You might also like
- AIML Report.Document12 pagesAIML Report.Suma T KNo ratings yet
- I Avaliação Parcial - 25.0 PTS - GabaritoDocument9 pagesI Avaliação Parcial - 25.0 PTS - GabaritoPedro CarvalhoNo ratings yet
- 4-10 AimlDocument25 pages4-10 AimlGuna SeelanNo ratings yet
- ML Data Preprocessing in PythonDocument9 pagesML Data Preprocessing in PythonFathoni MahardikaNo ratings yet
- Logistic - Ipynb - ColaboratoryDocument6 pagesLogistic - Ipynb - ColaboratoryAkansha UniyalNo ratings yet
- Data Mining Assignment No. 1Document7 pagesData Mining Assignment No. 1Saamia ANo ratings yet
- Au953721103009 FontDocument26 pagesAu953721103009 Fonttommyshelby.gr1No ratings yet
- SC Lab File Fayiz PDFDocument29 pagesSC Lab File Fayiz PDFfayizpNo ratings yet
- ML0101EN Clas Logistic Reg Churn Py v1Document13 pagesML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- Here's An Visualization of The K-Nearest Neighbors AlgorithmDocument5 pagesHere's An Visualization of The K-Nearest Neighbors Algorithmakif barbaros dikmenNo ratings yet
- Your First Neural NetworkDocument15 pagesYour First Neural NetworkUna Si NdésoNo ratings yet
- Code ExerciseModelSelectionDocument19 pagesCode ExerciseModelSelectionaimen.nsiali100% (1)
- Scikit Learn What Were CoveringDocument15 pagesScikit Learn What Were CoveringRaiyan ZannatNo ratings yet
- Tugas Clustering - 132021012 - Kevin Gazkia NaufalDocument6 pagesTugas Clustering - 132021012 - Kevin Gazkia NaufalkevinNo ratings yet
- Diabetes Case Study - Jupyter NotebookDocument10 pagesDiabetes Case Study - Jupyter NotebookAbhising100% (1)
- Classification 4Document1 pageClassification 4Elisée TEGUENo ratings yet
- Heart Disease Prediction - Jupyter NotebookDocument9 pagesHeart Disease Prediction - Jupyter Notebookkavya100% (1)
- Kunal DSDocument92 pagesKunal DSVipul GuptaNo ratings yet
- Iot Lab 5Document4 pagesIot Lab 5Rahul JainNo ratings yet
- XSTK Câu hỏiDocument19 pagesXSTK Câu hỏiimaboneofmyswordNo ratings yet
- utf-8''C2M1 AssignmentDocument24 pagesutf-8''C2M1 AssignmentSarah MendesNo ratings yet
- Business Report: by Sreenath RadhakrishnanDocument26 pagesBusiness Report: by Sreenath RadhakrishnanSonal SinghNo ratings yet
- Maxbox - Starter67 Machine LearningDocument7 pagesMaxbox - Starter67 Machine LearningMax KleinerNo ratings yet
- 20it113 Logisticregression MLDocument14 pages20it113 Logisticregression ML555 FFNo ratings yet
- Ex No 5Document10 pagesEx No 5Robert LoitongbamNo ratings yet
- 1 Lecture 2: Supervised Machine LearningDocument20 pages1 Lecture 2: Supervised Machine LearningJeremy WangNo ratings yet
- Sajjad DSDocument97 pagesSajjad DSHey Buddy100% (2)
- Heart Failure PredictionDocument24 pagesHeart Failure PredictionritubajajNo ratings yet
- Week 7 Laboratory ActivityDocument12 pagesWeek 7 Laboratory ActivityGar NoobNo ratings yet
- (3.12) Exercise:: ObservationDocument1 page(3.12) Exercise:: ObservationSam ShankarNo ratings yet
- ML Practical FileDocument43 pagesML Practical FilePankaj Singh100% (1)
- Practical - 5 - 52Document4 pagesPractical - 5 - 52Royal EmpireNo ratings yet
- ML 7Document6 pagesML 7pratikn1406No ratings yet
- Meaningful Predictive Modeling Week-4 Assignment Cancer Disease PredictionDocument6 pagesMeaningful Predictive Modeling Week-4 Assignment Cancer Disease PredictionfrankhNo ratings yet
- Image Classification Using Backpropagation Neural Network Without Using Built-In FunctionDocument8 pagesImage Classification Using Backpropagation Neural Network Without Using Built-In FunctionMaisha MashiataNo ratings yet
- PythonfileDocument36 pagesPythonfilecollection58209No ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- Procedure GLMDocument37 pagesProcedure GLMMauricio González PalacioNo ratings yet
- Tutorial 1 - RegressionDocument6 pagesTutorial 1 - RegressionAnwar ZainuddinNo ratings yet
- Tugas Akhir Big DataDocument10 pagesTugas Akhir Big DataSaskya LidayaniNo ratings yet
- Hw2 PrimerDocument10 pagesHw2 PrimerKawyn SomachandraNo ratings yet
- GNN 01 IntroDocument8 pagesGNN 01 IntrovitormeriatNo ratings yet
- Chapter4 PDFDocument34 pagesChapter4 PDFHana BananaNo ratings yet
- DM Slip SolutionsDocument24 pagesDM Slip Solutions09.Khadija Gharatkar100% (1)
- ML Practical 04Document20 pagesML Practical 04whitehouse2202No ratings yet
- Data MiningDocument37 pagesData MiningSai Saamrudh SaiganeshNo ratings yet
- Analyzing IoT Data in Python Chapter4Document34 pagesAnalyzing IoT Data in Python Chapter4FgpeqwNo ratings yet
- Stats Practical WJCDocument23 pagesStats Practical WJCBhuvanesh SriniNo ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- Credit Card Fraud DetectionDocument20 pagesCredit Card Fraud DetectionVishal Sharma100% (1)
- An Application of Anns To Human Action Recognition Based On Limbs' DataDocument4 pagesAn Application of Anns To Human Action Recognition Based On Limbs' DataMyagmarbayar NerguiNo ratings yet
- Confidence Interval and Hypothesis TestingDocument1 pageConfidence Interval and Hypothesis TestingChetan TemkarNo ratings yet
- Introduction To Decision Tree: Gini IndexDocument15 pagesIntroduction To Decision Tree: Gini IndexMUhammad WaqasNo ratings yet
- Clustering Approach in Diabetes Dataset: Submitted By: Submitted To: Dr. Mridu SahuDocument20 pagesClustering Approach in Diabetes Dataset: Submitted By: Submitted To: Dr. Mridu SahuPriyank KulshresthaNo ratings yet
- Retinal Blood VesselDocument14 pagesRetinal Blood VesselGourab PalNo ratings yet
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- Introduction To Population PKDocument45 pagesIntroduction To Population PKTran Nhat ThangNo ratings yet
- Machine Learning Lab Manual 06Document8 pagesMachine Learning Lab Manual 06Raheel Aslam100% (1)
- Maxbox Starter66 Machine Learning4Document10 pagesMaxbox Starter66 Machine Learning4Max KleinerNo ratings yet
- Hospital ErDocument1 pageHospital Ersumatksumatk5No ratings yet
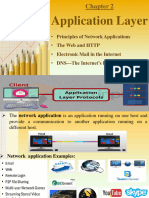
- Application LayerDocument62 pagesApplication Layersumatksumatk5No ratings yet
- SyllabusDocument27 pagesSyllabussumatksumatk5No ratings yet
- Cs AimlDocument3 pagesCs Aimlsumatksumatk5No ratings yet
- Aiml SeminorDocument5 pagesAiml Seminorsumatksumatk5No ratings yet
- Aiml Report757Document8 pagesAiml Report757sumatksumatk5No ratings yet
- Aiml Seminor757Document13 pagesAiml Seminor757sumatksumatk5No ratings yet
- Contemporary Management of Major Haemorrhage in Critical CareDocument13 pagesContemporary Management of Major Haemorrhage in Critical CareYo MeNo ratings yet
- Milk Supply Chain Management Upstream Downstream IssuesDocument25 pagesMilk Supply Chain Management Upstream Downstream IssuesbikramNo ratings yet
- Jurnal BM 7Document18 pagesJurnal BM 7Nitya WirasasiNo ratings yet
- Statement of PurposeDocument5 pagesStatement of PurposesagvekarpoojaNo ratings yet
- Anaemia in Pregnancy: Dr. Lama MehaisenDocument11 pagesAnaemia in Pregnancy: Dr. Lama MehaisenWendy EvansNo ratings yet
- EffectiveTeaching Full ManualDocument340 pagesEffectiveTeaching Full ManualHabtamu AdimasuNo ratings yet
- Biocontrol in Disease SugarcaneDocument11 pagesBiocontrol in Disease SugarcaneAlbar ConejoNo ratings yet
- CFPC SampsDocument39 pagesCFPC SampsSumer Chauhan100% (9)
- The Health Promotion Model (Nola J. Pender) : SupratmanDocument11 pagesThe Health Promotion Model (Nola J. Pender) : SupratmanNugraha PratamaNo ratings yet
- Cigna SmartCare Helpful GuideDocument42 pagesCigna SmartCare Helpful GuideFasihNo ratings yet
- Banner AT FM 10k PDFDocument14 pagesBanner AT FM 10k PDFDamian RamosNo ratings yet
- Risk Assessment Questions and Answers 1624351390Document278 pagesRisk Assessment Questions and Answers 1624351390Firman Setiawan100% (1)
- IEEE Guide To The Assembly and Erection of Concrete Pole StructuresDocument32 pagesIEEE Guide To The Assembly and Erection of Concrete Pole Structuresalex aedoNo ratings yet
- Karakteristik Penderita Mioma Uteri Di Rsup Prof. Dr. R.D. Kandou ManadoDocument6 pagesKarakteristik Penderita Mioma Uteri Di Rsup Prof. Dr. R.D. Kandou ManadoIsma RotinNo ratings yet
- Homeopathic Remedy Pictures Alexander Gothe Julia Drinnenberg.04000 1Document6 pagesHomeopathic Remedy Pictures Alexander Gothe Julia Drinnenberg.04000 1BhargavaNo ratings yet
- Zollinger-Ellison Syndrome (Gastrinoma)Document15 pagesZollinger-Ellison Syndrome (Gastrinoma)Huy QuangNo ratings yet
- Burdock Root AeroponicDocument8 pagesBurdock Root AeroponicNelson RiddleNo ratings yet
- Adoption LawsDocument10 pagesAdoption LawsAneesh PandeyNo ratings yet
- Food Data Chart - ZincDocument6 pagesFood Data Chart - Zinctravi95No ratings yet
- Cleaning Reusable Medical DevicesDocument12 pagesCleaning Reusable Medical DevicesDavid Olamendi ColinNo ratings yet
- Sistem Pakar Diagnosis Penyakit Pada Ayam Dengan Menggunakan Metode Dempster ShaferDocument11 pagesSistem Pakar Diagnosis Penyakit Pada Ayam Dengan Menggunakan Metode Dempster ShaferYata RinNo ratings yet
- Regulatory Compliance Planning GuideDocument70 pagesRegulatory Compliance Planning GuideriestgNo ratings yet
- 33 Pol BRF Food Models enDocument36 pages33 Pol BRF Food Models enthuyetnnNo ratings yet
- 1 s2.0 S2667368123000116 MainDocument24 pages1 s2.0 S2667368123000116 MainCelia MartinezNo ratings yet
- Excerpt From Treating Trauma-Related DissociationDocument14 pagesExcerpt From Treating Trauma-Related DissociationNortonMentalHealth100% (3)
- Questionnaire For Stress Management in An OrganizationDocument8 pagesQuestionnaire For Stress Management in An OrganizationTapassya Giri33% (3)
- Abs & Core Workout Calendar - Mar 2020Document1 pageAbs & Core Workout Calendar - Mar 2020Claudia anahiNo ratings yet
- SOP Receiving and Storage of Raw MaterialsDocument2 pagesSOP Receiving and Storage of Raw MaterialsBadethdeth1290% (10)
- Lüscher Colour TestDocument1 pageLüscher Colour TestVicente Sebastián Márquez LecarosNo ratings yet