You might also like
- How To Scrape Websites With Python and BeautifulSoup PDFDocument10 pagesHow To Scrape Websites With Python and BeautifulSoup PDFerivandoramos100% (1)
- Advanced Web Scraping TacticsDocument16 pagesAdvanced Web Scraping TacticsAman AliNo ratings yet
- Web Scraping Using Python: A Step by Step Guide: September 2019Document7 pagesWeb Scraping Using Python: A Step by Step Guide: September 2019Haseeb JoyiaNo ratings yet
- Web Scraping - Unit 1Document31 pagesWeb Scraping - Unit 1MANOHAR SIVVALA 20111632100% (1)
- College Website PHPDocument19 pagesCollege Website PHPRavi Shankar K B76% (59)
- The Trend Trader Nick Radge On Demand PDFDocument8 pagesThe Trend Trader Nick Radge On Demand PDFDedi Tri LaksonoNo ratings yet
- Structural Analysis of English SyntaxDocument26 pagesStructural Analysis of English SyntaxremovableNo ratings yet
- 1.1 Web ScrapingDocument34 pages1.1 Web ScrapinginesNo ratings yet
- Session 3 Data Aquisition - UpdatedDocument40 pagesSession 3 Data Aquisition - UpdatedAlessandro Sinai100% (1)
- Brand Loyalty & Competitive Analysis of Pankaj NamkeenDocument59 pagesBrand Loyalty & Competitive Analysis of Pankaj NamkeenBipin Bansal Agarwal100% (1)
- Mule Soft For ABDocument68 pagesMule Soft For ABshaik shazilNo ratings yet
- Web Scrapping: Dept - of CS&E, BIET, Davangere Page - 1Document8 pagesWeb Scrapping: Dept - of CS&E, BIET, Davangere Page - 1jeanieNo ratings yet
- Selenium IQDocument14 pagesSelenium IQAvi GuptaNo ratings yet
- Orifice Plate Calculator Pressure Drop CalculationsDocument4 pagesOrifice Plate Calculator Pressure Drop CalculationsAnderson Pioner100% (1)
- Data Science BooksDocument11 pagesData Science BooksAnalytics Insight100% (1)
- Presented by Asif M: TopicDocument17 pagesPresented by Asif M: TopicAsif MdNo ratings yet
- SAP Data Services 4.x Cookbook - Sample ChapterDocument35 pagesSAP Data Services 4.x Cookbook - Sample ChapterPackt Publishing100% (2)
- API PostmanDocument15 pagesAPI PostmanQforQA0% (2)
- Web Scraping Using Python: A Step by Step Guide: September 2019Document7 pagesWeb Scraping Using Python: A Step by Step Guide: September 2019abhinavtechnocratNo ratings yet
- Step Buying Process in LazadaDocument4 pagesStep Buying Process in LazadaAfifah FatihahNo ratings yet
- Wind Turbine Power Plant Seminar ReportDocument32 pagesWind Turbine Power Plant Seminar ReportShafieul mohammadNo ratings yet
- Web ScrappingDocument57 pagesWeb ScrappingArindam DuttaNo ratings yet
- Annual Implementation Plan FinalDocument3 pagesAnnual Implementation Plan FinalMichelle Ann Narvino100% (2)
- Web Services With REST and ICFDocument12 pagesWeb Services With REST and ICFvbvrkNo ratings yet
- Instagram Automation Tool: Project DescriptionDocument10 pagesInstagram Automation Tool: Project DescriptionMeenakshi Sharma100% (1)
- Web Scraping With Python and Selenium: Sarah Fatima, Shaik Luqmaan Nuha Abdul RasheedDocument5 pagesWeb Scraping With Python and Selenium: Sarah Fatima, Shaik Luqmaan Nuha Abdul RasheedVanessa DouradoNo ratings yet
- Data - Collection PythonDocument40 pagesData - Collection PythonZADOD YASSINENo ratings yet
- Page - 1Document45 pagesPage - 1Madhava KrishnaNo ratings yet
- Web ProgrammingDocument36 pagesWeb Programmingrahulchaudhary27075No ratings yet
- Accessing and Extracting Data From The Internet Using SAS George Zhu, Sunita Ghosh, Alberta Health Services - Cancer CareDocument10 pagesAccessing and Extracting Data From The Internet Using SAS George Zhu, Sunita Ghosh, Alberta Health Services - Cancer Caresasdoc2010No ratings yet
- Api 01Document54 pagesApi 01TonyNo ratings yet
- Slide10 Part1Document35 pagesSlide10 Part1Thi Nguyễn Thương NgânNo ratings yet
- XML and Web ServicesDocument39 pagesXML and Web ServicessamantawidjajaNo ratings yet
- Salesforce Integration QueDocument5 pagesSalesforce Integration Queabc97057No ratings yet
- DownloadDocument4 pagesDownloadSAIFUR RAHMANNo ratings yet
- E-Commerce Lab: Muhammad Ali KhanDocument20 pagesE-Commerce Lab: Muhammad Ali KhanFatima Arif AlamNo ratings yet
- OnlineDocument25 pagesOnlineRajanala RajasekharreddyNo ratings yet
- Api PresentationDocument30 pagesApi PresentationpcuserantNo ratings yet
- Module 2 WebDocument22 pagesModule 2 WebArvin BuzonNo ratings yet
- Web Scraping Using Python: A Step by Step Guide: September 2019Document7 pagesWeb Scraping Using Python: A Step by Step Guide: September 2019abhinavtechnocratNo ratings yet
- CherryPy of Python - Aravind AriharasudhanDocument29 pagesCherryPy of Python - Aravind AriharasudhanAravind AriharasudhanNo ratings yet
- Plans On First WeekDocument7 pagesPlans On First WeekEmanuel Paul RusuNo ratings yet
- Servelets JSPsDocument44 pagesServelets JSPsChayma CharradaNo ratings yet
- Difference Between Static Website and Dynamic WebsiteDocument12 pagesDifference Between Static Website and Dynamic WebsiteNirav PatelNo ratings yet
- Web Scraping Using Python - NotesDocument6 pagesWeb Scraping Using Python - NotesAnand SharmaNo ratings yet
- Bus Pass Managemen ReportDocument42 pagesBus Pass Managemen ReportJittina cj50% (2)
- Search Engine Functionality For LLP: Apache LuceneDocument6 pagesSearch Engine Functionality For LLP: Apache LucenevikashvardhanNo ratings yet
- Christos ChenDocument42 pagesChristos ChenManisha TanwarNo ratings yet
- PHPDocument22 pagesPHPsmengesha838No ratings yet
- Search: Skip To Content Using Gmail With Screen ReadersDocument11 pagesSearch: Skip To Content Using Gmail With Screen ReadersKavitha100% (1)
- Report - 2014-07-03 08-14-27Document20 pagesReport - 2014-07-03 08-14-27Emanuel Paxtian CotoNo ratings yet
- ListDocument7 pagesListRamesh GuptaNo ratings yet
- Python LibrariesDocument12 pagesPython LibrariesDiego RodríguezNo ratings yet
- Techgigwebservices 140514010219 Phpapp01Document37 pagesTechgigwebservices 140514010219 Phpapp01nishaNo ratings yet
- Security Testing With JMeterDocument11 pagesSecurity Testing With JMeterNguyễn ViệtNo ratings yet
- GWP-Technical SEO-251022-111228Document6 pagesGWP-Technical SEO-251022-111228Sara Popov PetrovicNo ratings yet
- Apartment Visitors SystemDocument21 pagesApartment Visitors SystemAkshayNo ratings yet
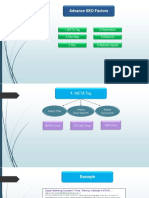
- Advance SEO Factors: 1.META Tag 4.redirection 5.robot - TXT 2.site MapDocument13 pagesAdvance SEO Factors: 1.META Tag 4.redirection 5.robot - TXT 2.site MapChirag Ashok AsarpotaNo ratings yet
- Unit 4: PHP: Web ProgrammingDocument47 pagesUnit 4: PHP: Web ProgrammingAtharv KarnekarNo ratings yet
- TrialsDocument3 pagesTrialskskskkewjwjwNo ratings yet
- Postman For Api Testing: A Beginner'S Guide: Learn To Test Apis Like A Pro With Postman With Real-World Examples and Step-By-Step Guidance ParvinDocument52 pagesPostman For Api Testing: A Beginner'S Guide: Learn To Test Apis Like A Pro With Postman With Real-World Examples and Step-By-Step Guidance Parvinraymond.taylor289100% (4)
- HTML Unleashed The Complete Guide To Building Web PagesDocument7 pagesHTML Unleashed The Complete Guide To Building Web PagesMehedy Abu Hasan AlveeNo ratings yet
- Webdev Midterm ReviewerDocument9 pagesWebdev Midterm ReviewerMendoza Paula Nicole NavarroNo ratings yet
- Integration ComponentsDocument15 pagesIntegration ComponentsashikalinNo ratings yet
- 4.dynamic Web SiteDocument14 pages4.dynamic Web Sitemba20238No ratings yet
- Pervasive Web Services and Security 2010Document123 pagesPervasive Web Services and Security 2010arunkumatbitsNo ratings yet
- Web Services NotesDocument20 pagesWeb Services NotesselcukcankurtNo ratings yet
- Cassius Resume CVLatestDocument3 pagesCassius Resume CVLatestCaszNo ratings yet
- 2.HVT Terminacion InstrDocument18 pages2.HVT Terminacion Instrelectrica3No ratings yet
- Philips Cdr775Document50 pagesPhilips Cdr775Tomasz SkrzypińskiNo ratings yet
- The Light BulbDocument6 pagesThe Light Bulbapi-244765407No ratings yet
- Classification by Depth Distribution of Phytoplankton and ZooplanktonDocument31 pagesClassification by Depth Distribution of Phytoplankton and ZooplanktonKeanu Denzel BolitoNo ratings yet
- Chemical Equilibrium Chemistry Grade 12: Everything Science WWW - Everythingscience.co - ZaDocument10 pagesChemical Equilibrium Chemistry Grade 12: Everything Science WWW - Everythingscience.co - ZaWaqas LuckyNo ratings yet
- IBEF Cement-February-2023Document26 pagesIBEF Cement-February-2023Gurnam SinghNo ratings yet
- How To Draw The Platform Business Model Map-David RogersDocument5 pagesHow To Draw The Platform Business Model Map-David RogersworkneshNo ratings yet
- MBenz SLK350 R171 272 RepairDocument1,922 pagesMBenz SLK350 R171 272 RepairJavier ViudezNo ratings yet
- Instability of Slender Concrete Deep BeamDocument12 pagesInstability of Slender Concrete Deep BeamFrederick TanNo ratings yet
- Fire Master Mirine PlusDocument3 pagesFire Master Mirine PlusCarlos BarriosNo ratings yet
- Teacher Survey - Outdoor Classroom Feedback: Please Circle All That ApplyDocument3 pagesTeacher Survey - Outdoor Classroom Feedback: Please Circle All That ApplyBrooke Doran RoeNo ratings yet
- Assignment-3: Marketing Management (MGT201)Document6 pagesAssignment-3: Marketing Management (MGT201)Rizza L. MacarandanNo ratings yet
- Anti LeproticDocument9 pagesAnti LeproticMeenakshi shARMANo ratings yet
- Juan LunaDocument2 pagesJuan LunaClint Dave OacanNo ratings yet
- New Criticism Hills Like White Elephants FinalDocument4 pagesNew Criticism Hills Like White Elephants Finalapi-313631761No ratings yet
- TP PortalDocument25 pagesTP PortalSurendranNo ratings yet
- Dharmakirti On Pratyaksa PDFDocument14 pagesDharmakirti On Pratyaksa PDFonlineyyk100% (1)
- Stat and Prob Q4 M2 DigitizedDocument38 pagesStat and Prob Q4 M2 Digitizedsecret secretNo ratings yet
- Presentation 1Document11 pagesPresentation 1CJ CastroNo ratings yet
- Department of Labor: BC Bond ListDocument67 pagesDepartment of Labor: BC Bond ListUSA_DepartmentOfLabor100% (1)
- Teacher Thought For InterviewDocument37 pagesTeacher Thought For InterviewMahaprasad JenaNo ratings yet