You might also like
- 8D Project On - Uncut Thread: Product: Men's Short, Line No# 01 (I-2)Document15 pages8D Project On - Uncut Thread: Product: Men's Short, Line No# 01 (I-2)prashantmithare75% (4)
- Modbus Interface For SUNNY CENTRALDocument61 pagesModbus Interface For SUNNY CENTRALjosepablohg100% (1)
- LajakLaku Tablet Production Analysis For April 2023Document8 pagesLajakLaku Tablet Production Analysis For April 2023Aiman ZanNo ratings yet
- Lecture7appendixa 12thsep2009Document31 pagesLecture7appendixa 12thsep2009Richa ShekharNo ratings yet
- Major Project PPT On Optimization of 3D-Printing Process ParametersDocument47 pagesMajor Project PPT On Optimization of 3D-Printing Process ParametersDeepti VairagiNo ratings yet
- Customer BDocument10 pagesCustomer Bjugnu gargNo ratings yet
- Hasil Olah Data SPSSDocument21 pagesHasil Olah Data SPSSFa FasihaNo ratings yet
- Big Data Analysis Assig.2Document5 pagesBig Data Analysis Assig.2gerrydenis20No ratings yet
- Correlation, Regression and Test of Signficance in RDocument16 pagesCorrelation, Regression and Test of Signficance in RpremNo ratings yet
- Data Mining - Weka 3.6.0Document5 pagesData Mining - Weka 3.6.0Navee JayakodyNo ratings yet
- Laporan Praktikum StatistikaDocument74 pagesLaporan Praktikum StatistikaElexi Violletta Zidomi 2242101998No ratings yet
- Exercise 5: - P3wanjcDocument3 pagesExercise 5: - P3wanjcBerfelyn Daniela VillaruzNo ratings yet
- Notes Chap 2 OrganizeDocument9 pagesNotes Chap 2 OrganizeAbtehal AlfahaidNo ratings yet
- Case 1Document23 pagesCase 1Emad RashidNo ratings yet
- Nist 46h (Inglés)Document8 pagesNist 46h (Inglés)Edgard VásquezNo ratings yet
- 20 Statistics DataAnalysis ExpResultsINTaPRESDocument16 pages20 Statistics DataAnalysis ExpResultsINTaPRESrasha assafNo ratings yet
- Lampira. 5 Normalitas Data: One-Sample Kolmogorov-Smirnov TestDocument5 pagesLampira. 5 Normalitas Data: One-Sample Kolmogorov-Smirnov TestAyu Puspitasari La'karyaNo ratings yet
- Cs7602 - Machine Learning Assignment 1: Submitted byDocument11 pagesCs7602 - Machine Learning Assignment 1: Submitted byAkhila PadmanabhanNo ratings yet
- Introduction To Machine LearningDocument48 pagesIntroduction To Machine LearningKylleNo ratings yet
- Regression Analysis Final ProjectDocument8 pagesRegression Analysis Final ProjectUsama YasinNo ratings yet
- Design Space Process Models With Monte Carlo SimulationDocument38 pagesDesign Space Process Models With Monte Carlo Simulationsellerm4c1n2No ratings yet
- Frequencies: Frequencies Variables A1 A2 A3 A4 A5 A6 /statistics Stddev Variance Range Mean Median Mode /order AnalysisDocument3 pagesFrequencies: Frequencies Variables A1 A2 A3 A4 A5 A6 /statistics Stddev Variance Range Mean Median Mode /order AnalysisNUR SYAKIRAH BINTI ABD SAMAD MoeNo ratings yet
- Frequencies: Frequencies Variables A1 A2 A3 A4 A5 A6 /statistics Stddev Variance Range Mean Median Mode /order AnalysisDocument3 pagesFrequencies: Frequencies Variables A1 A2 A3 A4 A5 A6 /statistics Stddev Variance Range Mean Median Mode /order AnalysisNUR SYAKIRAH BINTI ABD SAMAD MoeNo ratings yet
- IDirect PCMA Enhancing Bandwidth Efficiency in New and Old NetworksDocument17 pagesIDirect PCMA Enhancing Bandwidth Efficiency in New and Old NetworksXiuquan ZhangNo ratings yet
- Frequencies: NotesDocument24 pagesFrequencies: NotesAan Asep SaepudinNo ratings yet
- S. No. Spacve AvalaibleDocument4 pagesS. No. Spacve AvalaibleArnabNo ratings yet
- Praktikum I MatematikaDocument5 pagesPraktikum I MatematikaNurul AiniNo ratings yet
- WORK BOOK 8 - SegmentationDocument12 pagesWORK BOOK 8 - Segmentationakash bathamNo ratings yet
- MoveNet SinglePose Model CardDocument5 pagesMoveNet SinglePose Model CardAki SoraNo ratings yet
- Major ProjectDocument6 pagesMajor Projectgaurav kishoreNo ratings yet
- Head2Head-Atlas GA37 - N37Document1 pageHead2Head-Atlas GA37 - N37abdulfthNo ratings yet
- Kaiser-Meyer-Olkin (KMO)Document5 pagesKaiser-Meyer-Olkin (KMO)fizza amjadNo ratings yet
- File: Tromp Curve - Eng v3 DateDocument9 pagesFile: Tromp Curve - Eng v3 DateMuhammadShoaibNo ratings yet
- Chapter 5Document6 pagesChapter 5SalehNo ratings yet
- AEC 51 Quiz 2 Xavier-Ateneo Mathematics Department Nov 8,2021 Name: Czarina Jane A. PacturanDocument2 pagesAEC 51 Quiz 2 Xavier-Ateneo Mathematics Department Nov 8,2021 Name: Czarina Jane A. PacturanCZARINA JANE ACHUMBRE PACTURANNo ratings yet
- 4.jaw Crasher and Screen AnalysisDocument9 pages4.jaw Crasher and Screen Analysisazzam2 anwrNo ratings yet
- Frequencies: Frequencies Variables Idade /statistics Variance Mean /order AnalysisDocument24 pagesFrequencies: Frequencies Variables Idade /statistics Variance Mean /order AnalysisNique Miguel JoséNo ratings yet
- Final Reduced Cell Name Value GradientDocument7 pagesFinal Reduced Cell Name Value GradientQuỳnh Như VõNo ratings yet
- Group 1 - SPSS ACTIVITYDocument39 pagesGroup 1 - SPSS ACTIVITYKeshia ArutaNo ratings yet
- DIY Kit: Training Neural Networks Artificial Intelligence Applications For ManagersDocument1 pageDIY Kit: Training Neural Networks Artificial Intelligence Applications For ManagersIIMB SumitNo ratings yet
- PLUM - Ordinal Regression: WarningsDocument3 pagesPLUM - Ordinal Regression: WarningsAnastasia WijayaNo ratings yet
- HW3Document14 pagesHW3Dunbar AndersNo ratings yet
- CFM Poster Tri Tien 2023Document1 pageCFM Poster Tri Tien 2023tritienNo ratings yet
- OUTPUTDocument5 pagesOUTPUTAysahhNo ratings yet
- Novogene Amplicon Standard Analysis DEMO REPORTDocument37 pagesNovogene Amplicon Standard Analysis DEMO REPORTludhang100% (1)
- Rev Insurance Business ReportDocument4 pagesRev Insurance Business ReportPratigya pathakNo ratings yet
- 1 s2.0 S2213846322000207 MainDocument4 pages1 s2.0 S2213846322000207 MaindvktrichyNo ratings yet
- MSC (Emec) Computer Modelling and Simulation Module Surveying Comminution CircuitsDocument4 pagesMSC (Emec) Computer Modelling and Simulation Module Surveying Comminution CircuitskediliterapiNo ratings yet
- Survey Project NewDocument21 pagesSurvey Project Newkhoold93No ratings yet
- Practical C2Document11 pagesPractical C2uswah razakNo ratings yet
- Hand-Printed Character Recognizer Using Neural Networks: By: Shahzad Malik (219762)Document9 pagesHand-Printed Character Recognizer Using Neural Networks: By: Shahzad Malik (219762)Waleed KingNo ratings yet
- I. Profile of The Respondents: Table 1.0 Age (Frequency)Document8 pagesI. Profile of The Respondents: Table 1.0 Age (Frequency)Danilo Siquig Jr.No ratings yet
- Quality Tool HistogramDocument1 pageQuality Tool HistogramAlex VincentNo ratings yet
- Output 2Document8 pagesOutput 2Fitria MaharaniNo ratings yet
- Variables You Can Change: Press F9 Key To Update SimulationDocument1 pageVariables You Can Change: Press F9 Key To Update Simulationapi-19921807No ratings yet
- Tugas Sesi 12 - Statistik Bisnis1 - Rintan Fujianti R - 1011119120918Document3 pagesTugas Sesi 12 - Statistik Bisnis1 - Rintan Fujianti R - 1011119120918rintan fujianti rNo ratings yet
- Frequencies: StatisticsDocument17 pagesFrequencies: StatisticsnuradriyaniNo ratings yet
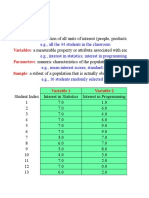
- Population: Variables: Parameters: SampleDocument15 pagesPopulation: Variables: Parameters: SampleAbdu AbdoulayeNo ratings yet
- Project Rev01Document25 pagesProject Rev01mohamed toniNo ratings yet
- AgricolaeDocument89 pagesAgricolaeIwanNo ratings yet
- Adaptive Approximation Based Control: Unifying Neural, Fuzzy and Traditional Adaptive Approximation ApproachesFrom EverandAdaptive Approximation Based Control: Unifying Neural, Fuzzy and Traditional Adaptive Approximation ApproachesRating: 5 out of 5 stars5/5 (1)
- Cpi Odata: Integration FlowDocument12 pagesCpi Odata: Integration Flowsumit thakurNo ratings yet
- Ivan Ozimic CVDocument12 pagesIvan Ozimic CVIvan100% (3)
- Splunk 7.2 Fundamentals Part 2 - CopieDocument359 pagesSplunk 7.2 Fundamentals Part 2 - Copiez2oceceNo ratings yet
- Fundamental Usability Guidelines For User Interface Design: June 2008Document9 pagesFundamental Usability Guidelines For User Interface Design: June 2008Missy PearlNo ratings yet
- Advanced Training On s7 400 PLC & Drive s120Document3 pagesAdvanced Training On s7 400 PLC & Drive s120stlsclNo ratings yet
- As 3522.6-2002 Identification Cards - Recording Technique Magnetic Stripe - High CoercivityDocument8 pagesAs 3522.6-2002 Identification Cards - Recording Technique Magnetic Stripe - High CoercivitySAI Global - APACNo ratings yet
- 1.GSM OverviewDocument46 pages1.GSM OverviewAmit ThakurNo ratings yet
- Powerpoint Presentation DIGITAL LIBRARYDocument12 pagesPowerpoint Presentation DIGITAL LIBRARYANUJA GEORGE100% (3)
- FS-C8025MFP Release NotesDocument22 pagesFS-C8025MFP Release NotesFirmware SM-SHNo ratings yet
- Systems Development and Documentation TechniquesDocument8 pagesSystems Development and Documentation TechniquesNoha KhaledNo ratings yet
- Tutorial Week 2: 1. What Are The Characteristics of A Mobile Computing Environment?Document5 pagesTutorial Week 2: 1. What Are The Characteristics of A Mobile Computing Environment?saneel kumarNo ratings yet
- Sending Data From MSFlexGrid To Excel in VB6 - Visual Basic Tutorials - DreaDocument6 pagesSending Data From MSFlexGrid To Excel in VB6 - Visual Basic Tutorials - DreaJoão Mendes100% (1)
- Crash 5.8.0 (50801847) 20191125 112718Document2 pagesCrash 5.8.0 (50801847) 20191125 112718Jana MuñezNo ratings yet
- Windows 95 ManualDocument111 pagesWindows 95 ManualAlonso CarlosNo ratings yet
- Amadeus Altéa Inventory: Fast Track TrainingDocument15 pagesAmadeus Altéa Inventory: Fast Track TrainingFede GonzalezNo ratings yet
- Lebeitsuk Mattias EplanDocument63 pagesLebeitsuk Mattias EplanAdnan KhanNo ratings yet
- Fifteenth Edition: Enhancing Decision MakingDocument35 pagesFifteenth Edition: Enhancing Decision MakingaaafffNo ratings yet
- Trail Visualization: A Novel System For Monitoring Hiking TrailsDocument8 pagesTrail Visualization: A Novel System For Monitoring Hiking TrailsJessamyn SmallenburgNo ratings yet
- © The Institute of Chartered Accountants of IndiaDocument0 pages© The Institute of Chartered Accountants of IndiaP VenkatesanNo ratings yet
- Computer Applications Technology P2 May-June 2023 EngDocument17 pagesComputer Applications Technology P2 May-June 2023 EngLeeroy Panashe ManyamaziNo ratings yet
- Debugging Guide: Enable InspectorDocument4 pagesDebugging Guide: Enable Inspectorvalle rajendranNo ratings yet
- Gift Card Processors 101Document16 pagesGift Card Processors 101Sharon Janet100% (1)
- Comparison of Pricing Strategy of Apple and SamsungDocument52 pagesComparison of Pricing Strategy of Apple and Samsungsompanda2309No ratings yet
- Datasheet: Truealarm Fire Alarm SystemsDocument2 pagesDatasheet: Truealarm Fire Alarm SystemsIslam AliNo ratings yet
- SALTO - CU42xx Datasheet ENDocument8 pagesSALTO - CU42xx Datasheet ENThasneem YaseenNo ratings yet
- Exercise Chapter 1Document7 pagesExercise Chapter 1Nabil ImanNo ratings yet
- Natural Language Processing NLP and Machine Learning MLTheory and Applications PDFDocument306 pagesNatural Language Processing NLP and Machine Learning MLTheory and Applications PDFAkul MalhotraNo ratings yet
- English Klsaberi Sales+ProposalDocument22 pagesEnglish Klsaberi Sales+ProposalRosario ZapataNo ratings yet
- Pass4sure: Everything You Need To Prepare, Learn & Pass Your Certification Exam EasilyDocument8 pagesPass4sure: Everything You Need To Prepare, Learn & Pass Your Certification Exam Easilysherif adfNo ratings yet