You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Bolt Design For Steel Connections As Per AISCDocument24 pagesBolt Design For Steel Connections As Per AISCJayachandra PelluruNo ratings yet
- 058222016ID Fan Hydraulic Coupling-1210SVNL BESCL-BHILAI PDFDocument185 pages058222016ID Fan Hydraulic Coupling-1210SVNL BESCL-BHILAI PDFCoalman InchpNo ratings yet
- 3-038R-R303 Multi Analyzer 2019 PDFDocument1 page3-038R-R303 Multi Analyzer 2019 PDFSirish ShresthaNo ratings yet
- Chapter - 7 Part II STDDocument43 pagesChapter - 7 Part II STDBelkacem AchourNo ratings yet
- MachineLearningNotes PDFDocument299 pagesMachineLearningNotes PDFKarthik selvamNo ratings yet
- CVEN 659 Syllabus Spring 2014Document2 pagesCVEN 659 Syllabus Spring 2014Akesh Varma KothapalliNo ratings yet
- CSS - 05-Module 5.2 - Network Devices1Document6 pagesCSS - 05-Module 5.2 - Network Devices1Elixa HernandezNo ratings yet
- Syllabus CE5307-CE4365 Spring 2018Document4 pagesSyllabus CE5307-CE4365 Spring 2018Akesh Varma KothapalliNo ratings yet
- Dimensionality ReductionDocument37 pagesDimensionality ReductionAkesh Varma KothapalliNo ratings yet
- SML Book Draft LatestDocument194 pagesSML Book Draft LatestAkesh Varma KothapalliNo ratings yet
- MIT18 05S14 Reading10b PDFDocument9 pagesMIT18 05S14 Reading10b PDFIslamSharafNo ratings yet
- 16-9 Accuracy of Erected SteelworkDocument8 pages16-9 Accuracy of Erected SteelworkZuberYousufNo ratings yet
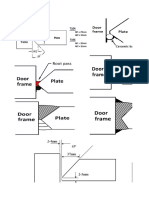
- Door SheetDocument9 pagesDoor SheetAnilkumarNo ratings yet
- SV1-10-4/4M/4R: - Solenoid ValveDocument2 pagesSV1-10-4/4M/4R: - Solenoid ValveCORTOCIRCUITANTENo ratings yet
- APIU CARMT Syllabus Version 1.0 - Confidential For Review CommitteeDocument49 pagesAPIU CARMT Syllabus Version 1.0 - Confidential For Review CommitteeFuad HassanNo ratings yet
- Test Section 2 QuizDocument5 pagesTest Section 2 QuizDavidNo ratings yet
- Analysis of Cost Control, Time, and Quality On Construction ProjectDocument12 pagesAnalysis of Cost Control, Time, and Quality On Construction ProjectDeryta FlorentinusNo ratings yet
- Tutorial 6Document5 pagesTutorial 6Nixon GamingNo ratings yet
- Trick Flow Head StatsDocument15 pagesTrick Flow Head StatsdancaleyNo ratings yet
- PetDocument15 pagesPetAhmed RhifNo ratings yet
- SMM200 Derivatives and Risk Management 2021 QuestionsDocument5 pagesSMM200 Derivatives and Risk Management 2021 Questionsminh daoNo ratings yet
- Ca 3241Document1 pageCa 3241Tien LamNo ratings yet
- Inspection and Testing of OC/EF Protection Relay: Relay Site Test ReportDocument3 pagesInspection and Testing of OC/EF Protection Relay: Relay Site Test ReportMASUD RANANo ratings yet
- Química de CoordinacionDocument107 pagesQuímica de CoordinacionEMMANUEL ALEJANDRO FERNANDEZ GAVIRIANo ratings yet
- Miller Proheat 35 CE ManualDocument1 pageMiller Proheat 35 CE ManualcarlosNo ratings yet
- Aashto - T240-13 RtfotDocument11 pagesAashto - T240-13 RtfotKUNCHE SAI ARAVIND SVNITNo ratings yet
- jPOS EEDocument67 pagesjPOS EEanand tmNo ratings yet
- Fkeyrouz@ndu - Edu.lb: Systems Using MATLAB, Second Edition, Prentice Hall 2002Document2 pagesFkeyrouz@ndu - Edu.lb: Systems Using MATLAB, Second Edition, Prentice Hall 2002Elio EidNo ratings yet
- Vibrator Head H25HA: Material Number 5000610058Document2 pagesVibrator Head H25HA: Material Number 5000610058Luis ZavalaNo ratings yet
- Lecture 5. Chemical Reaction (Part 2)Document38 pagesLecture 5. Chemical Reaction (Part 2)Dione Gale NavalNo ratings yet
- Low Shock Stage Separation System For Long Range Missile ApplicationDocument3 pagesLow Shock Stage Separation System For Long Range Missile ApplicationalexNo ratings yet
- HX 16-Data SheetDocument2 pagesHX 16-Data SheetRaul SebastiamNo ratings yet
- Smart Pixel ArrayDocument23 pagesSmart Pixel Arraydevauthor123No ratings yet
- Module 1.MMWDocument20 pagesModule 1.MMWJimmy DegayNo ratings yet
- Sample LPDocument4 pagesSample LPJon Jon D. MarcosNo ratings yet
- Bionic ReportDocument11 pagesBionic ReportIgor HorvatNo ratings yet
- RPI Form PDFDocument1 pageRPI Form PDFJoko WiwiNo ratings yet