DeepSeek-V2: High-Performing Open-Source LLM With MoE Architecture
Uploaded by
My SocialDeepSeek-V2: High-Performing Open-Source LLM With MoE Architecture
Uploaded by
My SocialTo read more such articles, please visit our blog [Link]
com/
DeepSeek-V2: High-Performing Open-Source LLM with MoE
Architecture
Introduction
The evolution of artificial intelligence (AI) has been marked by significant
milestones, with language models playing a crucial role in this journey.
Among these models, the Mixture-of-Experts (MoE) language models
have emerged as a game-changer. The concept of MoE, which
originated in 1991, involves a system of separate networks, each
specializing in a different subset of training cases. This unique approach
has led to substantial improvements in model performance and
efficiency, pushing the boundaries of what’s possible in complex
language tasks.
However, the path of progress is not without its challenges. MoE models
grapple with issues such as balancing computational costs and the
increasing demand for high-quality outputs. Memory requirements and
fine-tuning also pose significant hurdles. To overcome these challenges,
DeepSeek-AI, a team dedicated to advancing the capabilities of AI
To read more such articles, please visit our blog [Link]
To read more such articles, please visit our blog [Link]
language models, introduced DeepSeek-V2. Building on the foundation
laid by its predecessor, DeepSeek 67B, DeepSeek-V2 represents a leap
forward in the field of AI.
What is DeepSeek-V2?
DeepSeek-V2 is a state-of-the-art Mixture-of-Experts (MoE) language
model that stands out due to its economical training and efficient
inference capabilities. It is a powerful model that comprises a total of 236
billion parameters, with 21 billion activated for each token.
Model Variant(s)
DeepSeek-V2 comes in various variants, including the base model
suitable for general tasks and specialized versions like
DeepSeek-V2-Chat, which is optimized for conversational AI
applications. Each variant is tailored to excel in specific domains,
leveraging the model’s innovative architecture. these variants are not
just random iterations of the model. They are carefully designed and
fine-tuned to cater to specific use-cases.
Key Features of DeepSeek-V2
DeepSeek-V2 is characterized by several unique features:
● Economical Training: DeepSeek-V2 is designed to be
cost-effective. When compared to its predecessor, DeepSeek 67B,
it saves 42.5% of training costs, making it a more economical
choice for training large language models.
To read more such articles, please visit our blog [Link]
To read more such articles, please visit our blog [Link]
source - [Link]
● Efficient Inference: Efficiency is at the core of DeepSeek-V2. It
reduces the Key-Value (KV) cache by 93.3%, significantly
improving the efficiency of the model. Furthermore, it boosts the
maximum generation throughput by 5.76 times, enhancing the
model’s performance.
● Strong Performance: DeepSeek-V2 doesn’t compromise on
performance. It achieves stronger performance compared to its
predecessor, DeepSeek 67B, demonstrating the effectiveness of
its design and architecture.
● Innovative Architecture: DeepSeek-V2 includes innovative
features such as Multi-head Latent Attention (MLA) and
DeepSeekMoE architecture. These features allow for significant
compression of the KV cache into a latent vector and enable the
training of strong models at reduced costs through sparse
computation.
To read more such articles, please visit our blog [Link]
To read more such articles, please visit our blog [Link]
Capabilities/Use Case of DeepSeek-V2
DeepSeek-V2 excels in various domains, showcasing its versatility:
● Natural and Engaging Conversations: DeepSeek-V2 is adept at
generating natural and engaging conversations, making it an ideal
choice for applications like chatbots, virtual assistants, and
customer support systems.
● Wide Domain Expertise: DeepSeek-V2 excels in various
domains, including math, code, and reasoning. This wide domain
expertise makes it a versatile tool for a range of applications.
● Top-Tier Performance: DeepSeek-V2 has demonstrated top-tier
performance in AlignBench, surpassing GPT-4 and closely rivaling
GPT-4-Turbo. This showcases its capability to deliver high-quality
outputs in diverse tasks.
● Support for Large Context Length: The open-source model of
DeepSeek-V2 supports a 128K context length, while the Chat/API
supports 32K. This support for large context lengths enables it to
handle complex language tasks effectively.
How does DeepSeek-V2 work?/ Architecture/Design
DeepSeek-V2 is built on the foundation of the Transformer architecture,
a widely used model in the field of AI, known for its effectiveness in
handling complex language tasks. However, DeepSeek-V2 goes beyond
the traditional Transformer architecture by incorporating innovative
designs in both its attention module and Feed-Forward Network (FFN).
To read more such articles, please visit our blog [Link]
To read more such articles, please visit our blog [Link]
source - [Link]
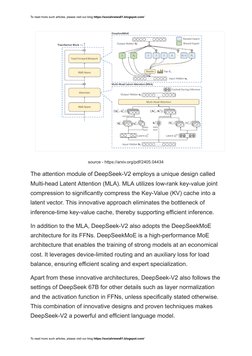
The attention module of DeepSeek-V2 employs a unique design called
Multi-head Latent Attention (MLA). MLA utilizes low-rank key-value joint
compression to significantly compress the Key-Value (KV) cache into a
latent vector. This innovative approach eliminates the bottleneck of
inference-time key-value cache, thereby supporting efficient inference.
In addition to the MLA, DeepSeek-V2 also adopts the DeepSeekMoE
architecture for its FFNs. DeepSeekMoE is a high-performance MoE
architecture that enables the training of strong models at an economical
cost. It leverages device-limited routing and an auxiliary loss for load
balance, ensuring efficient scaling and expert specialization.
Apart from these innovative architectures, DeepSeek-V2 also follows the
settings of DeepSeek 67B for other details such as layer normalization
and the activation function in FFNs, unless specifically stated otherwise.
This combination of innovative designs and proven techniques makes
DeepSeek-V2 a powerful and efficient language model.
To read more such articles, please visit our blog [Link]
To read more such articles, please visit our blog [Link]
Performance Evaluation with Other Models
DeepSeek-V2 has demonstrated remarkable performance on both
standard benchmarks and open-ended generation evaluation. Even with
only 21 billion activated parameters, DeepSeek-V2 and its chat versions
achieve top-tier performance among open-source models, becoming the
strongest open-source MoE language model.
source - [Link]
The model’s performance has been evaluated on a wide range of
benchmarks in English and Chinese, and compared with representative
open-source models. As highlighted in above figure 1(a) DeepSeek-V2
achieves top-ranking performance on MMLU with only a small number of
activated parameters.
source - [Link]
To read more such articles, please visit our blog [Link]
To read more such articles, please visit our blog [Link]
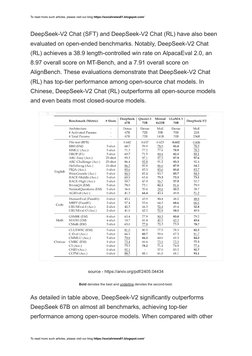
DeepSeek-V2 Chat (SFT) and DeepSeek-V2 Chat (RL) have also been
evaluated on open-ended benchmarks. Notably, DeepSeek-V2 Chat
(RL) achieves a 38.9 length-controlled win rate on AlpacaEval 2.0, an
8.97 overall score on MT-Bench, and a 7.91 overall score on
AlignBench. These evaluations demonstrate that DeepSeek-V2 Chat
(RL) has top-tier performance among open-source chat models. In
Chinese, DeepSeek-V2 Chat (RL) outperforms all open-source models
and even beats most closed-source models.
source - [Link]
Bold denotes the best and underline denotes the second-best.
As detailed in table above, DeepSeek-V2 significantly outperforms
DeepSeek 67B on almost all benchmarks, achieving top-tier
performance among open-source models. When compared with other
To read more such articles, please visit our blog [Link]
To read more such articles, please visit our blog [Link]
models such as Qwen1.5 72B, Mixtral 8x22B, and LLaMA3 70B,
DeepSeek-V2 demonstrates overwhelming advantages on the majority
of English, code, and math benchmarks. It also outperforms these
models overwhelmingly on Chinese benchmarks.
Finally, it’s worth mentioning that certain prior studies incorporate SFT
data during the pre-training stage, whereas DeepSeek-V2 has never
been exposed to SFT data during pre-training. Despite this,
DeepSeek-V2 still demonstrates substantial improvements in GSM8K,
MATH, and HumanEval evaluations compared with its base version. This
progress can be attributed to the inclusion of SFT data, which comprises
a considerable volume of math and code-related content. In addition,
DeepSeek-V2 Chat (RL) further boosts the performance on math and
code benchmarks.
Strategic Enhancements in DeepSeek-V2: A Comparative Analysis
DeepSeek-V2 distinguishes itself with its cost-effective training process
and efficient inference mechanism. This model achieves high-level
performance without demanding extensive computational resources. It is
designed with a massive 236 billion parameters, activating 21 billion of
them for each token processed. The model’s pretraining on a varied and
quality-rich corpus, complemented by Supervised Fine-Tuning (SFT) and
Reinforcement Learning (RL), maximizes its potential.
In contrast, Mixtral-8x22B, a Sparse Mixture-of-Experts (SMoE) model,
boasts 176 billion parameters, with 44 billion active during inference. It
demonstrates proficiency in several languages, including English,
French, Italian, German, and Spanish, and exhibits robust capabilities in
mathematics and coding. Meanwhile, Llamma-3-70B, which is tailored
for conversational applications, surpasses many open-source chat
models in standard industry benchmarks, although its total parameter
count remains unspecified.
To read more such articles, please visit our blog [Link]
To read more such articles, please visit our blog [Link]
Ultimately, DeepSeek-V2’s frugal training requirements and effective
inference position it as a standout model. Its substantial parameter
count, coupled with strategic Supervised Fine-Tuning (SFT) and
Reinforcement Learning (RL), significantly bolsters its functionality.
These attributes solidify DeepSeek-V2’s status as a formidable presence
in the arena of AI language models.
How to Access and Use DeepSeek-V2?
DeepSeek-V2 is an open-source model that is accessible through its
GitHub repository. It can be used both locally and online, offering
flexibility in its usage. For online use, demo links are provided by
HuggingFace, a platform that hosts thousands of pre-trained models in
multiple languages.
Despite the constraints of HuggingFace, which may result in slower
performance when running on GPUs, DeepSeek-AI has provided a
dedicated solution to optimize the model’s performance effectively. This
ensures that users can leverage the full potential of DeepSeek-V2 in
their applications. The model is not only open-source but also
commercially usable, with a clear licensing structure detailed in the
GitHub repository.
Limitations And Future Work
While DeepSeek-V2 represents a significant advancement in the field of
AI, it shares common limitations with other large language models
(LLMs). One such limitation is the lack of ongoing knowledge updates
after pre-training, which means the model’s knowledge is frozen at the
time of training and does not update with new information. Another
potential issue is the generation of non-factual information, a challenge
faced by many AI models.
To read more such articles, please visit our blog [Link]
To read more such articles, please visit our blog [Link]
However, it’s important to note that these limitations are part of the
current state of AI and are areas of active research. Future work by
DeepSeek-AI and the broader AI community will focus on addressing
these challenges, continually pushing the boundaries of what’s possible
with AI.
Conclusion
DeepSeek-V2 represents a significant milestone in the evolution of MoE
language models. Its unique combination of performance, efficiency, and
cost-effectiveness positions it as a leading solution in the AI landscape.
As AI continues to advance, DeepSeek-V2 will undoubtedly play a
pivotal role in shaping the future of language modeling.
Source
research paper : [Link]
research document : [Link]
GitHub repo : [Link]
Model weights:
[Link]
[Link]
To read more such articles, please visit our blog [Link]