You might also like
- 2006-2007 Polaris Sportsman 450 500 EFI ATV'sDocument394 pages2006-2007 Polaris Sportsman 450 500 EFI ATV'sSkip Nimmo100% (1)
- G006 - H135-155XL (G006)Document456 pagesG006 - H135-155XL (G006)Bruno Leocadio100% (5)
- 32 TMSS 01Document35 pages32 TMSS 01Mohammed Madi67% (3)
- Epid PDFDocument14 pagesEpid PDFARISA DWI SAKTINo ratings yet
- Catalog Materiale Electrice Fluke PDFDocument140 pagesCatalog Materiale Electrice Fluke PDFFlorinNo ratings yet
- Lecture 10: Power-Flow Studies: Instructor: Dr. Gleb V. Tcheslavski Contact: Office HoursDocument28 pagesLecture 10: Power-Flow Studies: Instructor: Dr. Gleb V. Tcheslavski Contact: Office HoursAn00pgadzillaNo ratings yet
- 191 Version 4 TC14 Technical ManualDocument42 pages191 Version 4 TC14 Technical ManualBrahim Chergui100% (2)
- Deep Learning With Spiking NeuronsDocument18 pagesDeep Learning With Spiking NeuronsMohaddeseh MozaffariNo ratings yet
- Spikems: Deep Spiking Neural Network For Motion SegmentationDocument7 pagesSpikems: Deep Spiking Neural Network For Motion SegmentationSergio Marcelino Trejo FuentesNo ratings yet
- Neuromorphic Computing - From Robust Hardware Architectures To Testing StrategiesDocument4 pagesNeuromorphic Computing - From Robust Hardware Architectures To Testing StrategieslidhisijuNo ratings yet
- Stereospike: Depth Learning With A Spiking Neural NetworkDocument12 pagesStereospike: Depth Learning With A Spiking Neural NetworkSergio Marcelino Trejo FuentesNo ratings yet
- Neuromorphic Computing With Memristor CrossbarDocument16 pagesNeuromorphic Computing With Memristor Crossbarkamrul.malsxxc44No ratings yet
- SeminorDocument9 pagesSeminorNiharikaNo ratings yet
- Learning in Memristive Neural Network Architectures Using Analog Backpropagation CircuitsDocument14 pagesLearning in Memristive Neural Network Architectures Using Analog Backpropagation CircuitsHussain Bin AliNo ratings yet
- TrueNorth Design and Tool Flow of A 65 MW 1 Million Neuron Programmable Neurosynaptic ChipDocument21 pagesTrueNorth Design and Tool Flow of A 65 MW 1 Million Neuron Programmable Neurosynaptic Chip何军民No ratings yet
- Design and Implementation of A Convolutional NeuraDocument11 pagesDesign and Implementation of A Convolutional NeuraFASAKIN OLUWASEYINo ratings yet
- Modular T-Mode Design Approach for Analog Neural Network HardwareDocument14 pagesModular T-Mode Design Approach for Analog Neural Network HardwareandresNo ratings yet
- Spiking neural networks for efficient vision tasksDocument23 pagesSpiking neural networks for efficient vision tasksHasanayn Al-MeemarNo ratings yet
- Neural Networks and Their Applications: Machine LearningDocument8 pagesNeural Networks and Their Applications: Machine LearningRudrasish MishraNo ratings yet
- Fault TolerantDocument17 pagesFault TolerantlokeshNo ratings yet
- A Comprehensive Survey On Graph Neural NetworksDocument22 pagesA Comprehensive Survey On Graph Neural NetworksMihai IlieNo ratings yet
- A Digital Liquid State Machine With Biologically Inspired Learning and Its Application To Speech RecognitionDocument15 pagesA Digital Liquid State Machine With Biologically Inspired Learning and Its Application To Speech RecognitionVangala PorusNo ratings yet
- Neural Network Approaches To Image Compression: Robert D. Dony, Student, IEEE Simon Haykin, Fellow, IEEEDocument16 pagesNeural Network Approaches To Image Compression: Robert D. Dony, Student, IEEE Simon Haykin, Fellow, IEEEdanakibreNo ratings yet
- From MamDocument10 pagesFrom MamShimanto BhoumikNo ratings yet
- NEUROMORPHIC COMPUTING FUTUREDocument10 pagesNEUROMORPHIC COMPUTING FUTUREMayuri AnandikarNo ratings yet
- Deep Neural Network Using VLSI Stochastic ComputationDocument8 pagesDeep Neural Network Using VLSI Stochastic ComputationKhang Truong NguyenNo ratings yet
- Network Routing by Artificial Neural Network: January 2012Document6 pagesNetwork Routing by Artificial Neural Network: January 2012fermanNo ratings yet
- Breathing-Based Authentication On Resource-Constrained Iot Devices Using Recurrent Neural NetworksDocument8 pagesBreathing-Based Authentication On Resource-Constrained Iot Devices Using Recurrent Neural NetworksMuhamad IkhsanNo ratings yet
- An Efficient SpiNNaker Implementation of The Neural Engineering FrameworkDocument8 pagesAn Efficient SpiNNaker Implementation of The Neural Engineering FrameworkJohn SmithNo ratings yet
- Neuromorphic Computing: The Potential For High-Performance Processing in SpaceDocument12 pagesNeuromorphic Computing: The Potential For High-Performance Processing in SpacemaheshNo ratings yet
- A Software Defined Radio For Wireless Br-1Document3 pagesA Software Defined Radio For Wireless Br-1Generation GenerationNo ratings yet
- The SpiNNaker ProjectDocument14 pagesThe SpiNNaker ProjectVeronica MisiedjanNo ratings yet
- Multistate Magnetic Domain Wall Devices For Neuromorphic ComputingDocument9 pagesMultistate Magnetic Domain Wall Devices For Neuromorphic ComputingГлеб ДёминNo ratings yet
- Deep Learning Inference On Mobile Devices: Deepx: A Software Accelerator For Low-PowerDocument12 pagesDeep Learning Inference On Mobile Devices: Deepx: A Software Accelerator For Low-PowerMewada HirenNo ratings yet
- A Dynamically Configurable Coprocessor For Convolutional Neural NetworksDocument11 pagesA Dynamically Configurable Coprocessor For Convolutional Neural NetworksSarthak GoyalNo ratings yet
- DB 86 FbeeDocument14 pagesDB 86 FbeeFanevaNo ratings yet
- A Survey of Deep Neural Network Architectures and Their Applications PDFDocument16 pagesA Survey of Deep Neural Network Architectures and Their Applications PDFFuwei TIANNo ratings yet
- CNN Algorithms Survey on Edge Computing with Reconfigurable HardwareDocument24 pagesCNN Algorithms Survey on Edge Computing with Reconfigurable Hardwarearania313No ratings yet
- Neuromorphic Computing: Features and ApplicationsDocument10 pagesNeuromorphic Computing: Features and ApplicationsMayuri AnandikarNo ratings yet
- IEEE SIGNAL PROCESSING MAGAZINE SURVEY OF MODEL COMPRESSION AND ACCELERATION FOR DEEP NEURAL NETWORKSDocument10 pagesIEEE SIGNAL PROCESSING MAGAZINE SURVEY OF MODEL COMPRESSION AND ACCELERATION FOR DEEP NEURAL NETWORKSirfanwahla786No ratings yet
- Hardware for Deep Learning AccelerationDocument20 pagesHardware for Deep Learning AccelerationBill PetrieNo ratings yet
- Top 1Document41 pagesTop 1baboucarNo ratings yet
- 1-s2.0-S0020025524001890-mainDocument20 pages1-s2.0-S0020025524001890-mainAbdullah AbdullahNo ratings yet
- Recognition of Handwritten Digit Using Convolutional Neural Network in Python With Tensorflow and Comparison of Performance For Various Hidden LayersDocument6 pagesRecognition of Handwritten Digit Using Convolutional Neural Network in Python With Tensorflow and Comparison of Performance For Various Hidden Layersjaime yelsin rosales malpartidaNo ratings yet
- 1 s2.0 S2213138822001102 MainDocument8 pages1 s2.0 S2213138822001102 MainGuru VelmathiNo ratings yet
- Algorithms 17 00104Document28 pagesAlgorithms 17 00104jamel-shamsNo ratings yet
- CSINN Batina PaperDocument19 pagesCSINN Batina PaperShubhashish MoitraNo ratings yet
- AI Tech Agency Infographics by SlidesgoDocument23 pagesAI Tech Agency Infographics by Slidesgoinaharya27No ratings yet
- Evaluating DNN and Classical ML Algorithms For NidsDocument24 pagesEvaluating DNN and Classical ML Algorithms For NidsrishiNo ratings yet
- Untitled Document (1)Document23 pagesUntitled Document (1)Muzammil AsrarNo ratings yet
- Vlsi For Neural Networks and Their ApplicationsDocument12 pagesVlsi For Neural Networks and Their ApplicationsvinaysuperlionNo ratings yet
- Rapid Dna Origami Nanostructure Detection and Classification Using The Yolov5 Deep Convolutional Neural NetworkDocument13 pagesRapid Dna Origami Nanostructure Detection and Classification Using The Yolov5 Deep Convolutional Neural NetworkEd swertNo ratings yet
- Emergence of Neuromorphic Chips To Simulate Human Brain: K. Anirudh BharadwajDocument4 pagesEmergence of Neuromorphic Chips To Simulate Human Brain: K. Anirudh BharadwajlidhisijuNo ratings yet
- Neural Networks in Data Mining and Knowledge DiscoveryDocument15 pagesNeural Networks in Data Mining and Knowledge DiscoveryElena Galeote LopezNo ratings yet
- Digital Morris-Lecar Neuron Implementation With Variable ParametersDocument5 pagesDigital Morris-Lecar Neuron Implementation With Variable ParametersReza BarkhordariNo ratings yet
- An Area - and Energy-Efficient Spiking Neural Network With Spike-Time-Dependent Plasticity Realized With SRAM Processing-in-Memory Macro and On-Chip Unsupervised LearningDocument13 pagesAn Area - and Energy-Efficient Spiking Neural Network With Spike-Time-Dependent Plasticity Realized With SRAM Processing-in-Memory Macro and On-Chip Unsupervised LearningPANTHADIP MAJINo ratings yet
- An All-Memristor Deep Spiking Neural Computing System A Step Toward Realizing The Low-Power Stochastic BrainDocument14 pagesAn All-Memristor Deep Spiking Neural Computing System A Step Toward Realizing The Low-Power Stochastic BrainbismuthsunilNo ratings yet
- OSPEN: An Open Source Platform For Emulating Neuromorphic HardwareDocument8 pagesOSPEN: An Open Source Platform For Emulating Neuromorphic HardwareIJRES teamNo ratings yet
- Neuromorphic Computing Review of Hardware-Based Hopfield Neural NetworkDocument15 pagesNeuromorphic Computing Review of Hardware-Based Hopfield Neural NetworkBerry BooNo ratings yet
- Research On A New Effective Data Mining Based On Neural NetworksDocument14 pagesResearch On A New Effective Data Mining Based On Neural NetworksVandana MalkaniNo ratings yet
- Deep Cellular Recurrent Network For Efficient Analysis of Time-Series Data With Spatial InformationDocument10 pagesDeep Cellular Recurrent Network For Efficient Analysis of Time-Series Data With Spatial Informationbaltazzar_90No ratings yet
- Low-Loss Photonic Reservoir Computing With Multimode Photonic Integrated CircuitsDocument10 pagesLow-Loss Photonic Reservoir Computing With Multimode Photonic Integrated CircuitsprajneshNo ratings yet
- An Analog Neural Network Processor Programmable Topology: Boser, Jane DDocument9 pagesAn Analog Neural Network Processor Programmable Topology: Boser, Jane DApoorva MahajanNo ratings yet
- VLSIDocument25 pagesVLSIgangavinodc123No ratings yet
- Design and Analysis of A Neuromemristive ReservoirDocument17 pagesDesign and Analysis of A Neuromemristive ReservoirMichael SprinzlNo ratings yet
- Neuromorphic Computing-From Devices To IntegratedcircuitsDocument21 pagesNeuromorphic Computing-From Devices To Integratedcircuits322203359001No ratings yet
- Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset CategorizationFrom EverandConvolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset CategorizationNo ratings yet
- 1 24 March 2015Document15 pages1 24 March 2015Shimanto BhoumikNo ratings yet
- Opto-Electronic Detectors: ContentsDocument15 pagesOpto-Electronic Detectors: ContentsShimanto BhoumikNo ratings yet
- 1 24 March 2015Document19 pages1 24 March 2015Shimanto BhoumikNo ratings yet
- Measurement and InstrumentationDocument12 pagesMeasurement and InstrumentationShimanto BhoumikNo ratings yet
- 1 11 April 2015Document14 pages1 11 April 2015Shimanto BhoumikNo ratings yet
- Deep Convolutional Neural Networks For Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer LearningDocument14 pagesDeep Convolutional Neural Networks For Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer LearningShimanto BhoumikNo ratings yet
- 1 18 March 2015Document13 pages1 18 March 2015Shimanto BhoumikNo ratings yet
- Spintronic Optimization of Memory ArraysDocument9 pagesSpintronic Optimization of Memory ArraysShimanto BhoumikNo ratings yet
- Spindle: Spintronic Deep Learning Engine For Large-Scale Neuromorphic ComputingDocument6 pagesSpindle: Spintronic Deep Learning Engine For Large-Scale Neuromorphic ComputingShimanto BhoumikNo ratings yet
- SNN Vs CNN On Supervised LearningDocument5 pagesSNN Vs CNN On Supervised LearningShimanto BhoumikNo ratings yet
- From MamDocument10 pagesFrom MamShimanto BhoumikNo ratings yet
- From MamDocument10 pagesFrom MamShimanto BhoumikNo ratings yet
- SNN Vs CNN On Supervised LearningDocument5 pagesSNN Vs CNN On Supervised LearningShimanto BhoumikNo ratings yet
- Codan Tactical - Antenna ComparisionDocument6 pagesCodan Tactical - Antenna ComparisionBernardo Marín BustosNo ratings yet
- Datasheet RGPS-7084GP-P v1.0Document4 pagesDatasheet RGPS-7084GP-P v1.0oring2012No ratings yet
- 60 GHZ Beamforming Transmitter Design For Pulse Doppler RadarDocument135 pages60 GHZ Beamforming Transmitter Design For Pulse Doppler Radarcowboy1980No ratings yet
- Experiment Name: Zener Diode Characteristics .: Circuit 1Document6 pagesExperiment Name: Zener Diode Characteristics .: Circuit 1salameen shadaNo ratings yet
- Bias CircuitsDocument5 pagesBias CircuitsChoton Chowdhury0% (1)
- Datex Ohmeda Cardiocap - 5 - Service Manual (2007)Document144 pagesDatex Ohmeda Cardiocap - 5 - Service Manual (2007)Ricardo MedellinNo ratings yet
- Projeto Caixa Acustica X-PRO-15Document2 pagesProjeto Caixa Acustica X-PRO-15Denílson SouzaNo ratings yet
- LEC1 - Elementary Semiconductors TheoryDocument56 pagesLEC1 - Elementary Semiconductors Theoryroi constantineNo ratings yet
- Department of Electronics and Communication Engineering Saintgits College of EngineeringDocument41 pagesDepartment of Electronics and Communication Engineering Saintgits College of EngineeringGeorgeyfkNo ratings yet
- 010 OktoberDocument36 pages010 OktoberTri ananda putraNo ratings yet
- 8 Electromagnetic Methods of Lightning LocationDocument17 pages8 Electromagnetic Methods of Lightning LocationMellina LisboaNo ratings yet
- Polycrystalline Solar Module: An Everexceed High-Power Residential Solar Module Isan Aesthetic To Most Roofs AdditionDocument2 pagesPolycrystalline Solar Module: An Everexceed High-Power Residential Solar Module Isan Aesthetic To Most Roofs AdditionAmrina RosyadaNo ratings yet
- Interference and Capacity in Cellular SystemsDocument19 pagesInterference and Capacity in Cellular SystemsAyo OlaNo ratings yet
- DCX1000 and DCX3000 Digital KVM Switching System: Product Data SheetDocument8 pagesDCX1000 and DCX3000 Digital KVM Switching System: Product Data SheetpacapioNo ratings yet
- Subatomic Particles of AtomsDocument8 pagesSubatomic Particles of AtomsRose Ann Marie BabiaNo ratings yet
- Zeiss Opmi Pico s100 Repair and Alignment InstructionsDocument13 pagesZeiss Opmi Pico s100 Repair and Alignment InstructionsAngeloNo ratings yet
- Procedimento Teste 9500 MPR - Rev1 ClaroDocument25 pagesProcedimento Teste 9500 MPR - Rev1 ClaroAndré BorgesNo ratings yet
- Panasonic Mpf6907 Pcpf0272 SCHDocument4 pagesPanasonic Mpf6907 Pcpf0272 SCHFrancisco Carbonell50% (2)
- Motor Torque and Power: J. Michael MccarthyDocument7 pagesMotor Torque and Power: J. Michael MccarthySidney LinsNo ratings yet
- Online Booking System For Car ParkingDocument4 pagesOnline Booking System For Car Parkingkalanakal9669No ratings yet
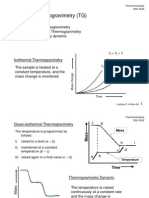
- Thermogravimetry (TG) : 1. Isothermal Thermogravimetry 2. Quasi-Isothermal Thermogravimetry 3. Thermogravimetry DynamicDocument19 pagesThermogravimetry (TG) : 1. Isothermal Thermogravimetry 2. Quasi-Isothermal Thermogravimetry 3. Thermogravimetry DynamicZUL KAMARUDDIN100% (1)
- An Experimental Prototype of Buck Converter Fed Series DC Motor Implementing Speed and Current ControlsDocument4 pagesAn Experimental Prototype of Buck Converter Fed Series DC Motor Implementing Speed and Current ControlsdevchandarNo ratings yet
- Linux Architecture: by Jyoti Verma Roll No: 6310035 Branch: CSE (7A)Document10 pagesLinux Architecture: by Jyoti Verma Roll No: 6310035 Branch: CSE (7A)HimanshuRanaNo ratings yet