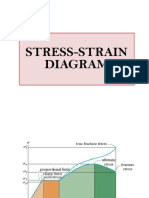
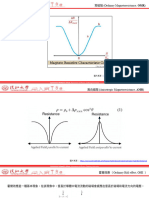
You might also like
- Kicad Like A Pro - Learn The World's Favour - Peter DalmarisDocument380 pagesKicad Like A Pro - Learn The World's Favour - Peter Dalmarisfirefox6667% (3)
- Assignment 4 CorrectedDocument3 pagesAssignment 4 CorrectedMNo ratings yet
- 5-1 Study Guide and Intervention: Operations With PolynomialsDocument2 pages5-1 Study Guide and Intervention: Operations With PolynomialsasdfasdfasdfasdfasdfNo ratings yet
- Lesson 2 Similar and Dissimilar FractionsDocument36 pagesLesson 2 Similar and Dissimilar FractionsNiño Paul MixNo ratings yet
- Adhvaitha Hitesh PDFDocument14 pagesAdhvaitha Hitesh PDFNupur GuptaNo ratings yet
- Lesson 11 The Antiderivative of A Function PDFDocument33 pagesLesson 11 The Antiderivative of A Function PDFtrisha paclebNo ratings yet
- EA Chapter4 EigenValuesVectorsV14 PDFDocument121 pagesEA Chapter4 EigenValuesVectorsV14 PDFSriparvathi BhattathiriNo ratings yet
- Tarnsformer Part1 10 Mar 23 PDFDocument47 pagesTarnsformer Part1 10 Mar 23 PDFarpan singhNo ratings yet
- Álgebra Anual División AlgebraicaDocument44 pagesÁlgebra Anual División AlgebraicaRicardo Espino LizamaNo ratings yet
- Álgebra Anual División Algebraica CompletoDocument27 pagesÁlgebra Anual División Algebraica CompletoRicardo Espino LizamaNo ratings yet
- Handouts MathanaDocument5 pagesHandouts MathanaRiajosh ZabalaNo ratings yet
- Álgebra - Radicación y Ecuación ExponencialDocument5 pagesÁlgebra - Radicación y Ecuación ExponencialFranz TorresNo ratings yet
- Neural Network II - Part 1Document39 pagesNeural Network II - Part 1pepitoNo ratings yet
- New Formula ListDocument2 pagesNew Formula Listtai li yungNo ratings yet
- Quantum Mechanics L23Document14 pagesQuantum Mechanics L23JoshuaNo ratings yet
- Chapter IV-APPLICATION OF THE DERIVATIVE... Continuation: Time RatesDocument4 pagesChapter IV-APPLICATION OF THE DERIVATIVE... Continuation: Time RatesGil John AwisenNo ratings yet
- Review2 SlidesDocument9 pagesReview2 SlidesRuru YTNo ratings yet
- REPASO MomentumDocument7 pagesREPASO MomentumSALVADOR VARGAS DIAZNo ratings yet
- Vivin Mahfiroh - Business Math - Thread 1Document2 pagesVivin Mahfiroh - Business Math - Thread 1vhyNo ratings yet
- The Symmetric and Dihedral GroupsDocument31 pagesThe Symmetric and Dihedral Groupsjennelyn malaynoNo ratings yet
- Unit II - Session 06Document6 pagesUnit II - Session 06K.A.S.S PereraNo ratings yet
- Lect 4 DErivation of Element Properties 3 Node Bar Element Derivation ExamplesDocument14 pagesLect 4 DErivation of Element Properties 3 Node Bar Element Derivation ExamplesKaran PatelNo ratings yet
- Acceleratia Unghiulara - 6. 7. 8Document6 pagesAcceleratia Unghiulara - 6. 7. 8IGYUSTICE THENo ratings yet
- Theory of Structures II Lecture Notes Three-Moment EquationDocument19 pagesTheory of Structures II Lecture Notes Three-Moment EquationRex John TapungotNo ratings yet
- Propiedades de La SeccionDocument10 pagesPropiedades de La SeccionPierre NievesNo ratings yet
- CH 3 Exercise 1Document8 pagesCH 3 Exercise 1Mutee Ur RahmanNo ratings yet
- Formulee Sheet Given in The ExamDocument4 pagesFormulee Sheet Given in The Examhalide90No ratings yet
- بحث سجى كاظمDocument6 pagesبحث سجى كاظمalmhkra47No ratings yet
- Lesson 2 Limit of Trigonometric FunctionsDocument5 pagesLesson 2 Limit of Trigonometric FunctionsJunior LifeNo ratings yet
- Chapter 1 - 1.3aDocument5 pagesChapter 1 - 1.3aMuhammad NasrulNo ratings yet
- Chap 2 Internal EnergyDocument15 pagesChap 2 Internal Energy李侑霖 LEE YULIN P46094163No ratings yet
- Lesson 2 Chapter 3Document12 pagesLesson 2 Chapter 3Stephanie BiyoNo ratings yet
- LP4 - Pre-CalculusDocument41 pagesLP4 - Pre-CalculusZyrelle AgullanaNo ratings yet
- Solved ExampleDocument3 pagesSolved ExampleSaif JassimNo ratings yet
- Solved ExampleDocument3 pagesSolved ExampleSaif JassimNo ratings yet
- Math 9 QTR 2 Week 4Document8 pagesMath 9 QTR 2 Week 4Academic Commissions - Pagawa ng ModulesNo ratings yet
- Fiz1001 2.vize B - Ing - 2023 2024Document4 pagesFiz1001 2.vize B - Ing - 2023 2024kjjsbdfjkjhafNo ratings yet
- 12thy Maths Creative One Mark Questions Vol-2Document21 pages12thy Maths Creative One Mark Questions Vol-2Su SiNo ratings yet
- Practice Exercise 1: Find The Domain of The Following Functions. + 2 1Document17 pagesPractice Exercise 1: Find The Domain of The Following Functions. + 2 1Angelo ReyesNo ratings yet
- Formulario Ing de FluidosDocument1 pageFormulario Ing de FluidosSarah CortésNo ratings yet
- Formulario de Física ClásicaDocument4 pagesFormulario de Física Clásicadiego9723No ratings yet
- CPMK 2 Energy ConversionDocument5 pagesCPMK 2 Energy ConversionMuhammad Malikul AzhimNo ratings yet
- Math 9 Q2 Week 4Document9 pagesMath 9 Q2 Week 4Rhai EspiNo ratings yet
- Exponential and Logarithmic IntegrationDocument8 pagesExponential and Logarithmic IntegrationVincent VasquezNo ratings yet
- Rotating VesselDocument10 pagesRotating VesselCherryMae MancilhayNo ratings yet
- 2d. TRANSFORMATION BY TRIGONOMETRIC FORMULASDocument13 pages2d. TRANSFORMATION BY TRIGONOMETRIC FORMULASMildred Cardenas BañezNo ratings yet
- Si1ta-010322b-Al-T05-División Algebraica I-Prof Ricardo EspinoDocument20 pagesSi1ta-010322b-Al-T05-División Algebraica I-Prof Ricardo EspinoJorge GuarnízNo ratings yet
- Unit 3.2 Merge, Quick Sort Ans Strassen MatrixDocument74 pagesUnit 3.2 Merge, Quick Sort Ans Strassen MatrixHarshil ModhNo ratings yet
- Las Math9 Q4 W2Document10 pagesLas Math9 Q4 W2Marie PatuboNo ratings yet
- Rules For Approximating Definite Integrals: Sin, Sin, 1Document5 pagesRules For Approximating Definite Integrals: Sin, Sin, 1トシToshiNo ratings yet
- Lecture 7 - PropGases - Critical ConstantsDocument12 pagesLecture 7 - PropGases - Critical ConstantsDavid NadhipiteNo ratings yet
- Derivatives of Hyperbolic FunctionsDocument11 pagesDerivatives of Hyperbolic FunctionsImmanuel De Los ReyesNo ratings yet
- Matrices 2Document9 pagesMatrices 2faroq AlromimahNo ratings yet
- HW5 SolutiontuDocument11 pagesHW5 Solutiontu厭世仔No ratings yet
- Calc 9.4 PacketDocument3 pagesCalc 9.4 PacketAN NGUYENNo ratings yet
- Theory 1-Module 2Document21 pagesTheory 1-Module 2Renel Caliging RamirezNo ratings yet
- Module 2 Definite Integrals Chain Rule and Exponential FunctionsDocument26 pagesModule 2 Definite Integrals Chain Rule and Exponential Functions2023-202017No ratings yet
- Andreza, Lemuel V. Activity 4 PDFDocument11 pagesAndreza, Lemuel V. Activity 4 PDFlemuel andrezaNo ratings yet
- AnswerDocument1 pageAnswerLaurence Lee Advento100% (1)
- GRAPHS OF THE SIX CIRCULAR FUNCTIONS (Lesson 6)Document10 pagesGRAPHS OF THE SIX CIRCULAR FUNCTIONS (Lesson 6)Teylan Ruzzel BartNo ratings yet
- Chapter 4 Applications of Partial Derivatives: 1. Maxima and MinimaDocument16 pagesChapter 4 Applications of Partial Derivatives: 1. Maxima and Minima物理系小薯No ratings yet
- 實驗報告1Document6 pages實驗報告1SuzanneNo ratings yet
- Panasonic Th-37pv8p Th-37px8b Th-42pv8p Th-42px8b Th-42px8e Chassis Gph11deDocument173 pagesPanasonic Th-37pv8p Th-37px8b Th-42pv8p Th-42px8b Th-42px8e Chassis Gph11deYoly Rio RamosNo ratings yet
- Tennis Ball Detection Using Matlab Image Procesing: Aaqib Ali (2015002), Adnan Afzal (2015028)Document4 pagesTennis Ball Detection Using Matlab Image Procesing: Aaqib Ali (2015002), Adnan Afzal (2015028)aaqibNo ratings yet
- Oss Unit IIIDocument44 pagesOss Unit IIIchandruchandru93439No ratings yet
- Mcpa2-15-Ind - Rev 1Document1 pageMcpa2-15-Ind - Rev 1ttaauuNo ratings yet
- AdvantcoRESTAdapter UserGuide v1.0.39Document59 pagesAdvantcoRESTAdapter UserGuide v1.0.39raghu veerNo ratings yet
- BHELDocument15 pagesBHELjgkrishnanNo ratings yet
- Ruby PhrasebookDocument218 pagesRuby PhrasebookPrabin SilwalNo ratings yet
- Qualcomm Snapdragon Processor: Professor Name: Dr. Amjed Al-Taweel Student Name: Maytham MahdiDocument12 pagesQualcomm Snapdragon Processor: Professor Name: Dr. Amjed Al-Taweel Student Name: Maytham Mahdimaytham mahdiNo ratings yet
- Inside Out Advanced Grammar Companion Key Inside OutDocument20 pagesInside Out Advanced Grammar Companion Key Inside Outpablo_sebastian_666No ratings yet
- Template - Purchase Order FormDocument4 pagesTemplate - Purchase Order FormGryswolfNo ratings yet
- Factor Hair Revised PDFDocument25 pagesFactor Hair Revised PDFSampada Halve100% (1)
- HSEQ-RO-06!04!00 Management of Technical IntegrityDocument13 pagesHSEQ-RO-06!04!00 Management of Technical IntegrityagaricusNo ratings yet
- P3D Majestic Q400 GuideDocument140 pagesP3D Majestic Q400 GuideDanielNo ratings yet
- FYP Bus Tracking SystemDocument41 pagesFYP Bus Tracking SystemMuhammad JameelNo ratings yet
- Wharfedale HistoryDocument24 pagesWharfedale HistoryradovanovdNo ratings yet
- Food Order Management SystemDocument20 pagesFood Order Management SystemHarshu KummuNo ratings yet
- 1747-ASB Replacement PDFDocument3 pages1747-ASB Replacement PDFHari PrashannaNo ratings yet
- 03 LoadBalancing With RibbonDocument6 pages03 LoadBalancing With RibbonvigneshNo ratings yet
- Publishing Info Apet2eDocument5 pagesPublishing Info Apet2eDan HussainNo ratings yet
- 3 6 1 P 60477bf33412e FileDocument10 pages3 6 1 P 60477bf33412e FileKunal AhiwaleNo ratings yet
- Installation Guide For Ecofresh International Software Version 1.7.1 MS-270 (ARI), SG-250 (ARI), SG-200 (Eurovent)Document2 pagesInstallation Guide For Ecofresh International Software Version 1.7.1 MS-270 (ARI), SG-250 (ARI), SG-200 (Eurovent)pitong_manningNo ratings yet
- Schrier Tcas1 SCDocument11 pagesSchrier Tcas1 SCDebopam BanerjeeNo ratings yet
- Introduction To Electromagnetic Relay: Experiment No. 4Document1 pageIntroduction To Electromagnetic Relay: Experiment No. 4Phantom BeingNo ratings yet
- IRF 3805-IRF 3805S-IRF 3805L - MosfetDocument12 pagesIRF 3805-IRF 3805S-IRF 3805L - MosfetTiago LeonhardtNo ratings yet
- Pdfdownloadbiofloc 180709165029Document5 pagesPdfdownloadbiofloc 180709165029anonymous man67% (6)
- Fields To Fill-In To List A Product: Template Introduction Sheet ListDocument24 pagesFields To Fill-In To List A Product: Template Introduction Sheet Listjhenerald vegaNo ratings yet
- Sales and Distribution Material Management: Afn) Agn) Tan) LF)Document5 pagesSales and Distribution Material Management: Afn) Agn) Tan) LF)meddebyounesNo ratings yet