You might also like
- UPCAT 2019 ReviewerDocument4 pagesUPCAT 2019 ReviewerCarl William YabutNo ratings yet
- Globalization and The Asia Pacific and South AsiaDocument14 pagesGlobalization and The Asia Pacific and South AsiaPH100% (1)
- Final Examination Puerto Galera National High School - San Isidro ExtensionDocument4 pagesFinal Examination Puerto Galera National High School - San Isidro ExtensionJennifer MagangoNo ratings yet
- 2244 Sample MidtermDocument8 pages2244 Sample Midtermsamnas100No ratings yet
- Second Quarter School Year 2020 - 2021 Statistics and Probability Answer SheetDocument10 pagesSecond Quarter School Year 2020 - 2021 Statistics and Probability Answer SheetLynette LicsiNo ratings yet
- Statistics and Probability 4th QEDocument5 pagesStatistics and Probability 4th QEDaniel BerdidaNo ratings yet
- What Is SAP BTP?Document5 pagesWhat Is SAP BTP?PALURU GIRIDHARNo ratings yet
- Confidence Intervals For Proportions and Means Practice PDFDocument2 pagesConfidence Intervals For Proportions and Means Practice PDFAnna AnnaNo ratings yet
- Unit 6 - Activity 6 - Confidence Intervals WorksheetDocument3 pagesUnit 6 - Activity 6 - Confidence Intervals WorksheetNidhi VyasNo ratings yet
- Performance Task Involving Z T and PDocument4 pagesPerformance Task Involving Z T and PRose PinedaNo ratings yet
- MATHEDADocument4 pagesMATHEDAChristian John Paul LijayanNo ratings yet
- Ce 023 Eda Module 4Document5 pagesCe 023 Eda Module 4Roydon Jude SamudioNo ratings yet
- Applied Statistics From Bivariate Through Multivariate Techniques 2nd Edition Warner Test BankDocument6 pagesApplied Statistics From Bivariate Through Multivariate Techniques 2nd Edition Warner Test BankGregWilsonjpdksNo ratings yet
- REVIEWER 30 ItemsDocument2 pagesREVIEWER 30 ItemsEunice Kyla MapisaNo ratings yet
- Chemistry Unit 8 ReviewDocument5 pagesChemistry Unit 8 ReviewKhai NguyenNo ratings yet
- I. Multiple Choice: (10 Pts. Ea.) A 1. A Statistical Inference IsDocument7 pagesI. Multiple Choice: (10 Pts. Ea.) A 1. A Statistical Inference IsSamantha SamanthaNo ratings yet
- Kode B: Final Exam Second Semester 2019/2020Document12 pagesKode B: Final Exam Second Semester 2019/2020reviandiramadhan100% (1)
- Preliminary Edition of Statistics Learning From Data 1st Edition Roxy Peck Test BankDocument11 pagesPreliminary Edition of Statistics Learning From Data 1st Edition Roxy Peck Test Bankbaluster.abusive.kzegx100% (20)
- Practical Business Statistics 7th Edition Siegel Solutions ManualDocument18 pagesPractical Business Statistics 7th Edition Siegel Solutions Manualfumingmystich6ezb100% (23)
- Chapter 6 Section 1 Homework A: 6.10 Margin of Error and The Confidence IntervalDocument4 pagesChapter 6 Section 1 Homework A: 6.10 Margin of Error and The Confidence IntervalManishi GuptaNo ratings yet
- MATH 114 Module 7 All AnswersDocument22 pagesMATH 114 Module 7 All AnswersJohn Arvin EscoteNo ratings yet
- STA 2023 Unit 3 Shell Notes (Chapter 6 - 7)Document36 pagesSTA 2023 Unit 3 Shell Notes (Chapter 6 - 7)UyenNo ratings yet
- Lesson 2 Computing Interval Estimates For The Population MeanDocument24 pagesLesson 2 Computing Interval Estimates For The Population MeanJoshua DoronilaNo ratings yet
- Estimating With Confidence: Ms. Plata AP StatisticsDocument31 pagesEstimating With Confidence: Ms. Plata AP StatisticsveronicaplataNo ratings yet
- 13C2 - PowerPoint - Data Inferences - Day 2Document9 pages13C2 - PowerPoint - Data Inferences - Day 2Peter LeeNo ratings yet
- File 3Document4 pagesFile 3Ahmed EssamNo ratings yet
- Homework 5Document2 pagesHomework 5Potatoes123No ratings yet
- STAT 30100. Workbook 7 1Document5 pagesSTAT 30100. Workbook 7 1A KNo ratings yet
- Curriculum Module 5 QuestionsDocument9 pagesCurriculum Module 5 QuestionsEmin SalmanovNo ratings yet
- Problem SetDocument23 pagesProblem SetMaricel SalamatNo ratings yet
- Ebook Elementary Statistics A Step by Step Approach 7Th Edition Bluman Test Bank Full Chapter PDFDocument33 pagesEbook Elementary Statistics A Step by Step Approach 7Th Edition Bluman Test Bank Full Chapter PDFTraciLewispwng100% (10)
- Practice Problemschp 5Document4 pagesPractice Problemschp 5mohammadsulaiman811No ratings yet
- Question of Chapter 8 StaticsDocument7 pagesQuestion of Chapter 8 Staticsحمزہ قاسم کاھلوں جٹNo ratings yet
- Acot103 Final ExamDocument8 pagesAcot103 Final ExamNicole Anne Santiago SibuloNo ratings yet
- Chapter 8 - QuizDocument10 pagesChapter 8 - QuizTrang NguyễnNo ratings yet
- Eco240 HW2Document3 pagesEco240 HW2MichelleLeeNo ratings yet
- Q2 StatsDocument38 pagesQ2 Statskp.cleofasNo ratings yet
- 6.1 HWDocument3 pages6.1 HWcocochannel2016No ratings yet
- 10 HW Assignment BiostatDocument4 pages10 HW Assignment BiostatjhonNo ratings yet
- Chapter 7Document25 pagesChapter 7Jaysie OlimpiadaNo ratings yet
- Management QuizzDocument124 pagesManagement QuizzManish GuptaNo ratings yet
- Hawa Gen Basiliso Module 1Document27 pagesHawa Gen Basiliso Module 1hawa basilisoNo ratings yet
- New VisonDocument5 pagesNew VisonNil MukherjeeNo ratings yet
- ACTM 2017 Regional Statistics and Key A 1Document15 pagesACTM 2017 Regional Statistics and Key A 1JamesNo ratings yet
- M1112SP IIIh 3Document3 pagesM1112SP IIIh 3ALJON TABUADANo ratings yet
- Math 131 Pencastreview3!8!11Document10 pagesMath 131 Pencastreview3!8!11Ahmed El KhateebNo ratings yet
- Q Ch07Document10 pagesQ Ch07Khaleel AbdoNo ratings yet
- 5: Introduction To Estimation Review Questions and ExercisesDocument4 pages5: Introduction To Estimation Review Questions and ExercisesMujahid AliNo ratings yet
- Problemas Sugeridos PT 2Document22 pagesProblemas Sugeridos PT 2Paula SofiaNo ratings yet
- Chapter8 StatsDocument10 pagesChapter8 StatsPoonam NaiduNo ratings yet
- Biostat To AnswerDocument3 pagesBiostat To AnswerSamantha ArdaNo ratings yet
- Full Download Test Bank For Elementary Statistics 7Th Edition Ron Larson Betsy Farber PDFDocument37 pagesFull Download Test Bank For Elementary Statistics 7Th Edition Ron Larson Betsy Farber PDFcharles.weiss919100% (15)
- 103 1統計學期末會考考題Document5 pages103 1統計學期末會考考題smallbeariceNo ratings yet
- Exam3 spr20Document7 pagesExam3 spr20Auguste RiedlNo ratings yet
- Newbold Sbe8 Tif Ch07Document42 pagesNewbold Sbe8 Tif Ch07Tuna Altıner100% (1)
- Chapter 9 Estimation From Sampling DataDocument23 pagesChapter 9 Estimation From Sampling Datalana del reyNo ratings yet
- ADMS 2320 Chapter 2 Questions PDFDocument4 pagesADMS 2320 Chapter 2 Questions PDFpranta sahaNo ratings yet
- Ebook Elementary Statistics A Step by Step Approach 8Th Edition Bluman Test Bank Full Chapter PDFDocument34 pagesEbook Elementary Statistics A Step by Step Approach 8Th Edition Bluman Test Bank Full Chapter PDFTraciLewispwng100% (10)
- Estimation Hypothesis Testing: Decisions InferencesDocument8 pagesEstimation Hypothesis Testing: Decisions InferencesLaylaNo ratings yet
- Ch. 9 Multiple Choice Review Questions: 1.96 B) 1.645 C) 1.699 D) 0.90 E) 1.311Document5 pagesCh. 9 Multiple Choice Review Questions: 1.96 B) 1.645 C) 1.699 D) 0.90 E) 1.311payal khatriNo ratings yet
- Session 5. Confidence Interval of The Mean When SD Is Known (18-22)Document5 pagesSession 5. Confidence Interval of The Mean When SD Is Known (18-22)Roldan Soriano CardonaNo ratings yet
- Science and Technology PaperDocument3 pagesScience and Technology PaperPHNo ratings yet
- Part 1 - Intro To Engineering Management PDFDocument30 pagesPart 1 - Intro To Engineering Management PDFPHNo ratings yet
- EMG22 Seminar Assessment Report Template PDFDocument1 pageEMG22 Seminar Assessment Report Template PDFPHNo ratings yet
- Module Exam 1 - General Concepts and Historical DevelopmentsDocument1 pageModule Exam 1 - General Concepts and Historical DevelopmentsPHNo ratings yet
- MRR 1 - padillaRA - A3Document2 pagesMRR 1 - padillaRA - A3Ivan Mark LucasNo ratings yet
- Ternary Diagrams in ExcelDocument9 pagesTernary Diagrams in ExcelDRx Sonali TareiNo ratings yet
- 2019 Spring Che338 - Homework #6 Save Your Solution As A PDF File (Maximum Size 10 MB) and Submit On Moodle by Midnight 4/5 (Friday) Problem 1Document13 pages2019 Spring Che338 - Homework #6 Save Your Solution As A PDF File (Maximum Size 10 MB) and Submit On Moodle by Midnight 4/5 (Friday) Problem 1PHNo ratings yet
- Bank Codes PHDocument2 pagesBank Codes PHNida BeeNo ratings yet
- The Issues of Disputes BetweenDocument2 pagesThe Issues of Disputes BetweenPHNo ratings yet
- Solutions For Statistics and Probability For EngineersDocument6 pagesSolutions For Statistics and Probability For EngineersPHNo ratings yet
- Interphase Mass TransferDocument29 pagesInterphase Mass TransferPHNo ratings yet
- Understanding The SelfDocument24 pagesUnderstanding The SelfPHNo ratings yet
- Murder at Mayfare ProblemDocument4 pagesMurder at Mayfare ProblemPHNo ratings yet
- Murder at The MayfairDocument6 pagesMurder at The MayfairTony MedranoNo ratings yet
- Enthalpy Moles Notes PDFDocument24 pagesEnthalpy Moles Notes PDFPHNo ratings yet
- Question 1Document1 pageQuestion 1PHNo ratings yet
- U6 Deck1h PDFDocument5 pagesU6 Deck1h PDFPHNo ratings yet
- 291 L2 PDFDocument26 pages291 L2 PDFPHNo ratings yet
- Enthalpy Moles Notes PDFDocument24 pagesEnthalpy Moles Notes PDFPHNo ratings yet
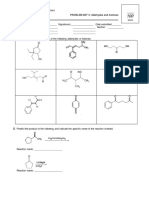
- Organic Chemistry Problem SetDocument2 pagesOrganic Chemistry Problem SetPHNo ratings yet
- DS100-3 B9 MP2 GroupNo7Document12 pagesDS100-3 B9 MP2 GroupNo7PHNo ratings yet
- RecystallizationDocument5 pagesRecystallizationcryzelduh100% (1)
- See Catalog: Get A QuoteDocument4 pagesSee Catalog: Get A QuoteahnafNo ratings yet
- Mercedes Wis en - Asra - Data - SpoolerDocument91 pagesMercedes Wis en - Asra - Data - SpoolerrtamercedesNo ratings yet
- Harman Kardon AVR 354 Part 3 Service ManualDocument79 pagesHarman Kardon AVR 354 Part 3 Service ManualJayceemikelNo ratings yet
- View Full VersionDocument14 pagesView Full VersionHadi SusenoNo ratings yet
- CV TemplateDocument1 pageCV TemplateYuliethcamo100% (1)
- RHEL 8.5 - Generating SOS Reports For Technical SupportDocument26 pagesRHEL 8.5 - Generating SOS Reports For Technical SupportITTeamNo ratings yet
- CHS - Lesson 1 - QuestionsDocument14 pagesCHS - Lesson 1 - QuestionsZayn MacasalongNo ratings yet
- Tables SapDocument21 pagesTables SapLos VizuetinesNo ratings yet
- CT002-3-2 AI Methods: Swarm Intelligence, Technique and application-IIDocument29 pagesCT002-3-2 AI Methods: Swarm Intelligence, Technique and application-IIChester ChongNo ratings yet
- 403 Quick Guide 403 v2 PDFDocument2 pages403 Quick Guide 403 v2 PDFJoaquin Alberto Flores CastroNo ratings yet
- EJE 1 - Technical EnglishDocument15 pagesEJE 1 - Technical Englishjoaquin morelNo ratings yet
- 2022 20231008BP4117Document114 pages2022 20231008BP4117AnkitNo ratings yet
- Interview Test Alfred Sakala 2 TechnicalDocument47 pagesInterview Test Alfred Sakala 2 TechnicalsakalaalfredNo ratings yet
- Vhoucer GratisDocument13 pagesVhoucer GratisakungmujainkuaNo ratings yet
- Project of FMDocument18 pagesProject of FMmamaru bantieNo ratings yet
- Comparative Analysis of Low Power 10T and 14T FullDocument6 pagesComparative Analysis of Low Power 10T and 14T Fullkhaja mohiddienNo ratings yet
- Predictive Analytics Practice ProblemDocument3 pagesPredictive Analytics Practice ProblemRajesh SharmaNo ratings yet
- MC Email SPDocument36 pagesMC Email SPMarkus Suritsch (AT)No ratings yet
- DL DefineDocument19 pagesDL DefineIrvan FirmansyahNo ratings yet
- 036concrete Pre-Placement Check & InspectionDocument1 page036concrete Pre-Placement Check & InspectionKannan MurugesanNo ratings yet
- (GUIDE) Unbrick A Hard Bricked L90 All Varia - LG Optimus L90 PDFDocument1 page(GUIDE) Unbrick A Hard Bricked L90 All Varia - LG Optimus L90 PDFpartidasluisNo ratings yet
- Son-CA - Lec1 - 1 - Computer Abstraction and TechnologyDocument31 pagesSon-CA - Lec1 - 1 - Computer Abstraction and TechnologyVăn NguyễnNo ratings yet
- Lighting Plan L7Document1 pageLighting Plan L7Dani WaskitoNo ratings yet
- BMC Remedy It Service Management 9.0 (PDFDrive)Document282 pagesBMC Remedy It Service Management 9.0 (PDFDrive)Omar EhabNo ratings yet
- CICA CraneSafetyBulletin292useDocument2 pagesCICA CraneSafetyBulletin292useColin TanNo ratings yet
- Organization Transaction Processing System (TDocument15 pagesOrganization Transaction Processing System (TankurchandaniNo ratings yet
- Lesson 8 (10) - Media ConvergenceDocument1 pageLesson 8 (10) - Media ConvergenceRonhielyn AlbisNo ratings yet
- Yamaha Psr-Ew400 SMDocument57 pagesYamaha Psr-Ew400 SMGabriel SaucedoNo ratings yet
- Android Example 1Document71 pagesAndroid Example 1manojschavan6No ratings yet