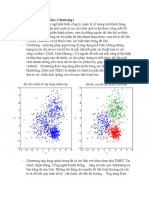
You might also like
- Bài mẫu khai phá 2Document27 pagesBài mẫu khai phá 2nguyenanhbim6No ratings yet
- Data AnalysisDocument11 pagesData AnalysisVan AnhNo ratings yet
- KPDLDocument19 pagesKPDLVũ MạnhNo ratings yet
- Khai phá dữ liệuDocument44 pagesKhai phá dữ liệucute panda channelNo ratings yet
- Tieu Luan KHDL-Nhom 5Document50 pagesTieu Luan KHDL-Nhom 5Nguyễn Đức MinhNo ratings yet
- TỔNG QUAN VỀ KHAI PHÁ DỮ LIỆUDocument23 pagesTỔNG QUAN VỀ KHAI PHÁ DỮ LIỆUNC musicNo ratings yet
- NHÓM 7 Bài tập lớp nlsud năm nhất hvnhDocument31 pagesNHÓM 7 Bài tập lớp nlsud năm nhất hvnhroyalhieu1109No ratings yet
- KHDLDocument45 pagesKHDLduyNo ratings yet
- Phân Tích Tình Hình Tài Chính Công Ty Hoà PhátDocument35 pagesPhân Tích Tình Hình Tài Chính Công Ty Hoà Phátk60.2114210033No ratings yet
- Tailieuxanh Tieu Luan Datamining 3908Document27 pagesTailieuxanh Tieu Luan Datamining 3908HẠNH CAO THỊ MỸNo ratings yet
- KPDL DiamondDocument20 pagesKPDL DiamondThi Xuan Rin LeNo ratings yet
- CSDL Giua KiDocument17 pagesCSDL Giua Kitranquangdatt67No ratings yet
- KHDL Nhóm 5Document18 pagesKHDL Nhóm 5THU NGUYỄN THỊ NGỌCNo ratings yet
- Trường Đại Học Kinh Tế Tp.Hcm: Bộ Giáo Dục Và Đào TạoDocument25 pagesTrường Đại Học Kinh Tế Tp.Hcm: Bộ Giáo Dục Và Đào TạoHIEN TRAN THI THUNo ratings yet
- PhamQuangTrung TranQuangDuy KhaiphadulieuDocument24 pagesPhamQuangTrung TranQuangDuy KhaiphadulieuDuy Tran100% (1)
- Báo Cáo HTTT 1Document18 pagesBáo Cáo HTTT 1Phan HiềnNo ratings yet
- KhaiphadulieuDocument16 pagesKhaiphadulieuKhoa LeeNo ratings yet
- Baitapbuoi 1Document5 pagesBaitapbuoi 1shark fizzNo ratings yet
- Nhóm 5 - Đồ Án Môn HọcDocument84 pagesNhóm 5 - Đồ Án Môn HọcNguyễn Thanh TrangNo ratings yet
- Thuật toán k-Means và cách cài đặtDocument22 pagesThuật toán k-Means và cách cài đặtThu ThyNo ratings yet
- Đại Học Kinh Tế Thành Phố Hồ Chí Minh Khoa Công Nghệ Thông Tin Kinh DoanhDocument41 pagesĐại Học Kinh Tế Thành Phố Hồ Chí Minh Khoa Công Nghệ Thông Tin Kinh Doanhngocho.31221023786No ratings yet
- Nghien Cuu Data Mining Trong Microsoft Server 2005 Voi Thuat Toan Microsoft Association Rules Va Microsoft Decision TreeDocument82 pagesNghien Cuu Data Mining Trong Microsoft Server 2005 Voi Thuat Toan Microsoft Association Rules Va Microsoft Decision TreeMinh HoaNo ratings yet
- 1. Phân Cụm Dữ Liệu (Clustering)Document10 pages1. Phân Cụm Dữ Liệu (Clustering)TiếnNo ratings yet
- Báo Cáo MiningDocument33 pagesBáo Cáo MiningViệt AnhNo ratings yet
- Báo cáo khai phá dữ liệuDocument24 pagesBáo cáo khai phá dữ liệuSARA TV100% (1)
- KTL BTL FinalDocument18 pagesKTL BTL FinalAdam LuyenNo ratings yet
- 74779-Điều văn bản-180407-1-10-20221221Document9 pages74779-Điều văn bản-180407-1-10-20221221Nguyễn Văn Quân - D16HTTMDTNo ratings yet
- QT CSDL KDDocument233 pagesQT CSDL KDToàn Phạm VănNo ratings yet
- TL WordDocument39 pagesTL WordHảo Thái QuangNo ratings yet
- NLSUD Nhóm 7Document25 pagesNLSUD Nhóm 7royalhieu1109No ratings yet
- Paper 6 PPDocument42 pagesPaper 6 PPthuthuNo ratings yet
- Nhóm 14 - Báo Cáo Nhóm - Kho DL Và KDTMDocument44 pagesNhóm 14 - Báo Cáo Nhóm - Kho DL Và KDTMHuệ PhạmNo ratings yet
- Bài Báo CáoDocument4 pagesBài Báo Cáothuongtran20199No ratings yet
- KHDL 20230224 211657Document55 pagesKHDL 20230224 211657khoapham04092003No ratings yet
- HỆ THỐNG CƠ SỞ DỮ LIỆU VÀ SIÊU DỮ LIỆUDocument12 pagesHỆ THỐNG CƠ SỞ DỮ LIỆU VÀ SIÊU DỮ LIỆUHuyen NgocNo ratings yet
- DataMining - Chuong 2Document14 pagesDataMining - Chuong 2Ngọc Liên LêNo ratings yet
- Data Warehouse-Nhom 7Document33 pagesData Warehouse-Nhom 7Sương GiangNo ratings yet
- Nhóm 7 BigData03Document14 pagesNhóm 7 BigData0317- Nguyễn Yến ChiNo ratings yet
- Nhóm 6-Cơ Sở Dữ Liệu Trong Quản Lí Kinh DoanhDocument4 pagesNhóm 6-Cơ Sở Dữ Liệu Trong Quản Lí Kinh DoanhKhông Muốn Đi HọcNo ratings yet
- Chuyên đề CNTTDocument46 pagesChuyên đề CNTTdomanhson2608No ratings yet
- Bài Tập Lớn Phân Tích Thiết Kế Hệ Thống Lê Duy Tiến 520CNT1034Document25 pagesBài Tập Lớn Phân Tích Thiết Kế Hệ Thống Lê Duy Tiến 520CNT1034leduytien262No ratings yet
- DỮ LIỆU LỚN TRONG KINH TẾ VÀ KINH DOANHDocument11 pagesDỮ LIỆU LỚN TRONG KINH TẾ VÀ KINH DOANHNgọc Anh BùiNo ratings yet
- Dự Án KHDLDocument18 pagesDự Án KHDLNHI NGUYỄN THỊ YẾNNo ratings yet
- Khai Pha-1Document29 pagesKhai Pha-1Pham Van MinhNo ratings yet
- Báo Cáo MiningDocument34 pagesBáo Cáo MiningBảo Anh DươngNo ratings yet
- Giao Trinh Khai Thac Du Lieu DHGTVTDocument14 pagesGiao Trinh Khai Thac Du Lieu DHGTVTĐen CừuNo ratings yet
- Bài Tiểu Luận NhómDocument23 pagesBài Tiểu Luận NhómThanh Ngân Phạm LêNo ratings yet
- Nguyễn Quỳnh PhươngDocument8 pagesNguyễn Quỳnh PhươngĐáng iu BốngNo ratings yet
- KHDL - NHÓM 3 - HỆ THỐNG SIÊU THỊ HÀNG TIÊU DÙNGDocument18 pagesKHDL - NHÓM 3 - HỆ THỐNG SIÊU THỊ HÀNG TIÊU DÙNGHạ Phạm NhậtNo ratings yet
- Big Data 09 ĐHCNTT03 Nhóm7Document44 pagesBig Data 09 ĐHCNTT03 Nhóm7Kio ZenxNo ratings yet
- Bai Tap TH THQL - Phan WordDocument6 pagesBai Tap TH THQL - Phan WordVũ Công TuyềnNo ratings yet
- BaocaoDocument14 pagesBaocaoAn TrầnNo ratings yet
- ĐỀ TÀI: Thuật toán K-mean và ứng dụng vào bài toán phân lớp đối tượng khách hàng trong kinh doanhDocument19 pagesĐỀ TÀI: Thuật toán K-mean và ứng dụng vào bài toán phân lớp đối tượng khách hàng trong kinh doanhphamchauanh125No ratings yet
- Tai Lieu NCKH NC - KHOA NANG CAODocument48 pagesTai Lieu NCKH NC - KHOA NANG CAODương NguyễnNo ratings yet
- BT Buổi 1Document3 pagesBT Buổi 1Trần MNgọcNo ratings yet
- đề án python nhóm 7Document48 pagesđề án python nhóm 7Kio ZenxNo ratings yet
- - Hoàng Ngọc ThànhDocument32 pages- Hoàng Ngọc ThànhThành HoàngNo ratings yet
- Bài Tập Lớn Kết Thúc Học Phần Khai Phá Dữ LiệuDocument22 pagesBài Tập Lớn Kết Thúc Học Phần Khai Phá Dữ LiệuTam Nguyen ThiNo ratings yet
- BCKH - Phân tích dữ liệu và tương lai của ngành trong kỷ nguyên sốDocument12 pagesBCKH - Phân tích dữ liệu và tương lai của ngành trong kỷ nguyên sốĐặng TrangNo ratings yet
- D Báo Trong Kinh DoanhDocument6 pagesD Báo Trong Kinh DoanhNhư Ý Đặng VạnNo ratings yet
- TÓM TẮT ND QTNLDocument2 pagesTÓM TẮT ND QTNLNhư Ý Đặng VạnNo ratings yet
- HTTTQLDocument1 pageHTTTQLNhư Ý Đặng VạnNo ratings yet
- BlockchainDocument2 pagesBlockchainNhư Ý Đặng VạnNo ratings yet
- Xay Dung Va Quan Tri He Thong Web Server Tren LinuxDocument72 pagesXay Dung Va Quan Tri He Thong Web Server Tren LinuxNhư Ý Đặng VạnNo ratings yet
- Báo cáo tiểu luận QTDADocument32 pagesBáo cáo tiểu luận QTDANhư Ý Đặng VạnNo ratings yet
- Vấn đề của hệ thống thông tin của công ty PNJDocument28 pagesVấn đề của hệ thống thông tin của công ty PNJNhư Ý Đặng Vạn100% (1)
- Bài Làm KTLDocument6 pagesBài Làm KTLNhư Ý Đặng VạnNo ratings yet