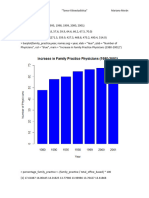
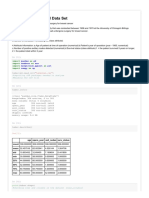
You might also like
- Question 1Document8 pagesQuestion 13madhumatiNo ratings yet
- ML Practical 04Document20 pagesML Practical 04whitehouse2202No ratings yet
- Lecture 5. Part 1 - Regression AnalysisDocument28 pagesLecture 5. Part 1 - Regression AnalysisRichelle PausangNo ratings yet
- Statistics Class Work # 2-1Document8 pagesStatistics Class Work # 2-1dc.yinhelenNo ratings yet
- 4-10 AimlDocument25 pages4-10 AimlGuna SeelanNo ratings yet
- Step-By-Step-Diabetes-Classification-Knn-Detailed-Copy1 - Jupyter NotebookDocument12 pagesStep-By-Step-Diabetes-Classification-Knn-Detailed-Copy1 - Jupyter NotebookElyzaNo ratings yet
- De LARA - Biostat Lab IndivDocument2 pagesDe LARA - Biostat Lab IndiverinNo ratings yet
- Thought ExperimentsDocument52 pagesThought ExperimentsjabbarbaigNo ratings yet
- Nicholas Signorine Week 3 Midterm Exam COH315 Intro To EpidemiologyDocument5 pagesNicholas Signorine Week 3 Midterm Exam COH315 Intro To EpidemiologyFarah FarahNo ratings yet
- Doctors AppointmentDocument34 pagesDoctors Appointmentapi-623968342No ratings yet
- Univariate and Multivariate Analysis - Jupyter NotebookDocument5 pagesUnivariate and Multivariate Analysis - Jupyter NotebookAnuvidyaKarthiNo ratings yet
- Correlation and RegressionDocument24 pagesCorrelation and Regressionkaushalsingh2080% (5)
- Hw2 PrimerDocument10 pagesHw2 PrimerKawyn SomachandraNo ratings yet
- Segmentation ActivityDocument137 pagesSegmentation ActivitySyed ArslanNo ratings yet
- SPSS Module-1Document48 pagesSPSS Module-1nahid mushtaqNo ratings yet
- Pre Assessment Part 2Document5 pagesPre Assessment Part 2Fritzie Denila-VeracityNo ratings yet
- Ide To 6 Classification AlgorithmsDocument34 pagesIde To 6 Classification AlgorithmsAssy GlendaNo ratings yet
- Mean Absolute Deviation WorksheetDocument5 pagesMean Absolute Deviation WorksheettakaniesNo ratings yet
- Salary Age MBA SalaryDocument9 pagesSalary Age MBA Salaryjuri kimNo ratings yet
- Hanson Hfx902 Scales Body Fat Analyser Scale UsermanualDocument7 pagesHanson Hfx902 Scales Body Fat Analyser Scale UsermanualFelipe Videla MuñozNo ratings yet
- SVM - RF - Diabetes - CSV - 26 - 6 - 2023.ipynb - ColaboratoryDocument8 pagesSVM - RF - Diabetes - CSV - 26 - 6 - 2023.ipynb - Colaboratoryutsavarora1912No ratings yet
- Assignment 7Document3 pagesAssignment 7khachadour.bandkNo ratings yet
- Loading The Dataset: 'Diabetes - CSV'Document4 pagesLoading The Dataset: 'Diabetes - CSV'Divyani ChavanNo ratings yet
- ALY6015 Final Project ReportDocument19 pagesALY6015 Final Project ReportLizza Amini GumilarNo ratings yet
- Table 1: Demand Prob Cum Prob RangeDocument10 pagesTable 1: Demand Prob Cum Prob RangePawan SachanNo ratings yet
- Diabetes Prima WekaDocument53 pagesDiabetes Prima Weka'Aamer Anwer Hayat Khan'No ratings yet
- Mean Age Group Analysis: Tables of ComparisonDocument3 pagesMean Age Group Analysis: Tables of ComparisonAnup ChaliseNo ratings yet
- Ujian Akhir Bioslanjut 2013Document8 pagesUjian Akhir Bioslanjut 2013Yasmin AbdullahNo ratings yet
- Key Final Exam 2015 Weight TranslateDocument18 pagesKey Final Exam 2015 Weight Translatetaty jatyNo ratings yet
- Simple and Cross TabulationDocument13 pagesSimple and Cross TabulationAbu BasharNo ratings yet
- Bantilan Maureen Lhee RDocument8 pagesBantilan Maureen Lhee RAlexa Anne Louise BercillaNo ratings yet
- Logistic Regression 205Document8 pagesLogistic Regression 205Ranadeep DeyNo ratings yet
- ExampleProtocol BayesFactorBinaryDocument4 pagesExampleProtocol BayesFactorBinaryAri Surya AbdiNo ratings yet
- Biostatistic LoveDocument9 pagesBiostatistic LoveLove Mie MoreNo ratings yet
- One RDocument3 pagesOne Rketan lakumNo ratings yet
- Tugas Bios3Document2 pagesTugas Bios3Anonymous ir7KQ9fTq4No ratings yet
- Metodologi Penelitian Variabel Data Kel 5 TK 3ADocument16 pagesMetodologi Penelitian Variabel Data Kel 5 TK 3AGendut GendutNo ratings yet
- Paper 1Document11 pagesPaper 1Laith DermoshNo ratings yet
- Diabetic Prediction Using LogicalRegressionDocument9 pagesDiabetic Prediction Using LogicalRegressionYagnesh VyasNo ratings yet
- Assignment 1 (Fuzzzy SystemDocument14 pagesAssignment 1 (Fuzzzy Systemshobanraj1995No ratings yet
- Capstone Project CYODocument11 pagesCapstone Project CYORomina JaramilloNo ratings yet
- Department of Statistics: Course Stats 330Document7 pagesDepartment of Statistics: Course Stats 330PETERNo ratings yet
- Targeted Maximum Likelihood Estimation or TMLE Is A Doubly Robust, Maximum-LikelihoodDocument5 pagesTargeted Maximum Likelihood Estimation or TMLE Is A Doubly Robust, Maximum-LikelihoodMiral Sandipbhai MehtaNo ratings yet
- Homework 9 Solutions: Table (Type)Document6 pagesHomework 9 Solutions: Table (Type)Karthikeyan RNo ratings yet
- ECO1Document9 pagesECO1Himani PasrichaNo ratings yet
- Abas Sittie AlmerahDocument8 pagesAbas Sittie AlmerahAlexa Anne Louise BercillaNo ratings yet
- Graph Project Section 34&35Document5 pagesGraph Project Section 34&35DenreNo ratings yet
- Morán-Pérez - Tarea 4 BStat - 22-02-24Document11 pagesMorán-Pérez - Tarea 4 BStat - 22-02-24MARIANO IVAN MORAN PEREZNo ratings yet
- Subgroup Analysis of Exercise Test Results: 1.1 Treadmill TestingDocument14 pagesSubgroup Analysis of Exercise Test Results: 1.1 Treadmill Testinganon_179117738No ratings yet
- Pset 6 - Fall2019 - Solutions PDFDocument33 pagesPset 6 - Fall2019 - Solutions PDFjoshua arnett100% (3)
- Haberman Data Set Ed ADocument10 pagesHaberman Data Set Ed AVarun AkuthotaNo ratings yet
- 02 Introduction To Statistics JDocument12 pages02 Introduction To Statistics JSagitarius SagitariaNo ratings yet
- ManagementDocument3 pagesManagementNo MoreNo ratings yet
- Nilai Labor Anak NelsonDocument61 pagesNilai Labor Anak NelsonMila AgustiaNo ratings yet
- Supplemental MaterialDocument14 pagesSupplemental Materialtony wNo ratings yet
- GEE and Mixed Models For Longitudinal DataDocument76 pagesGEE and Mixed Models For Longitudinal Dataapocalipsis1999No ratings yet
- Bartolo Renjie Daniel CDocument8 pagesBartolo Renjie Daniel CAlexa Anne Louise BercillaNo ratings yet
- Pre-Final BSAM 116 (Sampling Theory)Document4 pagesPre-Final BSAM 116 (Sampling Theory)Carl DevinNo ratings yet
- STATA IntroDocument123 pagesSTATA Introappnu2dwild0% (1)
- Garbhavastha Me Dekhbhal: Surkshit Matrutv Hetu Upyogi PustakFrom EverandGarbhavastha Me Dekhbhal: Surkshit Matrutv Hetu Upyogi PustakNo ratings yet
- Lymphatic PDFDocument8 pagesLymphatic PDFJoydee Liza MarcoNo ratings yet
- TUGAS 5 B.INGGRIS TigaDocument3 pagesTUGAS 5 B.INGGRIS TigaMesya FauziahNo ratings yet
- Šta Sve (Ne) Znamo O OAD: Prof - DR Dragana Tomić Naglić, Endokrinolog, UKC VojvodinaDocument50 pagesŠta Sve (Ne) Znamo O OAD: Prof - DR Dragana Tomić Naglić, Endokrinolog, UKC VojvodinaNaglic MiroslavNo ratings yet
- Literature ReviewDocument4 pagesLiterature Reviewapi-548908089No ratings yet
- National Arogya Fair: Namma BengaluruDocument2 pagesNational Arogya Fair: Namma BengaluruPrajkta AbnaveNo ratings yet
- Bermuda GrassDocument20 pagesBermuda GrassFurious AssassinNo ratings yet
- Jadavpur University: CollegeDocument22 pagesJadavpur University: CollegekuntaljuNo ratings yet
- Salazar DsDocument4 pagesSalazar DsDjayNo ratings yet
- Brooding ManagementDocument20 pagesBrooding ManagementRonabelle Montojo Villanueva - GumalinggingNo ratings yet
- Dystonia and Its Treatment in Ehlers Danlos SyndromeDocument5 pagesDystonia and Its Treatment in Ehlers Danlos Syndromeannie baiNo ratings yet
- LBW AssignmentDocument2 pagesLBW AssignmentNdungu GitongaNo ratings yet
- I. Nursing Process A. Assessment 1. Personal Data A. Demographic DataDocument6 pagesI. Nursing Process A. Assessment 1. Personal Data A. Demographic DataNicole Anne TungolNo ratings yet
- Acid-Base Balance Study GuideDocument2 pagesAcid-Base Balance Study GuideNoah ClevengerNo ratings yet
- Understanding Low Blood Pressure - The BasicsDocument6 pagesUnderstanding Low Blood Pressure - The BasicsRajeev Nechiyil100% (1)
- General Practitioner - Neurology MCQsDocument20 pagesGeneral Practitioner - Neurology MCQsAsif Newaz100% (3)
- Funeral of Covid PatientsDocument6 pagesFuneral of Covid PatientssalikaabrarNo ratings yet
- Schlueer 2020Document3 pagesSchlueer 2020azhar naufaldiNo ratings yet
- Machine Learning Approach For Acute Respiratory Infections (ISPA) Prediction: Case Study IndonesiaDocument5 pagesMachine Learning Approach For Acute Respiratory Infections (ISPA) Prediction: Case Study IndonesiaSasmita DewiNo ratings yet
- HB SahliDocument10 pagesHB SahliDewi Miranda SaputriNo ratings yet
- UMP Assingement (PRINCIPLES OF SAFETY ENGINEERING)Document15 pagesUMP Assingement (PRINCIPLES OF SAFETY ENGINEERING)Yogendran SundrasaigramNo ratings yet
- I-Clear Ang PiniliDocument21 pagesI-Clear Ang PiniliNurse HoomanNo ratings yet
- Kanker Payudara: Dr. Suyatno SPB (K) Onk Divisi Bedah Onkologi Bagian Bedah FK Usu/Rs Ham MedanDocument72 pagesKanker Payudara: Dr. Suyatno SPB (K) Onk Divisi Bedah Onkologi Bagian Bedah FK Usu/Rs Ham Medandinda annisaNo ratings yet
- Volkmann's Ischemic ContractureDocument41 pagesVolkmann's Ischemic ContractureAayush AryalNo ratings yet
- Radioiodine TherapyDocument5 pagesRadioiodine Therapyaccime24No ratings yet
- Importance of Fever Ebook 2-1Document14 pagesImportance of Fever Ebook 2-1AsmaNo ratings yet
- Legionella Pneumophila in An Ammonia Plant Cooling Tower: W. D. VerduijnDocument15 pagesLegionella Pneumophila in An Ammonia Plant Cooling Tower: W. D. Verduijnvaratharajan g rNo ratings yet
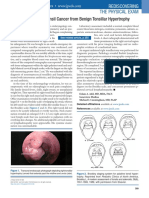
- Differentiating Tonsil Cancer From Benign Tonsillar HypertrophyDocument2 pagesDifferentiating Tonsil Cancer From Benign Tonsillar HypertrophyrinamaulizaNo ratings yet
- Food Control: Dima Faour-Klingbeil, Tareq M. Osaili, Anas A. Al-Nabulsi, Monia Jemni, Ewen C. D. ToddDocument12 pagesFood Control: Dima Faour-Klingbeil, Tareq M. Osaili, Anas A. Al-Nabulsi, Monia Jemni, Ewen C. D. ToddQuoc PhamNo ratings yet
- KefirDocument9 pagesKefirMilliNo ratings yet
- L58 - Mrs. Smita Kad (Saanvi Diagnostics Centre - Pune C Renuka Royal, Shop No-02, Masulkar Colony, Ajmera Colony Road, PIMPARI-41101Document2 pagesL58 - Mrs. Smita Kad (Saanvi Diagnostics Centre - Pune C Renuka Royal, Shop No-02, Masulkar Colony, Ajmera Colony Road, PIMPARI-41101Subham KumarNo ratings yet