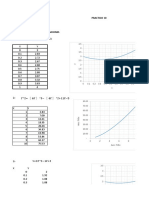
You might also like
- MA 262, Spring 2018, Midterm 2 Version 01 (Green)Document7 pagesMA 262, Spring 2018, Midterm 2 Version 01 (Green)joshuarroldanNo ratings yet
- Assignment MatlabDocument10 pagesAssignment MatlabRaj AryanNo ratings yet
- Matlab Assignment: INSTR F243: Signal & SystemsDocument10 pagesMatlab Assignment: INSTR F243: Signal & SystemsRaj AryanNo ratings yet
- Ecgr 4122 Test 2 Take Home Part v2Document2 pagesEcgr 4122 Test 2 Take Home Part v2rhill55_911701980No ratings yet
- Ee225 Lab 2Document10 pagesEe225 Lab 2Sherlin Chand100% (1)
- Exercícios Cap 1-6Document25 pagesExercícios Cap 1-6rodrigo.felix17012002No ratings yet
- FDMcodeDocument9 pagesFDMcodeViswanath KapavarapuNo ratings yet
- Binary Numbers Quiz ExerciseDocument2 pagesBinary Numbers Quiz ExerciseBryton Angelevski100% (1)
- Mid Sem Exam 2021-22Document2 pagesMid Sem Exam 2021-22N Rabindra PatraNo ratings yet
- CALFEM Mesh Module ManualDocument28 pagesCALFEM Mesh Module ManualJohan Lorentzon100% (1)
- Determinants Module OverviewDocument5 pagesDeterminants Module OverviewAlvin DairoNo ratings yet
- MARKOV CHAINSDocument7 pagesMARKOV CHAINSKeshi AngelNo ratings yet
- Row Reduced Echelon Form (RREF) ContinuedDocument3 pagesRow Reduced Echelon Form (RREF) ContinuedRAJ MEENANo ratings yet
- Referat: Lucrarea de Laborator nr.3Document7 pagesReferat: Lucrarea de Laborator nr.3Mike BrashNo ratings yet
- Quiz 2Document3 pagesQuiz 2TheMaddox5000100% (1)
- Fuzzylogic ExamDocument2 pagesFuzzylogic ExamAlberto Antonio Garcia GonzalezNo ratings yet
- Prelab Exp6 2103Document4 pagesPrelab Exp6 2103امجد ابو حسانNo ratings yet
- PracticoDocument6 pagesPracticoFranz Oscar AicaSotoNo ratings yet
- Matrices Task 1: Type and Order of MatricesDocument1 pageMatrices Task 1: Type and Order of Matricesmaju mundurNo ratings yet
- Mat RiceDocument46 pagesMat RiceSir Kay SwissNo ratings yet
- Chapter Two Solution of Nonlinear EquationsDocument2 pagesChapter Two Solution of Nonlinear EquationsMohammed al-mashabiNo ratings yet
- Digital Image Processing ECE 533 Assignment 4 Due Date: March 11, in ClassDocument7 pagesDigital Image Processing ECE 533 Assignment 4 Due Date: March 11, in ClassEdo Black After LightNo ratings yet
- Calibration CurveDocument13 pagesCalibration Curvecinvehbi711No ratings yet
- Book 1Document10 pagesBook 1sakshita palNo ratings yet
- Binomial Newton (English and Indonesian Languange)Document4 pagesBinomial Newton (English and Indonesian Languange)basir annas sidiqNo ratings yet
- STA3710 ASSIGNMENT 01Document5 pagesSTA3710 ASSIGNMENT 01Flossie SedibeNo ratings yet
- Optimal Staffing LPDocument32 pagesOptimal Staffing LPcarlos fernandezNo ratings yet
- Grade 5 Second Periodical TestDocument8 pagesGrade 5 Second Periodical TestESSU Societas Discipulorum Legis100% (2)
- Problems 1Document2 pagesProblems 1Jawaad KhanNo ratings yet
- ZCT191 Lab Report Error AnalysisDocument27 pagesZCT191 Lab Report Error AnalysisYasriq Bin YahyaNo ratings yet
- 화학공정계산 4판 솔루션 RicharDocument244 pages화학공정계산 4판 솔루션 Richar고영준No ratings yet
- Fundamentals of Digital Audio Processing: Federico Avanzini and Giovanni de PoliDocument46 pagesFundamentals of Digital Audio Processing: Federico Avanzini and Giovanni de PoliNafi NafiNo ratings yet
- Matlab Practice Set-1Document3 pagesMatlab Practice Set-1Badri TamangNo ratings yet
- Curve Fit of Amplitude vs X-ValueDocument7 pagesCurve Fit of Amplitude vs X-ValueLunaNo ratings yet
- In-Class Assignment 2Document4 pagesIn-Class Assignment 2Có Tên KhôngNo ratings yet
- Sheet 09Document2 pagesSheet 09eir.gnNo ratings yet
- LA Exercises 2Document23 pagesLA Exercises 2Tiên ThủyNo ratings yet
- KakskqDocument1 pageKakskqDiego Santillan PiconNo ratings yet
- Tutorial 3Document6 pagesTutorial 3Snehita NNo ratings yet
- Midterm 1 SolnDocument6 pagesMidterm 1 Solnloop arrayNo ratings yet
- Control ChartDocument43 pagesControl ChartSRI RAMNo ratings yet
- Chapter 3 - Determinants and DiagonalizationDocument59 pagesChapter 3 - Determinants and DiagonalizationNam NguyễnNo ratings yet
- What To Do If The Sample Matrix Interferes?: Standard AdditionsDocument7 pagesWhat To Do If The Sample Matrix Interferes?: Standard AdditionsmuratNo ratings yet
- University of Aberdeen Department of Mathematical Sciences: Author IC Date 4.10.04 CodeDocument4 pagesUniversity of Aberdeen Department of Mathematical Sciences: Author IC Date 4.10.04 CodeAlhilali ZiyadNo ratings yet
- Final 2015 WDocument4 pagesFinal 2015 WViệt NguyễnNo ratings yet
- Cantor PDFDocument13 pagesCantor PDFCan Ellik100% (1)
- Final Linear Algebra Spring 2012 SolutionDocument6 pagesFinal Linear Algebra Spring 2012 SolutionNajim KarkanawiNo ratings yet
- ACFrOgCbr2vbzgU6C1 nGGzKB7HovQEeleJNf8lauJ2jRTQOivuXMIjmzB43GUH5Ux83Uog7T k-9Kt9Liu-LNCjldC 0yRRLsIKr fBabdYspbSezF-U-K5q 9jrYX9zYghqCucZKRbvx-I0Xn6Document2 pagesACFrOgCbr2vbzgU6C1 nGGzKB7HovQEeleJNf8lauJ2jRTQOivuXMIjmzB43GUH5Ux83Uog7T k-9Kt9Liu-LNCjldC 0yRRLsIKr fBabdYspbSezF-U-K5q 9jrYX9zYghqCucZKRbvx-I0Xn6oliver abramsNo ratings yet
- Sem 3 - MajorDocument12 pagesSem 3 - MajorShashank Mani TripathiNo ratings yet
- Copia de DESRIPIADOR - Y - LONG - TRANSICIONDocument6 pagesCopia de DESRIPIADOR - Y - LONG - TRANSICIONKatherine OñateNo ratings yet
- Advanced 6 Grade Placement Test For CSRMSDocument8 pagesAdvanced 6 Grade Placement Test For CSRMSMazen FerigNo ratings yet
- Referat: Lucrarea de Laborator nr.3Document7 pagesReferat: Lucrarea de Laborator nr.3Mike BrashNo ratings yet
- IE 325 HW 4 SolutionsDocument8 pagesIE 325 HW 4 SolutionsOsman ŞentürkNo ratings yet
- Statistical Process Control Chart GuideDocument28 pagesStatistical Process Control Chart GuideAli ElattarNo ratings yet
- Multiple Choice Question 1 Q.No. AnswerDocument2 pagesMultiple Choice Question 1 Q.No. Answerjames_imchNo ratings yet
- Multiple Choice Question 1 Q.No. AnswerDocument2 pagesMultiple Choice Question 1 Q.No. Answerjames_imchNo ratings yet
- Multiple Choice Question 1 Q.No. AnswerDocument2 pagesMultiple Choice Question 1 Q.No. Answerjames_imchNo ratings yet
- Daw Thin Thin Maw, ML2080, Assignment 5: Multiplot For The Curves FunctionsDocument5 pagesDaw Thin Thin Maw, ML2080, Assignment 5: Multiplot For The Curves FunctionsChit Khone Cho TharNo ratings yet
- 11 Miscellaneous ExercisesDocument7 pages11 Miscellaneous Exerciseslikhona madasaNo ratings yet
- Let's Practise: Maths Workbook Coursebook 6From EverandLet's Practise: Maths Workbook Coursebook 6No ratings yet
- Assembler DirectivesDocument10 pagesAssembler DirectivesPrabir Das100% (1)
- Lecture 7Document23 pagesLecture 7jagdish750No ratings yet
- CS23032Document11 pagesCS23032jagdish750No ratings yet
- Lect-11-Backup Recovery SystemDocument10 pagesLect-11-Backup Recovery Systemjagdish750No ratings yet
- 020128Document8 pages020128emili3326No ratings yet
- System Programming AssemblersDocument9 pagesSystem Programming Assemblersjagdish750No ratings yet
- 12imagetransforms 120321054452 Phpapp01Document75 pages12imagetransforms 120321054452 Phpapp01jagdish750No ratings yet
- Macro Processor StudyDocument3 pagesMacro Processor Studyjagdish750No ratings yet
- Lecture 8Document26 pagesLecture 8jagdish750No ratings yet
- LoaderDocument13 pagesLoaderjagdish750No ratings yet
- NovLight SeemaDocument1 pageNovLight SeemaRajesh SirsathNo ratings yet
- Lecture 26Document20 pagesLecture 26jagdish750No ratings yet
- LogisticsDocument40 pagesLogisticsawadhesh.kumarNo ratings yet
- Solution EigenDocument4 pagesSolution EigenUsman Ghafoor Chaudhary100% (1)
- Updated E3 Chap 03Document44 pagesUpdated E3 Chap 03Devika RankhambeNo ratings yet
- Assembler, Linker and LoaderDocument6 pagesAssembler, Linker and LoaderSyed Shiyaz MirzaNo ratings yet
- SL-V Assignment QuestionsDocument2 pagesSL-V Assignment Questionsjagdish750No ratings yet
- Assignment 1 - ER ModelDocument5 pagesAssignment 1 - ER Modeljagdish750No ratings yet
- Design and Analysis AlgorithmDocument13 pagesDesign and Analysis Algorithmjagdish750No ratings yet
- CS6402 Algorithm Design Analysis Question BankDocument12 pagesCS6402 Algorithm Design Analysis Question BankKpsmurugesan KpsmNo ratings yet
- Set C: Department of Information Technology (Academic Year - 2018-19) Unit Test - IDocument3 pagesSet C: Department of Information Technology (Academic Year - 2018-19) Unit Test - Ijagdish750No ratings yet
- Unit-II RE Question BankDocument4 pagesUnit-II RE Question Bankjagdish750No ratings yet
- SL-V Assignment QuestionsDocument2 pagesSL-V Assignment Questionsjagdish750No ratings yet
- SL-V Assignment QuestionsDocument2 pagesSL-V Assignment Questionsjagdish750No ratings yet
- Theory of Computation Regular ExpressionsDocument176 pagesTheory of Computation Regular Expressionsjagdish750No ratings yet
- Unit-II RE Question BankDocument4 pagesUnit-II RE Question Bankjagdish750No ratings yet
- SL-V Assignment QuestionsDocument2 pagesSL-V Assignment Questionsjagdish750No ratings yet
- Unit-I FSM Question BankDocument6 pagesUnit-I FSM Question Bankjagdish750No ratings yet
- FCP 4 Arrays and StringsDocument17 pagesFCP 4 Arrays and Stringsjagdish750No ratings yet
- PMRI Learning Improves Statistical ReasoningDocument41 pagesPMRI Learning Improves Statistical ReasoningSyaputri AwaliaNo ratings yet
- Syllabus of M.tech Transportation EngineeringDocument50 pagesSyllabus of M.tech Transportation EngineeringSamarth M.R SamNo ratings yet
- Gama ChiDocument33 pagesGama ChiMeutia SilviNo ratings yet
- Lecture 1: Introduction To Uncertainty Quantification: TodayDocument12 pagesLecture 1: Introduction To Uncertainty Quantification: TodayNolan GutierrezNo ratings yet
- Bike Sharing AnalysisDocument4 pagesBike Sharing AnalysisDevansh SharmaNo ratings yet
- HypothesisDocument25 pagesHypothesisShiv SuriNo ratings yet
- Journal - Abdullah Baasith Ataro GultomDocument4 pagesJournal - Abdullah Baasith Ataro GultomMelissa Indah FiantyNo ratings yet
- A Simple Technique To Assess Vertical Dimension of OcclusionDocument4 pagesA Simple Technique To Assess Vertical Dimension of OcclusionanakNo ratings yet
- Impact of K-Pop Music On The Academic PDocument29 pagesImpact of K-Pop Music On The Academic Pdave tayron paggao100% (1)
- ReviewDocument33 pagesReviewMariaNo ratings yet
- A Tutorial on Data Reduction with Linear Discriminant Analysis (LDADocument47 pagesA Tutorial on Data Reduction with Linear Discriminant Analysis (LDAAiz DanNo ratings yet
- Thirty Years of Geometric Morphometrics: Achievements, Challenges, and The Ongoing Quest For Biological MeaningfulnessDocument30 pagesThirty Years of Geometric Morphometrics: Achievements, Challenges, and The Ongoing Quest For Biological MeaningfulnessalbgomezNo ratings yet
- Employees in BankDocument41 pagesEmployees in BankKasturiNo ratings yet
- Choosing the Right Statistical TestDocument1 pageChoosing the Right Statistical TestfrrreshNo ratings yet
- At 2511 Determining The Extent andDocument53 pagesAt 2511 Determining The Extent andawesome bloggersNo ratings yet
- Time Series Analysis and ForecastingDocument60 pagesTime Series Analysis and ForecastingAdil Bin KhalidNo ratings yet
- Sampling Distribution of Sample MeansDocument17 pagesSampling Distribution of Sample MeansVicente MarkNo ratings yet
- Emotional Intelligence Improves Project SuccessDocument9 pagesEmotional Intelligence Improves Project SuccessFajr MirNo ratings yet
- Sathish Yellanki: Skyess: in Association WithDocument12 pagesSathish Yellanki: Skyess: in Association WithSWATINo ratings yet
- When Should You Use The Spearman's Rank-Order Correlation?Document6 pagesWhen Should You Use The Spearman's Rank-Order Correlation?MClarissaENo ratings yet
- MATLAB by Examples - Starting With Neural Network in MatlabDocument6 pagesMATLAB by Examples - Starting With Neural Network in Matlabzhee_pirateNo ratings yet
- Liceo de Cagayan University: Chili Pepper (Capsicum Frutescens) As Chocolate CandyDocument33 pagesLiceo de Cagayan University: Chili Pepper (Capsicum Frutescens) As Chocolate CandyRaven EscabusaNo ratings yet
- Ain Drain From Pakistan An Empirical AnalysisDocument27 pagesAin Drain From Pakistan An Empirical Analysisrizwana rafiqNo ratings yet
- Frequency Distributions: Essentials of Statistics For The Behavioral SciencesDocument45 pagesFrequency Distributions: Essentials of Statistics For The Behavioral SciencesOshratNo ratings yet
- Activity10 Conditional ProbabilityDocument2 pagesActivity10 Conditional ProbabilityPragyan KumarNo ratings yet
- Social Science-Course OutlineDocument6 pagesSocial Science-Course Outlinekenha2000No ratings yet
- Statistics A ReviewDocument47 pagesStatistics A ReviewSinner For BTSNo ratings yet
- Q Bank 2010 WITH AnswersDocument119 pagesQ Bank 2010 WITH Answersazum77100% (7)
- One Way ANOVA Post Hoc Tests in ExcelDocument3 pagesOne Way ANOVA Post Hoc Tests in ExcelSamuNavarroDNo ratings yet
- Meditz v. City of Newark, 658 F.3d 364, 3rd Cir. (2011)Document21 pagesMeditz v. City of Newark, 658 F.3d 364, 3rd Cir. (2011)Scribd Government DocsNo ratings yet