You might also like
- Investigation of the Usefulness of the PowerWorld Simulator Program: Developed by "Glover, Overbye & Sarma" in the Solution of Power System ProblemsFrom EverandInvestigation of the Usefulness of the PowerWorld Simulator Program: Developed by "Glover, Overbye & Sarma" in the Solution of Power System ProblemsNo ratings yet
- Operating Systems Interview Questions You'll Most Likely Be AskedFrom EverandOperating Systems Interview Questions You'll Most Likely Be AskedNo ratings yet
- Choosing The Right UPSDocument11 pagesChoosing The Right UPSDavid HicksNo ratings yet
- Parallel UPS Configurations WP en 6 2012Document10 pagesParallel UPS Configurations WP en 6 2012MO.SHAHINNo ratings yet
- Parallel Ups SystemsDocument10 pagesParallel Ups SystemsShameel PtNo ratings yet
- White Paper 75 Comparing UPS System DesignDocument27 pagesWhite Paper 75 Comparing UPS System DesignRiad RiadNo ratings yet
- Sade-5tpl8x R3 en PDFDocument27 pagesSade-5tpl8x R3 en PDFAlexandre PereiraNo ratings yet
- High Availability Power Systems Redundancy Options-Seminar ReportDocument23 pagesHigh Availability Power Systems Redundancy Options-Seminar Report9866615335100% (2)
- Making Large Ups Systems More EfficientDocument21 pagesMaking Large Ups Systems More EfficientJohn CollinsNo ratings yet
- DS Catalogue UPS EnglishDocument51 pagesDS Catalogue UPS Englishmehdi227No ratings yet
- Active Parallel: Advantages DisadvantagesDocument34 pagesActive Parallel: Advantages DisadvantagesEnergy Trading QUEZELCO 1No ratings yet
- Ups de Sigh ConsiderationDocument15 pagesUps de Sigh Considerationkaliman2010No ratings yet
- APC White PapersDocument27 pagesAPC White Papersmonarch_007100% (1)
- WP5 UPS Design ConfigurationsDocument7 pagesWP5 UPS Design ConfigurationsAntony MadduamgeNo ratings yet
- SOP For DistributionDocument1 pageSOP For Distributionsf111No ratings yet
- Critical-Power Automatic Transfer Systems - Design and ApplicationDocument18 pagesCritical-Power Automatic Transfer Systems - Design and ApplicationRazvan Mares100% (1)
- White Paper: Power Redundancy Schemes For Data CentersDocument11 pagesWhite Paper: Power Redundancy Schemes For Data CentersAllamNo ratings yet
- Picking Right Ups Sl-24676Document12 pagesPicking Right Ups Sl-24676David HicksNo ratings yet
- 14 Vol 39 No 1Document10 pages14 Vol 39 No 1Sarah DewiNo ratings yet
- Power Redundancy in The Data Center - Course PreviewDocument5 pagesPower Redundancy in The Data Center - Course PreviewscribdjbarrosNo ratings yet
- Data Center Facility ConsiderationsDocument16 pagesData Center Facility ConsiderationsVijay KumarNo ratings yet
- Finite Control Set Model Predictive Control For PaDocument30 pagesFinite Control Set Model Predictive Control For Paxuyen tranNo ratings yet
- Calculation of Sensitive Node For Ieee - 14 Bus System When Subjected To Various Changes in LoadDocument4 pagesCalculation of Sensitive Node For Ieee - 14 Bus System When Subjected To Various Changes in LoadfpttmmNo ratings yet
- Paper18 NW ReconfigurationDocument4 pagesPaper18 NW Reconfigurationtobu11276No ratings yet
- What Parallel Redundancy Does To The Power Distribution System - EEPDocument4 pagesWhat Parallel Redundancy Does To The Power Distribution System - EEPJhonci CoriNo ratings yet
- Chapter - 5 Network ReconfigurationDocument38 pagesChapter - 5 Network ReconfigurationIam SriNo ratings yet
- UPS System ConfigurationsDocument38 pagesUPS System ConfigurationsRM PatilNo ratings yet
- CET Power - Whitepaper - No Break Vs Conventional UPSDocument16 pagesCET Power - Whitepaper - No Break Vs Conventional UPSjokotsNo ratings yet
- Exercise 4Document2 pagesExercise 4Dushantha BandaraNo ratings yet
- Reliability Avalilability ServiceabilityDocument5 pagesReliability Avalilability ServiceabilityArturo CastellanosNo ratings yet
- Isolation Transformer Role in UPSDocument26 pagesIsolation Transformer Role in UPSAchint Rajput100% (1)
- An Introduction To FaultDocument6 pagesAn Introduction To FaultÁsgeirr Ánsgar Ósgar CanuroNo ratings yet
- Technical UPS GlossaryDocument5 pagesTechnical UPS GlossaryKeyboardMan1960No ratings yet
- Design Guide UPSDocument18 pagesDesign Guide UPSVictor BitarNo ratings yet
- Choosing Between Distributed and Centralized Parallel UPS SystemsDocument9 pagesChoosing Between Distributed and Centralized Parallel UPS SystemsParveshi PusunNo ratings yet
- Maximizing UPS Availability WP EN 6 2012Document12 pagesMaximizing UPS Availability WP EN 6 2012Brent DonedNo ratings yet
- Omar2010 PDFDocument6 pagesOmar2010 PDFYogesh SharmaNo ratings yet
- ShareDocument8 pagesShareMuhammad Abdullah ShahzadNo ratings yet
- Approach: F M Ups E (T U L L) - N W R I A C D - C Ups TDocument1 pageApproach: F M Ups E (T U L L) - N W R I A C D - C Ups TKdc OuinbiloNo ratings yet
- Optimal Voltage Regulator Placement in A Radial Distribution System Using Fuzzy Logic 2Document8 pagesOptimal Voltage Regulator Placement in A Radial Distribution System Using Fuzzy Logic 2Ganesh CmNo ratings yet
- Power Distribution System Load Flow Usin PDFDocument6 pagesPower Distribution System Load Flow Usin PDFbertovalenNo ratings yet
- Comparing UPS System Design ConfigurationDocument51 pagesComparing UPS System Design ConfigurationYouwan LeeNo ratings yet
- White Paper Centralized UPS and Distributed UPS A Comparison WP0012 en UsDocument6 pagesWhite Paper Centralized UPS and Distributed UPS A Comparison WP0012 en UsAHDPCSNo ratings yet
- Failure Rate For Electrical EquipmentDocument10 pagesFailure Rate For Electrical EquipmentwholenumberNo ratings yet
- Toolbox For Power System Dynamics and Control Engineering Education and ResearchDocument6 pagesToolbox For Power System Dynamics and Control Engineering Education and ResearchLuis Alonso Aguirre LopezNo ratings yet
- Capability of single hardware channel for automotive safety applications using coded processingDocument5 pagesCapability of single hardware channel for automotive safety applications using coded processingMaXimus SaivigneshNo ratings yet
- 9bus System, Power FlowDocument17 pages9bus System, Power FlowZeeshan AhmedNo ratings yet
- Modular UPS SystemsDocument2 pagesModular UPS Systemssarang11No ratings yet
- Apc Role of Isolation Transformaers in Data Center Ups SystemsDocument26 pagesApc Role of Isolation Transformaers in Data Center Ups SystemsengrrafNo ratings yet
- RPADocument2 pagesRPAmehdivinciNo ratings yet
- HW1Document2 pagesHW1indrajeet4saravananNo ratings yet
- Dynamic Voltage and Frequency Scaling and Adaptive Body Biasing For Active and Leakage Power Reduction in MPSOC: A Literature OverviewDocument8 pagesDynamic Voltage and Frequency Scaling and Adaptive Body Biasing For Active and Leakage Power Reduction in MPSOC: A Literature OverviewAamir ShaikNo ratings yet
- Load Flow Analysis PDFDocument58 pagesLoad Flow Analysis PDFfathonixNo ratings yet
- Platform Tech Mod 3Document20 pagesPlatform Tech Mod 3venus camposanoNo ratings yet
- Modeling, Simulation, and Verification of Large DC Power Electronics SystemsDocument7 pagesModeling, Simulation, and Verification of Large DC Power Electronics SystemsAndrés VareloNo ratings yet
- 711ab32f69d23c5 EkDocument6 pages711ab32f69d23c5 Eknzar HasanNo ratings yet
- A Low-Cost Non-Intrusive Appliance Load Monitoring System: Supratim Das, Srikrishna, Ankita Shukla, GNS Harsha Sujay DebDocument4 pagesA Low-Cost Non-Intrusive Appliance Load Monitoring System: Supratim Das, Srikrishna, Ankita Shukla, GNS Harsha Sujay DebSharan Kumar GoudNo ratings yet
- IconicDocument43 pagesIconicbaparisNo ratings yet
- EMAAR Cairo Uptown Fire Alarm Comments Rev04Document2 pagesEMAAR Cairo Uptown Fire Alarm Comments Rev04baparisNo ratings yet
- Electrical Plans NotesDocument1 pageElectrical Plans NotesbaparisNo ratings yet
- Pump Inatallation, Method StatementDocument8 pagesPump Inatallation, Method StatementbaparisNo ratings yet
- Draining Piping System Installation Method StatementDocument8 pagesDraining Piping System Installation Method StatementbaparisNo ratings yet
- EMAAR Cairo Uptown Fire Alarm Comments Rev04Document2 pagesEMAAR Cairo Uptown Fire Alarm Comments Rev04baparisNo ratings yet
- Electrical wiring diagram notesDocument1 pageElectrical wiring diagram notesbaparisNo ratings yet
- Diesel Generator WarrantyDocument1 pageDiesel Generator WarrantybaparisNo ratings yet
- Pit 2Document1 pagePit 2baparisNo ratings yet
- Utc-Ph2-Dmc-B4-0bf-Sd-El-Lc-302-02 (5) - Utc-Ph2-Dmc-B4-0bf-Sd-El-Lc-302Document1 pageUtc-Ph2-Dmc-B4-0bf-Sd-El-Lc-302-02 (5) - Utc-Ph2-Dmc-B4-0bf-Sd-El-Lc-302baparisNo ratings yet
- Sump Pit Sizing: Input DataDocument1 pageSump Pit Sizing: Input DatabaparisNo ratings yet
- Pit 2Document1 pagePit 2baparisNo ratings yet
- Up Town Cairo Master Plan ProjectDocument1 pageUp Town Cairo Master Plan ProjectbaparisNo ratings yet
- Uptown Cairo Village 100% TD - Rev.01 Page 9 of 14 October, 2018Document1 pageUptown Cairo Village 100% TD - Rev.01 Page 9 of 14 October, 2018baparisNo ratings yet
- IESLuxLevel 1Document12 pagesIESLuxLevel 1tr_nisitNo ratings yet
- UTC-ATC-RMC-TRA-099Document2 pagesUTC-ATC-RMC-TRA-099baparisNo ratings yet
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Product Input Guide For Kitchen Ventilation Systems: SummaryDocument2 pagesProduct Input Guide For Kitchen Ventilation Systems: SummarybaparisNo ratings yet
- Gauge Thick (MM) Wight / Sheet (KG) : Item Width (Inch) Depth (Inch) No of SH Gauge Thick Wight / SH Total WightDocument12 pagesGauge Thick (MM) Wight / Sheet (KG) : Item Width (Inch) Depth (Inch) No of SH Gauge Thick Wight / SH Total WightbaparisNo ratings yet
- Gta San Andreas Cheat CodesDocument1 pageGta San Andreas Cheat CodesbaparisNo ratings yet
- Gauge Thick (MM) Wight / Sheet (KG) : Item Width (Inch) Depth (Inch) No of SH Gauge Thick Wight / SH Total WightDocument12 pagesGauge Thick (MM) Wight / Sheet (KG) : Item Width (Inch) Depth (Inch) No of SH Gauge Thick Wight / SH Total WightbaparisNo ratings yet
- Mom Z3Document3 pagesMom Z3baparisNo ratings yet
- MOM Elevator ASGCDocument2 pagesMOM Elevator ASGCbaparisNo ratings yet
- Hvac Condensate Calculator: Difference in Specific Humidity gr/ft3Document4 pagesHvac Condensate Calculator: Difference in Specific Humidity gr/ft3baparisNo ratings yet
- UnifierDocument1 pageUnifierbaparisNo ratings yet
- Hvac Condensate Calculator: Difference in Specific Humidity gr/ft3Document4 pagesHvac Condensate Calculator: Difference in Specific Humidity gr/ft3baparisNo ratings yet
- Basics of Electrical BuswayDocument95 pagesBasics of Electrical BuswayjebicoreNo ratings yet
- ALL - Purpose - Worksheet (ConversionsDocument28 pagesALL - Purpose - Worksheet (ConversionsbaparisNo ratings yet
- Building Phase 2 Floor Apply To All Room Corridor Equip. No. FCU-L4-C-01 ZoneDocument8 pagesBuilding Phase 2 Floor Apply To All Room Corridor Equip. No. FCU-L4-C-01 ZonebaparisNo ratings yet
- Classroom Observation Form 1Document4 pagesClassroom Observation Form 1api-252809250No ratings yet
- Tuberculin Skin Test: Facilitator GuideDocument31 pagesTuberculin Skin Test: Facilitator GuideTiwi NaloleNo ratings yet
- SMEs, Trade Finance and New TechnologyDocument34 pagesSMEs, Trade Finance and New TechnologyADBI EventsNo ratings yet
- Grade 8 Lily ExamDocument3 pagesGrade 8 Lily ExamApril DingalNo ratings yet
- Multivariate Analysis Homework QuestionsDocument2 pagesMultivariate Analysis Homework Questions歐怡君No ratings yet
- PiXL Knowledge Test ANSWERS - AQA B1 CORE Science - Legacy (2016 and 2017)Document12 pagesPiXL Knowledge Test ANSWERS - AQA B1 CORE Science - Legacy (2016 and 2017)Mrs S BakerNo ratings yet
- Hydrocarbon: Understanding HydrocarbonsDocument9 pagesHydrocarbon: Understanding HydrocarbonsBari ArouaNo ratings yet
- 2010 HSC Exam PhysicsDocument42 pages2010 HSC Exam PhysicsVictor345No ratings yet
- City MSJDocument50 pagesCity MSJHilary LedwellNo ratings yet
- Early Diabetic Risk Prediction Using Machine Learning Classification TechniquesDocument6 pagesEarly Diabetic Risk Prediction Using Machine Learning Classification TechniquesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- U-KLEEN Moly Graph MsdsDocument2 pagesU-KLEEN Moly Graph MsdsShivanand MalachapureNo ratings yet
- Emilio Aguinaldo CollegeDocument1 pageEmilio Aguinaldo CollegeRakeshKumar1987No ratings yet
- EST I - Literacy Test I (Language)Document20 pagesEST I - Literacy Test I (Language)Mohammed Abdallah100% (1)
- Phaseo Abl7 Abl8 Abl8rps24100Document9 pagesPhaseo Abl7 Abl8 Abl8rps24100Magda DiazNo ratings yet
- Bhakti Trader Ram Pal JiDocument232 pagesBhakti Trader Ram Pal JiplancosterNo ratings yet
- Administracion Una Perspectiva Global Y Empresarial Resumen Por CapitulosDocument7 pagesAdministracion Una Perspectiva Global Y Empresarial Resumen Por Capitulosafmqqaepfaqbah100% (1)
- Essene Moses Ten CommandmentsDocument4 pagesEssene Moses Ten Commandmentsjeryon91No ratings yet
- ProjectDocument86 pagesProjectrajuNo ratings yet
- LNG Vaporizers Using Various Refrigerants As Intermediate FluidDocument15 pagesLNG Vaporizers Using Various Refrigerants As Intermediate FluidFrandhoni UtomoNo ratings yet
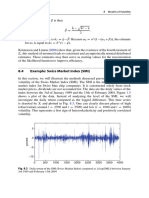
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- Financial Accounting IFRS 3rd Edition Weygandt Solutions Manual 1Document8 pagesFinancial Accounting IFRS 3rd Edition Weygandt Solutions Manual 1jacob100% (34)
- AWS Cloud Practicioner Exam Examples 0Document110 pagesAWS Cloud Practicioner Exam Examples 0AnataTumonglo100% (3)
- Oracle Apps Quality ModuleDocument17 pagesOracle Apps Quality ModuleSantOsh100% (2)
- Pharma TestDocument2 pagesPharma TestMuhammad AdilNo ratings yet
- Klein & Kulick Scandolous ActsDocument20 pagesKlein & Kulick Scandolous ActsClaudia Costa GarcíaNo ratings yet
- Business Analysis FoundationsDocument39 pagesBusiness Analysis FoundationsPriyankaNo ratings yet
- Visualization BenchmarkingDocument15 pagesVisualization BenchmarkingRanjith S100% (1)
- How Do I Prepare For Public Administration For IAS by Myself Without Any Coaching? Which Books Should I Follow?Document3 pagesHow Do I Prepare For Public Administration For IAS by Myself Without Any Coaching? Which Books Should I Follow?saiviswanath0990100% (1)
- Drug Study TramadolDocument7 pagesDrug Study TramadolZyrilleNo ratings yet
- 1 PBDocument11 pages1 PBAnggita Wulan RezkyanaNo ratings yet