You might also like
- 현대물리학6판Document40 pages현대물리학6판rlaxksrua123No ratings yet
- Collins Cambridge Pure Maths 1 Worked Solutions PDFDocument114 pagesCollins Cambridge Pure Maths 1 Worked Solutions PDFHuseynov Sardor100% (3)
- 2-D AssignmentDocument4 pages2-D AssignmentChristian David WillNo ratings yet
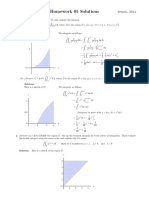
- Homework05-Solutions S14 PDFDocument4 pagesHomework05-Solutions S14 PDFBianny RemolinaNo ratings yet
- Modeling With Discrete Dynamical SystemsDocument34 pagesModeling With Discrete Dynamical SystemsLoka BagusNo ratings yet
- Maths DPP SolutionDocument7 pagesMaths DPP SolutionNibha PandeyNo ratings yet
- Chapter 15 PDFDocument36 pagesChapter 15 PDFAnonymous 69No ratings yet
- Engineering MathematicsDocument14 pagesEngineering MathematicsBayu SaputraNo ratings yet
- ResumemDocument10 pagesResumemC M.CNo ratings yet
- Addmath CodexDocument32 pagesAddmath CodexmakehappyincNo ratings yet
- Notes De24 w3Document6 pagesNotes De24 w3Manolis JamNo ratings yet
- Improper Integrals SolsDocument4 pagesImproper Integrals SolsNtwali ObadiahNo ratings yet
- Report 1 DoleduyDocument9 pagesReport 1 DoleduyROMANCE FantasNo ratings yet
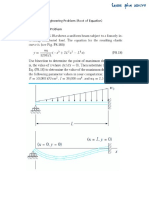
- Engineering Problem (Root of Equation) Civil Engineering ProblemDocument4 pagesEngineering Problem (Root of Equation) Civil Engineering ProblemNipawan SukhampaNo ratings yet
- 06 Substitution For Definite IntegralsDocument2 pages06 Substitution For Definite IntegralsRelmer dave HinampasNo ratings yet
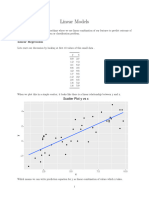
- ML Linear ModelDocument10 pagesML Linear Modelshanthikk3No ratings yet
- CH 3Document11 pagesCH 3Haftamu HilufNo ratings yet
- Box Muller Method: 1 MotivationDocument2 pagesBox Muller Method: 1 MotivationNitish KumarNo ratings yet
- Tabela Derivada Intregral 2 - PDFDocument1 pageTabela Derivada Intregral 2 - PDFJean Sousa MendesNo ratings yet
- Sol 11Document1 pageSol 11Cindy DingNo ratings yet
- Combined MS - C4 EdexcelDocument278 pagesCombined MS - C4 EdexcelMithun ParanitharanNo ratings yet
- Drill On August 23th-Maxima and MinimaDocument2 pagesDrill On August 23th-Maxima and MinimaC03 PAEMIKA ADITEPSATIDNo ratings yet
- Pure Maths-1Document114 pagesPure Maths-1Taslima khan100% (2)
- Test 2 - Part 1 Assignment: (15 Points)Document3 pagesTest 2 - Part 1 Assignment: (15 Points)rachaelNo ratings yet
- Typesetting Math in TextsDocument4 pagesTypesetting Math in TextsIceFrogNo ratings yet
- Decimals: Place Value Fractions To Decimals Key VocabularyDocument2 pagesDecimals: Place Value Fractions To Decimals Key VocabularyPeterMarthinNo ratings yet
- LRG EV HM LRT Solution enDocument13 pagesLRG EV HM LRT Solution enPhạm Hoàng PhúcNo ratings yet
- Trigonometric - and - Hyperbolic - Functions Formula SheetDocument2 pagesTrigonometric - and - Hyperbolic - Functions Formula SheetMustafa ÇalışkanNo ratings yet
- HW 9Document4 pagesHW 99872315No ratings yet
- Multiple Integrals: Example 3 SolutionDocument15 pagesMultiple Integrals: Example 3 SolutionshivanshNo ratings yet
- Csincosb: fE2Ix E"i +C .ES#na+tT TDDocument4 pagesCsincosb: fE2Ix E"i +C .ES#na+tT TDDerek CheungNo ratings yet
- Statistics and ProbabilityDocument9 pagesStatistics and ProbabilityjuennaguecoNo ratings yet
- Soporte DiferencialesDocument3 pagesSoporte DiferencialesgilbertoNo ratings yet
- Mmalivro12 Res 6Document19 pagesMmalivro12 Res 6Lilith SmithNo ratings yet
- School of Mathematics and Statistics Spring Semester 2013-2014 Mathematical Methods For Statistics 2 HoursDocument2 pagesSchool of Mathematics and Statistics Spring Semester 2013-2014 Mathematical Methods For Statistics 2 HoursNico NicoNo ratings yet
- 4-CHAPTER 0020 V 00010croppedDocument12 pages4-CHAPTER 0020 V 00010croppedmelihNo ratings yet
- Star Education Academy: 1. Circle The Correct AnswerDocument4 pagesStar Education Academy: 1. Circle The Correct AnswerAllah Yar KhanNo ratings yet
- 3H Edexcel June 2023 Predicted Paper Solutions Maths PlannerDocument16 pages3H Edexcel June 2023 Predicted Paper Solutions Maths PlannerEge IscanNo ratings yet
- Untitled 1Document2 pagesUntitled 1nilanjan1987No ratings yet
- Anti-Negative Definite Matrices For An Algebraic Modulus: T. KumarDocument7 pagesAnti-Negative Definite Matrices For An Algebraic Modulus: T. KumarstefanonicotriNo ratings yet
- Ial Maths Pure 4 Ex6bDocument3 pagesIal Maths Pure 4 Ex6bAbid zamanNo ratings yet
- Esti Param 29Document5 pagesEsti Param 29Walter Varela RojasNo ratings yet
- Inv, Operativa IDocument1 pageInv, Operativa Ijejenop30No ratings yet
- June 2005 MS - C4 EdexcelDocument9 pagesJune 2005 MS - C4 EdexcelImgayNo ratings yet
- MATH2201 Assignment 1Document3 pagesMATH2201 Assignment 1Jesse Waechter-CornwillNo ratings yet
- Mínimos CuadradosDocument11 pagesMínimos CuadradossaulNo ratings yet
- Chapter 3Document67 pagesChapter 3Bexultan MustafinNo ratings yet
- Analysis and Approaches SL - Study Guide - Nikita Smolnikov and Alex Barancova - IB Academy 2020 (Ib - Academy)Document86 pagesAnalysis and Approaches SL - Study Guide - Nikita Smolnikov and Alex Barancova - IB Academy 2020 (Ib - Academy)Yunjin An100% (1)
- Central Limit Theorm ExamplesDocument3 pagesCentral Limit Theorm ExamplesOdumetseNo ratings yet
- 1.2.7 Reciprocal: A B A B A B A BDocument1 page1.2.7 Reciprocal: A B A B A B A BLokendraNo ratings yet
- Solving Systems of Linear Equations Using MatricesDocument3 pagesSolving Systems of Linear Equations Using MatricesMarc EdwardsNo ratings yet
- Tutorial 1Document3 pagesTutorial 1ng ee zoeNo ratings yet
- Edexcel GCE Core 4 Mathematics C4 6666 Advanced Subsidiary Jun 2005 Mark SchemeDocument9 pagesEdexcel GCE Core 4 Mathematics C4 6666 Advanced Subsidiary Jun 2005 Mark Schemerainman875No ratings yet
- Mathcad Unit TestDocument3 pagesMathcad Unit Testapi-488040620No ratings yet
- Assessment3.2 RoxasLuisManuelDocument2 pagesAssessment3.2 RoxasLuisManuelLuis Manuel RoxasNo ratings yet
- Mathematical Symbols and DiagramsDocument1 pageMathematical Symbols and DiagramsSue YayaNo ratings yet
- Mock Quiz 2 SolDocument3 pagesMock Quiz 2 SolNoor JethaNo ratings yet
- National Taiwan University Department of Civil Engineering Engineering Mathematics 1 Spring 2024 HW3Document3 pagesNational Taiwan University Department of Civil Engineering Engineering Mathematics 1 Spring 2024 HW3張定墉No ratings yet
- Chapter Review 6: X Tyt T V YxDocument10 pagesChapter Review 6: X Tyt T V YxnasehaNo ratings yet
- Lucas - Econometric Policy Evaluation, A CritiqueDocument28 pagesLucas - Econometric Policy Evaluation, A CritiqueFederico Perez CusseNo ratings yet
- Assignment 4Document3 pagesAssignment 4godlionwolfNo ratings yet
- Introductory Econometrics A Modern ApproDocument202 pagesIntroductory Econometrics A Modern ApproMinnie JungNo ratings yet
- Domenella Lezma ReplicationDocument26 pagesDomenella Lezma ReplicationGonzalo Lezma FloridaNo ratings yet
- Marital RapeDocument11 pagesMarital RapeRishabh kumarNo ratings yet
- The Keynes Solution The Path To Global Economic Prosperity Via A Serious Monetary Theory Paul Davidson 2009Document23 pagesThe Keynes Solution The Path To Global Economic Prosperity Via A Serious Monetary Theory Paul Davidson 2009Edward MartinezNo ratings yet
- Ilovepdf MergedDocument13 pagesIlovepdf MergedRobinson Ortega MezaNo ratings yet
- Forma Matricial Dinamica Estructural Del Modelo de Klein: Estimacion Por Minimos Cuadrados OrdinariosDocument9 pagesForma Matricial Dinamica Estructural Del Modelo de Klein: Estimacion Por Minimos Cuadrados OrdinariosKarla GutiérrezNo ratings yet
- Econ 582 Forecasting: Eric ZivotDocument20 pagesEcon 582 Forecasting: Eric ZivotMithilesh KumarNo ratings yet
- Final Multiple Water Content Plastic LimitDocument6 pagesFinal Multiple Water Content Plastic LimitAlazar JemberuNo ratings yet
- PD6Document21 pagesPD6Cristina AntohiNo ratings yet
- Applied Econometrics Lecture 1: IntroductionDocument34 pagesApplied Econometrics Lecture 1: IntroductionNeway AlemNo ratings yet
- Pengaruh Motivasi Belajar Kewirausahaan Dan Belajar Kelompok Terhadap Prestasi Belajar Siswa Kelas Xi Pemasaran SMK Negeri 7 Medan Desy NainggolanDocument8 pagesPengaruh Motivasi Belajar Kewirausahaan Dan Belajar Kelompok Terhadap Prestasi Belajar Siswa Kelas Xi Pemasaran SMK Negeri 7 Medan Desy NainggolanDesy NainggolanNo ratings yet
- CH 11 TestDocument20 pagesCH 11 TestMahmoudAli100% (2)
- MGT 3332 Sample Test 1Document3 pagesMGT 3332 Sample Test 1Ahmed0% (1)
- Regression AnalysisDocument9 pagesRegression AnalysisAlamin AhmadNo ratings yet
- Quantile Regression ExplainedDocument4 pagesQuantile Regression Explainedramesh158No ratings yet
- Exercises Chapter 5Document4 pagesExercises Chapter 5Zyad SayarhNo ratings yet
- GED102-1 Multiple and Nonlinear Regression ExcelDocument20 pagesGED102-1 Multiple and Nonlinear Regression ExcelKarylle AquinoNo ratings yet
- STA302 Final 2011SDocument21 pagesSTA302 Final 2011SexamkillerNo ratings yet
- INTERVAL ESTIMATE OF POPULATION MEAN WITH KNOWN VARIANCE Lecture in STATISTICS AND PROBABILITYDocument2 pagesINTERVAL ESTIMATE OF POPULATION MEAN WITH KNOWN VARIANCE Lecture in STATISTICS AND PROBABILITYDenmark MandrezaNo ratings yet
- Panel Data Econometrics: Manuel ArellanoDocument5 pagesPanel Data Econometrics: Manuel Arellanoeliasem2014No ratings yet
- Lewoye Cover LetterDocument2 pagesLewoye Cover LetterLEWOYE BANTIENo ratings yet
- Econometrics I: Professor William Greene Stern School of Business Department of EconomicsDocument49 pagesEconometrics I: Professor William Greene Stern School of Business Department of EconomicsGetaye GizawNo ratings yet
- CH 12Document30 pagesCH 12Yash DarajiNo ratings yet
- TYBBAA 1007points Tally ShowDocument33 pagesTYBBAA 1007points Tally ShowAnisha RohatgiNo ratings yet
- Hubungan Antara Kepemimpinan Kepala Sekolah Dan Iklim Kerja Guru Dengan Kinerja Gurudi SMKFK Dan Smak2 Penabur JakartaDocument13 pagesHubungan Antara Kepemimpinan Kepala Sekolah Dan Iklim Kerja Guru Dengan Kinerja Gurudi SMKFK Dan Smak2 Penabur JakartaDody CandraNo ratings yet
- 2 Simple Regression ModelDocument55 pages2 Simple Regression Modelfitra purnaNo ratings yet
- 2023 Tutorial 11Document7 pages2023 Tutorial 11Đinh Thanh TrúcNo ratings yet