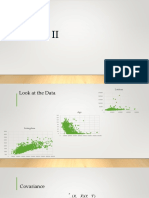
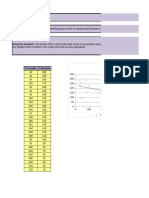
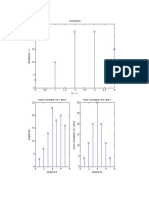
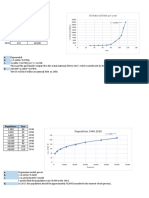
You might also like
- Cost Estimating Manual for Pipelines and Marine Structures: New Printing 1999From EverandCost Estimating Manual for Pipelines and Marine Structures: New Printing 1999Rating: 5 out of 5 stars5/5 (2)
- Case Project EconometricsDocument4 pagesCase Project EconometricsGarimaNo ratings yet
- Project 5 - Exponential and Logarithmic ProjectDocument7 pagesProject 5 - Exponential and Logarithmic Projectapi-489129243No ratings yet
- Geological Cross Sections and ContoursDocument34 pagesGeological Cross Sections and Contoursnwankwovincent61No ratings yet
- 2.2 Location Breakeven AnalysisDocument3 pages2.2 Location Breakeven Analysisorenchladee100% (1)
- H J Heinz Merger and Diversification Offer Growth Opportunities in A Difficult Market 29803 PDFDocument23 pagesH J Heinz Merger and Diversification Offer Growth Opportunities in A Difficult Market 29803 PDFarpitNo ratings yet
- Algebra AnswersDocument43 pagesAlgebra AnswersPriya Tripathi79% (19)
- Chapter Three Descriptive Statistics Ii: Numerical Methods Multiple Choice QuestionsDocument14 pagesChapter Three Descriptive Statistics Ii: Numerical Methods Multiple Choice QuestionsPurnima Sidhant BabbarNo ratings yet
- Smoke Point of Kerosine and Aviation Turbine Fuel: Standard Test Method ForDocument8 pagesSmoke Point of Kerosine and Aviation Turbine Fuel: Standard Test Method ForAhmedNo ratings yet
- Basic Research Elements PDFDocument19 pagesBasic Research Elements PDFA Salces Cajes100% (2)
- IPMVP Core ConceptsDocument28 pagesIPMVP Core ConceptsWaleed A. Shreim100% (1)
- Iso TS 28038-2018Document60 pagesIso TS 28038-2018TSUFANo ratings yet
- AnswerDocument7 pagesAnswerMohd Sharil100% (2)
- Database Management Systems: Understanding and Applying Database TechnologyFrom EverandDatabase Management Systems: Understanding and Applying Database TechnologyRating: 4 out of 5 stars4/5 (8)
- Walmart-Case-Study-LATEST-1 RevisedDocument39 pagesWalmart-Case-Study-LATEST-1 Revisedlook porrNo ratings yet
- Research ProjectDocument28 pagesResearch Projectshoaib100% (1)
- Simple RegressionDocument46 pagesSimple Regressionjyotisagar talukdarNo ratings yet
- Session 12Document27 pagesSession 12PRIYADARSHI PANKAJNo ratings yet
- RegressionDocument12 pagesRegressionHarshit RathourNo ratings yet
- PTA TerrrrbaruDocument1 pagePTA TerrrrbaruTHT-BKL UnhasNo ratings yet
- Scatter PlotDocument5 pagesScatter Plotvenkat_19No ratings yet
- Problem Set 2 SolutionsDocument34 pagesProblem Set 2 SolutionsglavchevanasikNo ratings yet
- Practice FileDocument22 pagesPractice Fileএ.বি.এস. আশিকNo ratings yet
- Es 13 (Laboratory No.2)Document3 pagesEs 13 (Laboratory No.2)Rey JagnaNo ratings yet
- JulianDocument2 pagesJulianALLAN STEVEN ROMERO RODRIGUEZNo ratings yet
- DAX FormulaDocument165 pagesDAX Formulaanon_86752300No ratings yet
- Discofuse EditsDocument1 pageDiscofuse Editspmfcyjf9No ratings yet
- Exp7,7 1,6Document3 pagesExp7,7 1,6datta_godbole830No ratings yet
- Audiogram: DEXTRADocument1 pageAudiogram: DEXTRAAnonymous vxyyUu0MlZNo ratings yet
- Go To:: Volts (V) Current (A) Resistance (R) WorksheetDocument17 pagesGo To:: Volts (V) Current (A) Resistance (R) Worksheetapi-3738054No ratings yet
- Commitment of Traders ReportDocument14 pagesCommitment of Traders ReportZerohedgeNo ratings yet
- Project 5 PDFDocument3 pagesProject 5 PDFapi-509845050No ratings yet
- ECO PaperDocument35 pagesECO PaperGaurav AgarwalNo ratings yet
- 1395-Monthly Fiscal Bulletin 10 - DariDocument15 pages1395-Monthly Fiscal Bulletin 10 - DariMacro Fiscal PerformanceNo ratings yet
- Formato Aplicacion3.0Document18 pagesFormato Aplicacion3.0Nicolas Bohorquez ZamoranoNo ratings yet
- Chapter 7: Example 4: Cost-Volume AnalysisDocument2 pagesChapter 7: Example 4: Cost-Volume Analysiscovipanama covidNo ratings yet
- Fa Marketing Example AnswerDocument3 pagesFa Marketing Example AnswerShirohigeNo ratings yet
- Punto de Equilibrio: UnidadesDocument2 pagesPunto de Equilibrio: UnidadesKevin A. ChavarriaNo ratings yet
- Workshop 5 - Multicollinearity and Functional FormDocument77 pagesWorkshop 5 - Multicollinearity and Functional FormDoan Anh TuanNo ratings yet
- AlgebraanswersDocument44 pagesAlgebraanswersAnkitaNo ratings yet
- Linear Law Linear Programming: By: Ting Hie Huong Lee Mee ChingDocument29 pagesLinear Law Linear Programming: By: Ting Hie Huong Lee Mee ChingAnna LeeNo ratings yet
- CS ForecastingDocument4 pagesCS ForecastingDe Gala ShailynNo ratings yet
- Parcial 2 MicroeconomiaDocument4 pagesParcial 2 MicroeconomiaGarcia HeydiNo ratings yet
- Grafik Pipa Besar Pipa Besar: V (Laju Alir)Document2 pagesGrafik Pipa Besar Pipa Besar: V (Laju Alir)Dhyrana ShailaNo ratings yet
- Tangent ModulusDocument7 pagesTangent ModulusNobel AsresuNo ratings yet
- Assignment 1 QTDocument7 pagesAssignment 1 QTTiya BhattacharyaNo ratings yet
- Costo Total: Location A Location B Location CDocument9 pagesCosto Total: Location A Location B Location COmara Díaz HerreraNo ratings yet
- Plantilla-Armadura 3D Analisis Estructural Metodo MatricialDocument49 pagesPlantilla-Armadura 3D Analisis Estructural Metodo MatricialRaul DelgadoNo ratings yet
- Input Voltage 50 Vrms Resistor 20 Ohms Capacitor 35ufDocument2 pagesInput Voltage 50 Vrms Resistor 20 Ohms Capacitor 35ufMark Anthony Salazar ArcayanNo ratings yet
- Testing Spreadsheet Vs LRFD Tables: Truss Tr23 YP 29-Dec Sample ConnectionDocument4 pagesTesting Spreadsheet Vs LRFD Tables: Truss Tr23 YP 29-Dec Sample Connectionvijay10484No ratings yet
- Image5 Intensity TransfDocument25 pagesImage5 Intensity TransfYaacoub El GuezdarNo ratings yet
- Product 1 - 1000 2023 10 30Document7 pagesProduct 1 - 1000 2023 10 30fbaprecast2508No ratings yet
- Ex 3 - ABP MPDDocument7 pagesEx 3 - ABP MPDdanielmcaeNo ratings yet
- Photoelectric Effect Sim DataDocument5 pagesPhotoelectric Effect Sim DataVital RogatchNo ratings yet
- GC2Document2 pagesGC2Mohammad Rezza PachruraziNo ratings yet
- Select Row Labels in Chart, Double Click, Click On Select DataDocument25 pagesSelect Row Labels in Chart, Double Click, Click On Select DataRushilNo ratings yet
- MTK HororDocument10 pagesMTK HororNanda Pratama Nor RochimNo ratings yet
- PTA TerrrrbaruDocument1 pagePTA TerrrrbaruNadhirah AnandaNo ratings yet
- Constant Total Mass Constant Net ForceDocument4 pagesConstant Total Mass Constant Net ForceErwin CabangalNo ratings yet
- SensitivityDocument2 pagesSensitivitychriscramphorn2397No ratings yet
- Sorting GraphDocument3 pagesSorting Graphzakia.syeed51No ratings yet
- BD20022 OprDocument12 pagesBD20022 OprDeepNo ratings yet
- Lec22 - Goodness of FitDocument4 pagesLec22 - Goodness of FitLexNo ratings yet
- Lecture 6Document20 pagesLecture 6Costanza NeversurrenderNo ratings yet
- Answer2 PDFDocument16 pagesAnswer2 PDFarpitNo ratings yet
- Linear Programming CasesDocument5 pagesLinear Programming CasesarpitNo ratings yet
- Mure WriteupDocument1 pageMure WriteuparpitNo ratings yet
- CHEETOS-19 KeyDocument2 pagesCHEETOS-19 KeyarpitNo ratings yet
- Question Based On Data SetDocument3 pagesQuestion Based On Data SetarpitNo ratings yet
- Transshipment ProblemDocument3 pagesTransshipment ProblemarpitNo ratings yet
- Question - A: Parameters Smoker Non-Smoker Total Men Women TotalDocument7 pagesQuestion - A: Parameters Smoker Non-Smoker Total Men Women TotalarpitNo ratings yet
- Godrej Agrovet Ratio Analysis 17-18Document16 pagesGodrej Agrovet Ratio Analysis 17-18arpitNo ratings yet
- Marketing Affiliate Marketing: Save WaterDocument33 pagesMarketing Affiliate Marketing: Save WaterarpitNo ratings yet
- CEI Activity ReportDocument113 pagesCEI Activity ReportarpitNo ratings yet
- 5 Gender DivideDocument13 pages5 Gender DividearpitNo ratings yet
- Metvy University Live Project Task 2: Brand PositioningDocument5 pagesMetvy University Live Project Task 2: Brand PositioningarpitNo ratings yet
- Preventing SH at WORKPLACEDocument46 pagesPreventing SH at WORKPLACEarpitNo ratings yet
- For Immediate Release: No Intimation of Delays If Any, and Completely A "Ram Bharose" and "Chalta Hai" Attitude. I WouldDocument2 pagesFor Immediate Release: No Intimation of Delays If Any, and Completely A "Ram Bharose" and "Chalta Hai" Attitude. I WouldarpitNo ratings yet
- 4 Regression IssuesDocument44 pages4 Regression IssuesarpitNo ratings yet
- ICICI Case PDFDocument2 pagesICICI Case PDFSnehalNo ratings yet
- THBT Social Deprivation Causes CrimesDocument3 pagesTHBT Social Deprivation Causes CrimesArifAkmal0% (1)
- Homework 8Document2 pagesHomework 8RazaMobizoNo ratings yet
- Trade Off Between Liquidity and Profitability: Hina Mushtaq, Dr. Anwar F. Chishti, Sumaira Kanwal, Sobia SaeedDocument20 pagesTrade Off Between Liquidity and Profitability: Hina Mushtaq, Dr. Anwar F. Chishti, Sumaira Kanwal, Sobia SaeedNiravNo ratings yet
- A Propagation Model For Mobile Radio Propagation Loss in An Urban Area at 800 MHZDocument14 pagesA Propagation Model For Mobile Radio Propagation Loss in An Urban Area at 800 MHZMatthew CarterNo ratings yet
- 10 Perametric and Non PerametricDocument3 pages10 Perametric and Non PerametricPrashant SinghNo ratings yet
- Quantitative GeneticsDocument31 pagesQuantitative GeneticsMamtaNo ratings yet
- 109 315 1 SPDocument22 pages109 315 1 SPGabish JoshiNo ratings yet
- 02 - Math of Patter RecognitionDocument31 pages02 - Math of Patter RecognitionXg WuNo ratings yet
- THESIS Math Major LEGITDocument50 pagesTHESIS Math Major LEGITJoerizza Serrano FajilanNo ratings yet
- Dissertation Gerald OeserDocument266 pagesDissertation Gerald OeserAditya Tiwari100% (1)
- Siop Lesson PlanDocument7 pagesSiop Lesson Planapi-589124264No ratings yet
- StatDocument8 pagesStatAbegail TorremochaNo ratings yet
- Tourism Management: Shaoping Qiu, Larry M. Dooley, Lei XieDocument12 pagesTourism Management: Shaoping Qiu, Larry M. Dooley, Lei XieDesynta Rahmawati GunawanNo ratings yet
- Fast Fashion Brand Extensions: An Empirical Study of Consumer PreferencesDocument16 pagesFast Fashion Brand Extensions: An Empirical Study of Consumer PreferencesLAYLA •No ratings yet
- MATLAB For Brain and Cognitive ScientistsDocument11 pagesMATLAB For Brain and Cognitive Scientistsshankar0% (2)
- Linear Models - Numeric PredictionDocument7 pagesLinear Models - Numeric Predictionar9vegaNo ratings yet
- Data Analysis Techq.Document134 pagesData Analysis Techq.pant_gaurav8999100% (2)
- Monitoring of Abandoned Quarries by Remote Sensing and in Situ SurveyingDocument6 pagesMonitoring of Abandoned Quarries by Remote Sensing and in Situ SurveyingghaiethNo ratings yet
- Mechanical Reasoning and Space PerceptionDocument4 pagesMechanical Reasoning and Space PerceptionAna Belly OritzNo ratings yet
- Compensation and Its Impact On Motivation Employee S Satisfaction and Employee S PerformanceDocument43 pagesCompensation and Its Impact On Motivation Employee S Satisfaction and Employee S Performanceadhitya JulyanNo ratings yet
- Quantitative Data Analysis: Harshad BajpaiDocument26 pagesQuantitative Data Analysis: Harshad BajpaiAnkit KumarNo ratings yet
- Oxford Scholarship Online: The Big Stuck in State CapabilityDocument24 pagesOxford Scholarship Online: The Big Stuck in State CapabilityJesús María Alvarado AndradeNo ratings yet