pageOrder Confirmation - NOAbdulNo ratings yet
- Kult 2207 - 2208 Syllabus v23 FinalDocument4 pagesKult 2207 - 2208 Syllabus v23 FinalAbdulNo ratings yet
- Erricos Kontoghiorghes, Cristian Gatu - Optimal Quadratic Programming Algorithms (2009, Springer)Document289 pagesErricos Kontoghiorghes, Cristian Gatu - Optimal Quadratic Programming Algorithms (2009, Springer)Juan Carlos ColqueNo ratings yet
- Lecture - Asymptotic Complexity and Abstract Data TypesDocument35 pagesLecture - Asymptotic Complexity and Abstract Data TypesChetan SharmaNo ratings yet
- Sheet 4Document3 pagesSheet 4Apdo MustafaNo ratings yet
- 3 Job Shop Scheduling PDFDocument7 pages3 Job Shop Scheduling PDF123away123No ratings yet
- Data Structures Notes 155 177Document23 pagesData Structures Notes 155 177Ruthvik RachaNo ratings yet
- Lect 37Document16 pagesLect 37zafrin zaraNo ratings yet
- CSC203Document5 pagesCSC203Nithya SubuNo ratings yet
- Istm MD. Sirajul Islam Id:16172103257 Intake: 35: Import As From Import From Import Import As From Import From ImportDocument5 pagesIstm MD. Sirajul Islam Id:16172103257 Intake: 35: Import As From Import From Import Import As From Import From Importmd.sirajul islamNo ratings yet
- 08 - Delta Sigma PDFDocument20 pages08 - Delta Sigma PDFAmy BarryNo ratings yet
- DS Unit Iii QBDocument4 pagesDS Unit Iii QB5052 - UTHRA .TNo ratings yet
- cs237b Lecture 6Document7 pagescs237b Lecture 6movicNo ratings yet
- YOLO V3 ML ProjectDocument15 pagesYOLO V3 ML ProjectAnnie ShuklaNo ratings yet
- Data Mining ClusteringDocument76 pagesData Mining ClusteringAnjali Asha JacobNo ratings yet
- Daa Week 6Document3 pagesDaa Week 6Anushka RawatNo ratings yet
- Lecture Notes 02Document65 pagesLecture Notes 02zhao lingerNo ratings yet
- PPH109Document2 pagesPPH109Satyam TiwariNo ratings yet
- The MD5 Encryption & Decryption TechniqueDocument14 pagesThe MD5 Encryption & Decryption TechniquekumarklNo ratings yet
- Machine Vesion hw6Document18 pagesMachine Vesion hw6Teddy BzNo ratings yet
- DIP Project ReportDocument10 pagesDIP Project ReportWaleed Pervaiz MughalNo ratings yet
- IOE Syllabus of Data MiningDocument2 pagesIOE Syllabus of Data MiningBulmi HilmeNo ratings yet
- Lecture 4 - Simplex MethodDocument19 pagesLecture 4 - Simplex MethodTarekYehiaNo ratings yet
- Object Type Unit2ADocument2 pagesObject Type Unit2ASivagami PunithavathiNo ratings yet
- Math Problems On IIR Filter Coefficients CalculationDocument2 pagesMath Problems On IIR Filter Coefficients Calculationharun or rashidNo ratings yet
- DSP Online Mid Exam 2020Document2 pagesDSP Online Mid Exam 2020Vishal KevatNo ratings yet
- Hash Function - Wikipedia, The Free EncyclopediaDocument5 pagesHash Function - Wikipedia, The Free EncyclopediaKobeNo ratings yet
- Comparative Analysis of Image Classification Algorithms For Face Mask DetectionDocument11 pagesComparative Analysis of Image Classification Algorithms For Face Mask Detectionikhwancules46No ratings yet
- 16.MCTS TutorialDocument28 pages16.MCTS Tutorialkak.isNo ratings yet
- Greedy Method: General Method, Coin Change Problem Knapsack Problem Job Sequencing With Minimum Spanning TreeDocument55 pagesGreedy Method: General Method, Coin Change Problem Knapsack Problem Job Sequencing With Minimum Spanning TreeShamanth RNo ratings yet
- Makerere University: Chapter Four: Numerical AnalysisDocument36 pagesMakerere University: Chapter Four: Numerical AnalysisDembeoscarNo ratings yet