You might also like
- e0b8aae0b8abe0b8aae0b8b1e0b8a1e0b89ee0b8b1e0b899e0b898e0b98ce0b89ee0b8abe0b8b8e0b884e0b8b9e0b893Document37 pagese0b8aae0b8abe0b8aae0b8b1e0b8a1e0b89ee0b8b1e0b899e0b898e0b98ce0b89ee0b8abe0b8b8e0b884e0b8b9e0b893Nriav KojNo ratings yet
- 11สหสัมพันธ์และการถดถอยเชิงเส้นตรงอย่างง่Document12 pages11สหสัมพันธ์และการถดถอยเชิงเส้นตรงอย่างง่Dodora EmonNo ratings yet
- StatDocument94 pagesStatNantiwa NaulsreeNo ratings yet
- การวิเคราะห์ความสัมพันธ์ระหว่างตัวแปรเชิงกลุ่มDocument132 pagesการวิเคราะห์ความสัมพันธ์ระหว่างตัวแปรเชิงกลุ่มapi-3720369100% (2)
- บทที่ 11 สถิติเชิงอ้างอิงDocument47 pagesบทที่ 11 สถิติเชิงอ้างอิงLé PenhNo ratings yet
- StatDocument4 pagesStatรุ่งธิดา บัวเปลือยNo ratings yet
- สรุปสูตรคณิตศาสตรเพิ่มเติม ม456 PDFDocument44 pagesสรุปสูตรคณิตศาสตรเพิ่มเติม ม456 PDFรัชฎาพร พิสัยพันธุ์100% (1)
- กสพท 56Document5 pagesกสพท 56benz17716No ratings yet
- บทที่ 9การวิเคราะห์ความแปรปรวนDocument28 pagesบทที่ 9การวิเคราะห์ความแปรปรวนSatit YousatitNo ratings yet
- บทที่ 9การวิเคราะห์ความแปรปรวนDocument28 pagesบทที่ 9การวิเคราะห์ความแปรปรวนjariya.attNo ratings yet
- 9การวิเคราะห์ความแปรปรวนแบบทางเดียว 660426Document7 pages9การวิเคราะห์ความแปรปรวนแบบทางเดียว 660426Dodora EmonNo ratings yet
- บทที่ 1 ความคลาดเคลื่อน - 3Document12 pagesบทที่ 1 ความคลาดเคลื่อน - 3Thanapong LanwongNo ratings yet
- บทที่ 4Document30 pagesบทที่ 4MinGy WongthanuwatNo ratings yet
- ใบงานคณิตศาสตร์เพิ่มเติม 1 2565Document50 pagesใบงานคณิตศาสตร์เพิ่มเติม 1 2565Chonnatee PuaseeNo ratings yet
- เมทริกซ์Document12 pagesเมทริกซ์oil.saensuwanNo ratings yet
- E 0 B 980 e 0 B 8 A 5 e 0 B 988 e 0 B 8 A 13Document29 pagesE 0 B 980 e 0 B 8 A 5 e 0 B 988 e 0 B 8 A 13Mooksuda BumrungdilokNo ratings yet
- YlvkDocument71 pagesYlvkSurayos SopitpongNo ratings yet
- ปริมาณทางฟิสิกส์Document4 pagesปริมาณทางฟิสิกส์Sunaree M. Chinnarat0% (1)
- Lec 567730 Lesson 08Document30 pagesLec 567730 Lesson 08mahatta mahattanakulNo ratings yet
- การวิเคราะห์การถดถอย (Regression analysis) การวิเคราะห์สหส ัมพ ันธ์ (Correlation analysis)Document12 pagesการวิเคราะห์การถดถอย (Regression analysis) การวิเคราะห์สหส ัมพ ันธ์ (Correlation analysis)ซานต้า สมศักดิ์No ratings yet
- E0b8ade0b89be0b8b5 54Document19 pagesE0b8ade0b89be0b8b5 54Wann JinjerNo ratings yet
- Chapter 2Document37 pagesChapter 2GedInNo ratings yet
- บทที่ 1 การดำเนินการและการแก้ปัญหาทางคณิตศาสตร์Document25 pagesบทที่ 1 การดำเนินการและการแก้ปัญหาทางคณิตศาสตร์3. กนิษฐาNo ratings yet
- ระบบจำนวนจริงDocument49 pagesระบบจำนวนจริงWilailak LaithaisongNo ratings yet
- เอกสารประกอบการเรียน การวิเคราะห์ข้อมูลทางรัฐศาสตร์ บทที่ 5Document33 pagesเอกสารประกอบการเรียน การวิเคราะห์ข้อมูลทางรัฐศาสตร์ บทที่ 5Somporn KiawjanNo ratings yet
- การแDocument43 pagesการแSeree ThakulpasuthipNo ratings yet
- Matlab Math THDocument27 pagesMatlab Math THspinyaNo ratings yet
- Screenshot 2566-06-19 at 10.33.47Document89 pagesScreenshot 2566-06-19 at 10.33.47CHOMPOO CHOMPOONo ratings yet
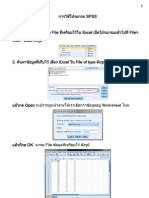
- การใช้โปรแกรม SPSSDocument29 pagesการใช้โปรแกรม SPSSธานินทร์ ทองกาล100% (1)
- Exponential and Log2Document11 pagesExponential and Log2Punnong Tutor100% (4)
- ใบความรู้เลขยกกำลังDocument11 pagesใบความรู้เลขยกกำลังคนสวย รวยเฮงNo ratings yet
- ใบความรู้เลขยกกำลังDocument11 pagesใบความรู้เลขยกกำลังNunthawun KhoomthongNo ratings yet
- ใบความรู้เลขยกกำลังDocument11 pagesใบความรู้เลขยกกำลังคนสวย รวยเฮงNo ratings yet
- Biostatistics ชีวสถิติDocument73 pagesBiostatistics ชีวสถิติThiwaporn Pan100% (1)
- 1854 1Document12 pages1854 1sujintara khemlangNo ratings yet
- 1854 1Document12 pages1854 1sujintara khemlangNo ratings yet
- 1854 1Document12 pages1854 1sujintara khemlangNo ratings yet
- แบบฝึกหัดเสริมครั้งที่2Document7 pagesแบบฝึกหัดเสริมครั้งที่2veerapong.lNo ratings yet
- Prob Stat 02 Part3Document105 pagesProb Stat 02 Part3Pichai NiammuneeNo ratings yet
- Stat 10 AnovaDocument60 pagesStat 10 AnovaSirinobporn BangjabNo ratings yet
- Maximum Likelihood EstimatorDocument12 pagesMaximum Likelihood Estimatorkrishy19No ratings yet
- บทที่4 การทดสอบสมมติฐานDocument50 pagesบทที่4 การทดสอบสมมติฐานrawichNo ratings yet
- เอกสารอบรมครูเรื่องดอกเบี้ยDocument45 pagesเอกสารอบรมครูเรื่องดอกเบี้ยonewinny winnyNo ratings yet
- 1. 3 การวัดการกระจายของข้อมูล (measure of dispersion or data)Document22 pages1. 3 การวัดการกระจายของข้อมูล (measure of dispersion or data)Kim SureeratNo ratings yet
- เอกสารทบทวน เลขยกกำลัง เอกนามพหุนาม การแยกตัวประกอบของพหุนามDocument51 pagesเอกสารทบทวน เลขยกกำลัง เอกนามพหุนาม การแยกตัวประกอบของพหุนามนฤพนธ์ สายเสมา50% (2)
- ลำดับและอนุกรมอนันต์ 1Document66 pagesลำดับและอนุกรมอนันต์ 1นายฉัชวา ไขเหลาคำNo ratings yet
- 001 ใบงานหน่วยการเรียนรู้ที่ 1 23 - 28Document6 pages001 ใบงานหน่วยการเรียนรู้ที่ 1 23 - 28Chaiyarit PhromkhamNo ratings yet
- UntitledDocument141 pagesUntitled014 จนัสธา ลาภยิ่งยงNo ratings yet
- บทที่5 อธิบายข้อ2Document27 pagesบทที่5 อธิบายข้อ2Chonrakorn LungpanyaNo ratings yet
- บทที่ 4 การออกแบบการทดลองทากูชิ PDFDocument26 pagesบทที่ 4 การออกแบบการทดลองทากูชิ PDFณัฐพล บุญใสNo ratings yet
- บทที่ 4 การออกแบบการทดลองทากูชิ PDFDocument26 pagesบทที่ 4 การออกแบบการทดลองทากูชิ PDFณัฐพล บุญใสNo ratings yet
- ความสัมพันธ์เชิงฟังก์ชันDocument6 pagesความสัมพันธ์เชิงฟังก์ชันสุทธิพงษ์ พึ่งเพ็ง50% (2)
- แผนการจัดการเรียนรู้เรื่องระบบสมการเชิงเส้นสองตัวแปรDocument43 pagesแผนการจัดการเรียนรู้เรื่องระบบสมการเชิงเส้นสองตัวแปรSiripun Juntanon0% (1)
- การกระจายสัมบูรณ์Document6 pagesการกระจายสัมบูรณ์ญาณิศา รอดจันทึก 6109655149No ratings yet
- การทดลองที่ 3 การแกว่งอย่างง่ายDocument9 pagesการทดลองที่ 3 การแกว่งอย่างง่ายSun LohasaptaweeNo ratings yet
- RemovedDocument19 pagesRemovedChanchiraphon KaewmeeNo ratings yet