You might also like
- Turban Ch1 Ch6Document167 pagesTurban Ch1 Ch6Pramod Khadka100% (4)
- Udacity Machine Learning Analysis Supervised LearningDocument504 pagesUdacity Machine Learning Analysis Supervised Learningyousef shaban100% (1)
- Homogeneity ISO 13528 2015Document4 pagesHomogeneity ISO 13528 2015khairil ulin nuhaNo ratings yet
- Ife Matrix BoeingDocument5 pagesIfe Matrix BoeingDaniela Peña100% (1)
- Compressible Fluid Flow Calculation MethodsDocument10 pagesCompressible Fluid Flow Calculation Methodsmarco8garciaNo ratings yet
- auto-CREATININE LiquicolorDocument8 pagesauto-CREATININE LiquicolorLemi MaluluNo ratings yet
- Regressing SalaryData PresentationDocument3 pagesRegressing SalaryData PresentationAli Mahgoub Ali TahaNo ratings yet
- Auto-C Liquicolor: Design VerificationDocument9 pagesAuto-C Liquicolor: Design VerificationclaudiaNo ratings yet
- 3ACS11208 Certificate 220618Document2 pages3ACS11208 Certificate 220618Engell CavadaNo ratings yet
- 2014 CE Solving The Pipe Flow CalculationDocument12 pages2014 CE Solving The Pipe Flow CalculationKathia Lorena Espinoza RojasNo ratings yet
- Memo 4Document5 pagesMemo 4api-448664187No ratings yet
- Laporan Praktikum Formulasi Dan Teknologi Sediaan Solida Formulasi Tablet Ibuprofen Metode Granulasi BasahDocument5 pagesLaporan Praktikum Formulasi Dan Teknologi Sediaan Solida Formulasi Tablet Ibuprofen Metode Granulasi BasahiraNo ratings yet
- HPLC New 1Document1 pageHPLC New 1Rafay MirzaNo ratings yet
- Extruder Design and ScalingDocument2 pagesExtruder Design and ScalingasdfesddNo ratings yet
- Project 23Document212 pagesProject 23Dakun PonorogoNo ratings yet
- Kobrina 1977Document5 pagesKobrina 1977mic92833292No ratings yet
- Cloruro FerricoDocument8 pagesCloruro FerricoMario GutiérrezNo ratings yet
- Annexure B - Sucrose Conversion TableDocument21 pagesAnnexure B - Sucrose Conversion TableLim Chen Gin100% (1)
- Solid-Liquid Equilibrium in Binay System: Department of ChemistryDocument11 pagesSolid-Liquid Equilibrium in Binay System: Department of ChemistryLuluaNo ratings yet
- Humastart 100-200 Verification ReportDocument23 pagesHumastart 100-200 Verification ReportruthNo ratings yet
- Practica Calificada Abasteciminento Inga Almonacid DanielDocument4 pagesPractica Calificada Abasteciminento Inga Almonacid DanielCarlo Herbozo PomaNo ratings yet
- Certificate of Analysis: National Institute of Standards & TechnologyDocument4 pagesCertificate of Analysis: National Institute of Standards & Technologymm mmNo ratings yet
- DisplayUnityReportsDocument154 pagesDisplayUnityReportsMarcelo López VarasNo ratings yet
- 55 MicDocument1 page55 MicBayodeNo ratings yet
- Auto Auto Auto Auto-B - D Liquicolor Liquicolor Liquicolor LiquicolorDocument7 pagesAuto Auto Auto Auto-B - D Liquicolor Liquicolor Liquicolor LiquicolorNelson Puita Sandoval100% (1)
- Auto Auto Auto Auto-B - D Liquicolor Liquicolor Liquicolor LiquicolorDocument7 pagesAuto Auto Auto Auto-B - D Liquicolor Liquicolor Liquicolor LiquicolorNelson Puita SandovalNo ratings yet
- ENGINEERING DATA SHEET - AMBERLITE IR120 Na - H SO - RFRDocument2 pagesENGINEERING DATA SHEET - AMBERLITE IR120 Na - H SO - RFRAlgirdas BaranauskasNo ratings yet
- H2 Liquefaction - Cryogenic V14 - HYSYS (Aspentech)Document9 pagesH2 Liquefaction - Cryogenic V14 - HYSYS (Aspentech)Ian MannNo ratings yet
- Acid Base Indicators Lab ReportDocument6 pagesAcid Base Indicators Lab Reportmuskaan0% (2)
- Matrix in ExcelDocument32 pagesMatrix in ExcelAbhijit DharNo ratings yet
- Physical Properties of Toluene: 1. Common DataDocument11 pagesPhysical Properties of Toluene: 1. Common DataPhượng NguyễnNo ratings yet
- Formulation and Optimization of Sublingual Tablet of RamiprilDocument10 pagesFormulation and Optimization of Sublingual Tablet of Ramipril525NORIKO MANUSNo ratings yet
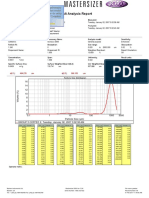
- Result Analysis Report: Um D (0.9) : 966.159 1493.782 D (0.1) : Um Um 464.278 D (0.5)Document1 pageResult Analysis Report: Um D (0.9) : 966.159 1493.782 D (0.1) : Um Um 464.278 D (0.5)Salina ShaffieNo ratings yet
- Universiti Teknologi Mara: Name: Ain Athirah Binti RahimiDocument12 pagesUniversiti Teknologi Mara: Name: Ain Athirah Binti RahimiainrahimiNo ratings yet
- A. Enzyme ConcentrationDocument3 pagesA. Enzyme ConcentrationinshirahizhamNo ratings yet
- Book1 (Recovered)Document5 pagesBook1 (Recovered)AliNo ratings yet
- Shinsuke K Nagano H Yang L 2007Document12 pagesShinsuke K Nagano H Yang L 2007Venu AngirekulaNo ratings yet
- CPMDocument1 pageCPMSN KhairudinNo ratings yet
- Biochemistry Lab Report: VNG - International UniversityDocument19 pagesBiochemistry Lab Report: VNG - International UniversityHà Anh Minh LêNo ratings yet
- Calculation of The Compounds in Portland Cement': Analytical EditionDocument6 pagesCalculation of The Compounds in Portland Cement': Analytical EditionyassinzeNo ratings yet
- Tuesday Group3Document17 pagesTuesday Group3aswzNo ratings yet
- Graph Showing Absorbance Vs Concentration of Dilutions in Measuring Cylinder and Automatic PipetteDocument4 pagesGraph Showing Absorbance Vs Concentration of Dilutions in Measuring Cylinder and Automatic PipetteDonteNo ratings yet
- HP CPM, Ife, Efe & CaDocument8 pagesHP CPM, Ife, Efe & CaSAM50% (2)
- Affinity of LDH LabDocument5 pagesAffinity of LDH LabZoe A GarwoodNo ratings yet
- Experiment 5 AASDocument15 pagesExperiment 5 AASnn bbNo ratings yet
- AnnexesDocument27 pagesAnnexesMeden DoueiminNo ratings yet
- Seminar 1 PDFDocument29 pagesSeminar 1 PDFDiana Andrade LarrañagaNo ratings yet
- Perbandingan R15Document1 pagePerbandingan R15labkurniaNo ratings yet
- CaffeieneDocument8 pagesCaffeieneHawta AbdullaNo ratings yet
- Chemistry Lab ReportDocument9 pagesChemistry Lab Reportlwashaba04No ratings yet
- Perceptual MapDocument5 pagesPerceptual Maproopikarose9No ratings yet
- Lab Report Beer Lambert'S Law Experiment: Determing The Concentration of Unknown Asa SolutionsDocument5 pagesLab Report Beer Lambert'S Law Experiment: Determing The Concentration of Unknown Asa Solutionsumair saleemNo ratings yet
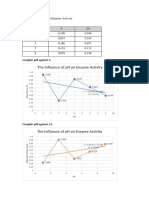
- The Influence of PH On Enzyme Activity: Data in Table FormDocument2 pagesThe Influence of PH On Enzyme Activity: Data in Table FormIrvandar NurviandyNo ratings yet
- The Influence of PH On Enzyme Activity: Data in Table FormDocument2 pagesThe Influence of PH On Enzyme Activity: Data in Table FormputriNo ratings yet
- Computer Applications in FermentationDocument29 pagesComputer Applications in FermentationHrithik BaradiaNo ratings yet
- Su CholDocument9 pagesSu CholTrường Vĩ HuỳnhNo ratings yet
- Tres Curvas PDFDocument1 pageTres Curvas PDFPaulina SalgadoNo ratings yet
- Lab Report AASDocument8 pagesLab Report AASMohamad Saiful Mohd RaffiahNo ratings yet
- Lab 6Document8 pagesLab 6api-3473405070% (1)
- Vaccin 2Document4 pagesVaccin 2زينب عيسىNo ratings yet
- Vaccines Against Components of The Renin-Angiotensin System: Heart Failure Reviews May 2021Document17 pagesVaccines Against Components of The Renin-Angiotensin System: Heart Failure Reviews May 2021زينب عيسىNo ratings yet
- VaccinDocument6 pagesVaccinزينب عيسىNo ratings yet
- 1 s2.0 S2949747723000106 MainDocument11 pages1 s2.0 S2949747723000106 Mainزينب عيسىNo ratings yet
- Detecting and Classifying Fetal Brain Abnormalities Using Decision Tree AlgorithmDocument6 pagesDetecting and Classifying Fetal Brain Abnormalities Using Decision Tree AlgorithmAttah FrancisNo ratings yet
- Machine Learning Lab File (BTCS619-18)Document50 pagesMachine Learning Lab File (BTCS619-18)Ashish Ranjan SinghNo ratings yet
- Decision Tree LearningDocument11 pagesDecision Tree Learningbenjamin212No ratings yet
- Finding Difference Between West and East Yellow Fever by Apriori and Decision TreeDocument8 pagesFinding Difference Between West and East Yellow Fever by Apriori and Decision TreeAnonymous UXBSV13cNo ratings yet
- Data Mining - Docx GhhdocxDocument6 pagesData Mining - Docx GhhdocxSiddharth JainNo ratings yet
- Fast Convert Or-Decision Table To Decision TreeDocument4 pagesFast Convert Or-Decision Table To Decision TreePhaisarn SutheebanjardNo ratings yet
- Final PPT 2Document42 pagesFinal PPT 2Chintu ReddyNo ratings yet
- ml2 PDFDocument5 pagesml2 PDFXYZ ABCNo ratings yet
- Application of Computational Intelligence Technologies in EmergenciesDocument38 pagesApplication of Computational Intelligence Technologies in Emergenciesfelipecaceres5No ratings yet
- ASystematicReview DrMohamedAlloghaniDocument30 pagesASystematicReview DrMohamedAlloghaniFrancisco ArteagaNo ratings yet
- Analysis On Credit Card Fraud Detection MethodsDocument7 pagesAnalysis On Credit Card Fraud Detection MethodsseventhsensegroupNo ratings yet
- 2023-24 AIML ML Mid-Semester Regular QP Anwer-KeysDocument4 pages2023-24 AIML ML Mid-Semester Regular QP Anwer-KeysSabariMurugan SivakumarNo ratings yet
- DMDW NotesDocument62 pagesDMDW NotesJohn William100% (1)
- Artificial Intelligence and Machine Learning - July 2021Document49 pagesArtificial Intelligence and Machine Learning - July 2021arunprasad RNo ratings yet
- Data Mining in CRM: Analytics-Intelligent Management of Product Life CycleDocument40 pagesData Mining in CRM: Analytics-Intelligent Management of Product Life CycleVezoto TheluoNo ratings yet
- CS3491 - Artificial Intelligence and Machine LearningDocument34 pagesCS3491 - Artificial Intelligence and Machine Learningparanjothi karthikNo ratings yet
- Arc Hydro Wetland Identification Model PDFDocument67 pagesArc Hydro Wetland Identification Model PDFrekarancanaNo ratings yet
- Sathyapriya Thesis NEWDocument47 pagesSathyapriya Thesis NEWMukesh LavanNo ratings yet
- Machine Learning 1707965934Document15 pagesMachine Learning 1707965934robson110770No ratings yet
- Solar Radiation Prediction: Dr. Himani BansalDocument43 pagesSolar Radiation Prediction: Dr. Himani BansalHimanshu KesarwaniNo ratings yet
- Weka TutorialDocument2 pagesWeka Tutorialabhishekbehal5012No ratings yet
- Sas Visual Statistics On Sas Viya 108780Document10 pagesSas Visual Statistics On Sas Viya 108780Rocío VázquezNo ratings yet
- Technogeeks Data Science CourseDocument33 pagesTechnogeeks Data Science Courseanjalitech007No ratings yet
- Privacy Preserving On Continuous and Discrete Data Sets - A Novel ApproachDocument7 pagesPrivacy Preserving On Continuous and Discrete Data Sets - A Novel ApproachTania JohnsonNo ratings yet
- CST401-Artificial Intelligence QP May 2023 SolutionDocument10 pagesCST401-Artificial Intelligence QP May 2023 SolutionAnishamolNo ratings yet
- 2012 Network Anomaly Detection by Cascading K-Means Clustering and C4.5 Decision Tree AlgorithmDocument9 pages2012 Network Anomaly Detection by Cascading K-Means Clustering and C4.5 Decision Tree AlgorithmMacLeodNo ratings yet
- PG Certification in Data Science & AI Hyd - EdvancerDocument14 pagesPG Certification in Data Science & AI Hyd - Edvancerdwaraka mayeeNo ratings yet
- Systematic Poisoning Attacks On and Defenses For Machine Learning in HealthcareDocument13 pagesSystematic Poisoning Attacks On and Defenses For Machine Learning in HealthcareAnukul Srivastava100% (2)