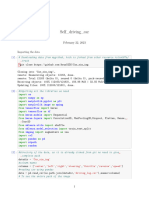
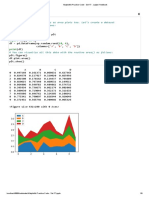
You might also like
- Tarea de ArDocument16 pagesTarea de ArEdwin Cazorla MedinaNo ratings yet
- Amazon Stocks PriceDocument16 pagesAmazon Stocks PriceDineshkumar VhananavarNo ratings yet
- Pronosticos - Ipynb - ColaboratoryDocument13 pagesPronosticos - Ipynb - ColaboratoryFrancisco Javier RESTREPO GRANOBLESNo ratings yet
- Facebook's ProphetDocument10 pagesFacebook's ProphetKyle MurphyNo ratings yet
- Walmart - Sales: Pandas PD Seaborn Sns Numpy NP Matplotlib - Pyplot PLT Matplotlib DatetimeDocument26 pagesWalmart - Sales: Pandas PD Seaborn Sns Numpy NP Matplotlib - Pyplot PLT Matplotlib DatetimeRamaseshu Machepalli100% (1)
- Linear - Regression - Ipynb - ColaboratoryDocument4 pagesLinear - Regression - Ipynb - Colaboratoryavnimote121No ratings yet
- Graphic Design: Keyword Monthly Search (3000)Document7 pagesGraphic Design: Keyword Monthly Search (3000)Engr Mohammad YousufNo ratings yet
- 02-Linear Regression Project - SolutionsDocument12 pages02-Linear Regression Project - SolutionsHellem BiersackNo ratings yet
- Data Vizualization - Jupyter NotebookDocument20 pagesData Vizualization - Jupyter Notebookdimple mahaduleNo ratings yet
- Technologyname Phase2Document20 pagesTechnologyname Phase2vasusam300No ratings yet
- Sunbase Data AssignmentDocument11 pagesSunbase Data Assignmentfanrock281No ratings yet
- PandasDocument21 pagesPandasShubham dattatray koteNo ratings yet
- Practica 9Document24 pagesPractica 92marlenehh2003No ratings yet
- Efficient Python Tricks and Tools For Data ScientistsDocument23 pagesEfficient Python Tricks and Tools For Data ScientistsMaheshBirajdar100% (1)
- Stock AnalysisDocument16 pagesStock AnalysisAbhisek KeshariNo ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- Series4 - Renata Putri HenessaDocument12 pagesSeries4 - Renata Putri HenessaPerfect DarksideNo ratings yet
- Jupyter Notebook Yardlenis Sánchez Act2Document1 pageJupyter Notebook Yardlenis Sánchez Act2NASLYNo ratings yet
- Tugas-Bank-Campaign (1) .Ipynb - ColaboratoryDocument29 pagesTugas-Bank-Campaign (1) .Ipynb - ColaboratoryAlexander TiopanNo ratings yet
- Pa66 ML Exp6Document9 pagesPa66 ML Exp6Pratik ManeNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- CST 383 Start-Up Success Failure - ColaboratoryDocument32 pagesCST 383 Start-Up Success Failure - Colaboratoryapi-596648574No ratings yet
- Advanced Statistics - Project ReportDocument14 pagesAdvanced Statistics - Project ReportRohan Kanungo100% (5)
- Know Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730Document1 pageKnow Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730SHANTI ROKKANo ratings yet
- EDA - Ciclo2022 - 2 - EstadisticaByvariadaDocument9 pagesEDA - Ciclo2022 - 2 - EstadisticaByvariadaRicardo CremaNo ratings yet
- Self Driving Car ProjectDocument20 pagesSelf Driving Car ProjectAli AzfarNo ratings yet
- 1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyDocument50 pages1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyP Venkata Krishna Rao100% (19)
- IMDB Movie Analysis 05 ProjectDocument7 pagesIMDB Movie Analysis 05 ProjectNiraj IngoleNo ratings yet
- IndexDocument1 pageIndexninjamomo546No ratings yet
- Credit Card DefaultDocument30 pagesCredit Card Defaulternest muhasaNo ratings yet
- PembelajaranMesin - Ipynb - ColaboratoryDocument6 pagesPembelajaranMesin - Ipynb - ColaboratoryKhaerul RijalNo ratings yet
- ML0101EN Clas Logistic Reg Churn Py v1Document13 pagesML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- MEE 6070 Data Science and Analytics: Importing Data Using Plotting The Data Checking For LinearityDocument13 pagesMEE 6070 Data Science and Analytics: Importing Data Using Plotting The Data Checking For LinearityKrupaNo ratings yet
- Heart: Our "Goal" Predict The Presence of Heart Disease in The PatientDocument73 pagesHeart: Our "Goal" Predict The Presence of Heart Disease in The Patientaditya b100% (1)
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- Import As Import As Import AsDocument8 pagesImport As Import As Import AsDavid EsparzaArellanoNo ratings yet
- Amazon 1677074169Document15 pagesAmazon 1677074169Disha MittalNo ratings yet
- Tabla de Frecuencias Del Agua: EstadísticaDocument3 pagesTabla de Frecuencias Del Agua: EstadísticaWalter Paulino Quispe TicseNo ratings yet
- EDA and Data CleaningDocument33 pagesEDA and Data CleaningPrithvi NarveNo ratings yet
- Glass ClassificationDocument3 pagesGlass ClassificationSiddharth Tiwari100% (2)
- Actividad Semana 4 - Jupyter NotebookDocument7 pagesActividad Semana 4 - Jupyter NotebookM. Eugenia Barrios100% (1)
- HAMZAKHAWLA - Ipynb - ColaboratoryDocument3 pagesHAMZAKHAWLA - Ipynb - Colaboratoryhamza.ahbachNo ratings yet
- Stock Price Prediction Report - Parth Bathla - 18ECU016Document12 pagesStock Price Prediction Report - Parth Bathla - 18ECU016Parth BathlaNo ratings yet
- Income Qualification Project3Document40 pagesIncome Qualification Project3NikhilNo ratings yet
- New ANN-Copy1Document1 pageNew ANN-Copy1raveendrareddyeeeNo ratings yet
- Modulo 02 - 09: September 28, 2018Document3 pagesModulo 02 - 09: September 28, 2018smithvieiraNo ratings yet
- Four Step ModelDocument8 pagesFour Step Modelnatdanai asaithammakulNo ratings yet
- Data Munging - Ipynb - Colaboratory - Yodhi Adhi SanjayaDocument4 pagesData Munging - Ipynb - Colaboratory - Yodhi Adhi SanjayaadhiNo ratings yet
- Pandas - Jupyter NotebookDocument4 pagesPandas - Jupyter NotebookMaximus AranhaNo ratings yet
- K-Means Clustering Python CodesDocument1 pageK-Means Clustering Python CodesSatish KumarNo ratings yet
- Assistants API in OpenAI-1Document35 pagesAssistants API in OpenAI-1Yussuf AbdirizakNo ratings yet
- BitcoinAnalysis - Ipynb - ColaboratoryDocument12 pagesBitcoinAnalysis - Ipynb - Colaboratoryramihameed2000No ratings yet
- World Happiness ReportDocument7 pagesWorld Happiness ReportMuriloMonteiroNo ratings yet
- Sklearn Tutorial: DNN On Boston DataDocument9 pagesSklearn Tutorial: DNN On Boston DatahopkeinstNo ratings yet
- Sales Forecast: October 9, 2020Document9 pagesSales Forecast: October 9, 2020salnasuNo ratings yet
- Credit Default Practice PDFDocument27 pagesCredit Default Practice PDFSravan100% (1)
- Likert Scales in R - Scale Package Tutorial: ResearchDocument5 pagesLikert Scales in R - Scale Package Tutorial: ResearchAnonymous x1JlRpmvNo ratings yet
- 7 MensurationDocument10 pages7 MensurationBrioNo ratings yet
- B - 59 - SMA - Exp 4Document9 pagesB - 59 - SMA - Exp 4Ritz FernandesNo ratings yet
- LCOE CHILE Ene - 11052401aDocument23 pagesLCOE CHILE Ene - 11052401aLenin AgrinzoneNo ratings yet
- Hammer Strength HDT-MAB Assembly ManualDocument8 pagesHammer Strength HDT-MAB Assembly ManualRida DahmounNo ratings yet
- Analog Circuits - IDocument127 pagesAnalog Circuits - IdeepakpeethambaranNo ratings yet
- Application & Registration Form MSC International Business Management M2Document11 pagesApplication & Registration Form MSC International Business Management M2Way To Euro Mission Education ConsultancyNo ratings yet
- Invoice: Buyer Information Delivery Information Transaction DetailsDocument1 pageInvoice: Buyer Information Delivery Information Transaction DetailsZarida SahdanNo ratings yet
- File System ImplementationDocument35 pagesFile System ImplementationSát Thủ Vô TìnhNo ratings yet
- Persons Digests For 090613Document10 pagesPersons Digests For 090613pyriadNo ratings yet
- Integrated Weed Management 22.11.2021Document8 pagesIntegrated Weed Management 22.11.2021Izukanji KayoraNo ratings yet
- Algebra 1 Vocab CardsDocument15 pagesAlgebra 1 Vocab Cardsjoero51No ratings yet
- T3 Rapid Quantitative Test COA - F2311630AADDocument1 pageT3 Rapid Quantitative Test COA - F2311630AADg64bt8rqdwNo ratings yet
- ReDocument3 pagesReSyahid FarhanNo ratings yet
- Competency Training Capability IECEx 20160609Document4 pagesCompetency Training Capability IECEx 20160609AhmadNo ratings yet
- Beer Benefits From Aerator TreatmentDocument2 pagesBeer Benefits From Aerator TreatmentSam MurrayNo ratings yet
- Keystone Account Opening FormDocument6 pagesKeystone Account Opening Formenumah francisNo ratings yet
- Volatility Index 75 Macfibonacci Trading PDFDocument3 pagesVolatility Index 75 Macfibonacci Trading PDFSidibe MoctarNo ratings yet
- MEP Works OverviewDocument14 pagesMEP Works OverviewManoj KumarNo ratings yet
- Project On SpicesDocument96 pagesProject On Spicesamitmanisha50% (6)
- Some People Say That Having Jobs Can Be of Great Benefit To TeensDocument2 pagesSome People Say That Having Jobs Can Be of Great Benefit To Teensmaia sulavaNo ratings yet
- Bafb1023 Microeconomics (Open Book Test)Document4 pagesBafb1023 Microeconomics (Open Book Test)Hareen JuniorNo ratings yet
- Laser Pointing StabilityDocument5 pagesLaser Pointing Stabilitymehdi810No ratings yet
- BOM For Solar Water PumpDocument11 pagesBOM For Solar Water PumpNirat PatelNo ratings yet
- LogisticsDocument5 pagesLogisticsHương LýNo ratings yet
- Ips M PM 330Document25 pagesIps M PM 330Deborah MalanumNo ratings yet
- Dissertation Bowden PDFDocument98 pagesDissertation Bowden PDFmostafaNo ratings yet
- Case Laws IBBIDocument21 pagesCase Laws IBBIAbhinjoy PalNo ratings yet
- List of Circulating Currencies by CountryDocument8 pagesList of Circulating Currencies by CountryVivek SinghNo ratings yet
- Yrc1000 Options InstructionsDocument36 pagesYrc1000 Options Instructionshanh nguyenNo ratings yet
- 7diesel 2016Document118 pages7diesel 2016JoãoCarlosDaSilvaBrancoNo ratings yet
- LECTURE 11-Microalgal Biotechnology-Biofuels N BioproductsDocument16 pagesLECTURE 11-Microalgal Biotechnology-Biofuels N BioproductsIntan Lestari DewiNo ratings yet