You might also like
- Composers and Musicians: Reproducible Worksheets for the Music ClassroomFrom EverandComposers and Musicians: Reproducible Worksheets for the Music ClassroomRating: 5 out of 5 stars5/5 (4)
- Practical Gas Lift ManualDocument26 pagesPractical Gas Lift ManualbvalinhasNo ratings yet
- World Quality Report 2019 2020Document68 pagesWorld Quality Report 2019 2020Remco100% (1)
- Supermarine Spitfire MK VIII - BetaDocument4 pagesSupermarine Spitfire MK VIII - Betamrpalaces100% (1)
- Screw Compressor ASY (R-134) Series PDFDocument52 pagesScrew Compressor ASY (R-134) Series PDFNajam2450% (2)
- TOCF (EE) R16.0.0.3 Release NotesDocument7 pagesTOCF (EE) R16.0.0.3 Release NotesNett2k100% (1)
- Bootstrap Components PDFDocument38 pagesBootstrap Components PDFGeyser RamirezNo ratings yet
- NH FLRegkey RegDocument2 pagesNH FLRegkey RegNahuel Perez100% (1)
- Vga Ping Pong GameDocument53 pagesVga Ping Pong Gamegaurav311086100% (2)
- Travel Package Recommendation SystemDocument55 pagesTravel Package Recommendation SystemVisarikaNo ratings yet
- Motor and Gear G500 S3100 5,5kW, 7,5kW - Parts List - 2020Document1 pageMotor and Gear G500 S3100 5,5kW, 7,5kW - Parts List - 2020Centrifugal SeparatorNo ratings yet
- 2022.11.21 - PENTAX-50Hz-GC-rev-34 - CMDocument12 pages2022.11.21 - PENTAX-50Hz-GC-rev-34 - CMBogdan NistorNo ratings yet
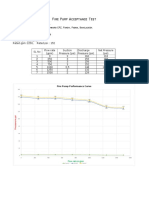
- Fire Pump Acceptance Test: Name: Vintage Denim Studio LTDDocument1 pageFire Pump Acceptance Test: Name: Vintage Denim Studio LTDMd Nazrul Islam AzadNo ratings yet
- Dynamic Programming Solution To Numerical ProblemsDocument13 pagesDynamic Programming Solution To Numerical ProblemsSarayu GowdaNo ratings yet
- Tegangan Penambahan Ifg Dengan Kecepatan 1400 Dan 1200 RPM Tegangan Penurunan Ifg Dengan KecepatanDocument7 pagesTegangan Penambahan Ifg Dengan Kecepatan 1400 Dan 1200 RPM Tegangan Penurunan Ifg Dengan KecepatanRama M. FauziNo ratings yet
- Tegangan Penambahan Ifg Dengan Kecepatan 1400 Dan 1200 RPMDocument9 pagesTegangan Penambahan Ifg Dengan Kecepatan 1400 Dan 1200 RPMRama M. FauziNo ratings yet
- Dan 1200 RPM: Tegangan Penambahan Ifg Dengan Kecepatan 1400Document11 pagesDan 1200 RPM: Tegangan Penambahan Ifg Dengan Kecepatan 1400Rama M. FauziNo ratings yet
- JM Katalog Standard Glidlager 8191 Folder - enGB - v2Document4 pagesJM Katalog Standard Glidlager 8191 Folder - enGB - v2Nisam OdavdeNo ratings yet
- 4 Speed - FWD TH440-T4 (ME9), 4T60Document12 pages4 Speed - FWD TH440-T4 (ME9), 4T60AndreyNo ratings yet
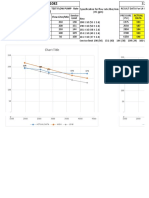
- Revised Pump Chart March 2014Document2 pagesRevised Pump Chart March 2014PillaChantasNo ratings yet
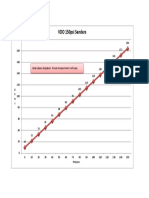
- VDO 150PSI Sender CurveDocument1 pageVDO 150PSI Sender CurveCarlosNo ratings yet
- Pinga 1Document12 pagesPinga 1Reasat AzimNo ratings yet
- Type Delta Type Globus: Lined Ball Check ValveDocument2 pagesType Delta Type Globus: Lined Ball Check ValveandrebitaNo ratings yet
- Al/Alx: SeriesDocument76 pagesAl/Alx: SeriesQuynh Bui DucNo ratings yet
- FBT J8 Data SheetDocument3 pagesFBT J8 Data SheetDavid LeongNo ratings yet
- PPK - Pinch - Hana IkbarDocument17 pagesPPK - Pinch - Hana IkbarHuwaida IkbarNo ratings yet
- Final Report of AntennaDocument4 pagesFinal Report of AntennaAmir Al-ashtalNo ratings yet
- Thermometer Evolution SpreadsheetDocument8 pagesThermometer Evolution Spreadsheetapi-359353491No ratings yet
- Fixed PickingDocument1 pageFixed Pickinggopi_ggg20016099No ratings yet
- F03 - InxDocument1 pageF03 - Inxricardo.perinoNo ratings yet
- BXV 80090 8CF R1Document1 pageBXV 80090 8CF R1Francisco NascimentoNo ratings yet
- Estanislao Quiz Number 35Document6 pagesEstanislao Quiz Number 35thomasestanislaoNo ratings yet
- Special: Edition: 02/05.2015 Replaces: SPV 01 T ADocument16 pagesSpecial: Edition: 02/05.2015 Replaces: SPV 01 T AJustinNo ratings yet
- AmritlipiDocument1 pageAmritlipiAmandeep SinghNo ratings yet
- LGH RX5 E - SpecDocument2 pagesLGH RX5 E - SpecpradungNo ratings yet
- GurbaniAkhar Keyboard MapDocument1 pageGurbaniAkhar Keyboard MapRight ClipsNo ratings yet
- 9600 Parts ListDocument21 pages9600 Parts ListlftrevNo ratings yet
- Harits Eka Febriyanto - 50082011114Document17 pagesHarits Eka Febriyanto - 50082011114Harits Eka FebriyantoNo ratings yet
- Gorro de Bruja 1Document2 pagesGorro de Bruja 1Jorge Navas VargasNo ratings yet
- BRISTOL - Fire Pumps - End Suction PDFDocument11 pagesBRISTOL - Fire Pumps - End Suction PDFMohamed AdelNo ratings yet
- Top Slab Bottom Slab Out Side Wall Hench Thick Ness Top Corner Bottom CornerDocument3 pagesTop Slab Bottom Slab Out Side Wall Hench Thick Ness Top Corner Bottom CornerDipanjan MitraNo ratings yet
- Top Slab Bottom Slab Out Side Wall Hench Thick Ness Top Corner Bottom CornerDocument3 pagesTop Slab Bottom Slab Out Side Wall Hench Thick Ness Top Corner Bottom CornerDipanjan MitraNo ratings yet
- Top Slab Bottom Slab Out Side Wall Hench Thick Ness Top Corner Bottom CornerDocument3 pagesTop Slab Bottom Slab Out Side Wall Hench Thick Ness Top Corner Bottom CornerDipanjan MitraNo ratings yet
- Top Slab Bottom Slab Out Side Wall Hench Thick Ness Top Corner Bottom CornerDocument3 pagesTop Slab Bottom Slab Out Side Wall Hench Thick Ness Top Corner Bottom CornerDipanjan MitraNo ratings yet
- Ce 362 Plate 9Document1 pageCe 362 Plate 9lonyx27No ratings yet
- Noris: StrainerDocument1 pageNoris: StrainerDanielNo ratings yet
- Filvalco PRVDocument1 pageFilvalco PRVForhad AhmedNo ratings yet
- FRP Flange / DIN Standard DimensionsDocument2 pagesFRP Flange / DIN Standard DimensionsJuancho CurryNo ratings yet
- Mechanical Specifications: Vertically Polarized, Panel 62° / 17 DBDDocument1 pageMechanical Specifications: Vertically Polarized, Panel 62° / 17 DBDLuis Diaz ArroyoNo ratings yet
- Signia Lotus Hearing Aids Fast P BteDocument8 pagesSignia Lotus Hearing Aids Fast P BteSoumya MaheshNo ratings yet
- Dr. Zaenal Mutaqien (Promotive and Sport Medicine)Document27 pagesDr. Zaenal Mutaqien (Promotive and Sport Medicine)Red DemonNo ratings yet
- Magmeter Sroat 1000Document2 pagesMagmeter Sroat 1000narendra mistriNo ratings yet
- Notes: Gusset & Shim Plates Dimensions:A B (Horizontal Vertical)Document6 pagesNotes: Gusset & Shim Plates Dimensions:A B (Horizontal Vertical)Hima AhmedNo ratings yet
- Book 1Document25 pagesBook 1sipil1921134.adimashariyantoNo ratings yet
- TLX Led 50.30.1726 TLX Led Panels RoundDocument5 pagesTLX Led 50.30.1726 TLX Led Panels Roundeto firebirdNo ratings yet
- As Build Drawing: Cme RT Pole 6 M Site Name: Pondok Tjandra Site Id: Sda003Document36 pagesAs Build Drawing: Cme RT Pole 6 M Site Name: Pondok Tjandra Site Id: Sda003herry horasNo ratings yet
- Order No: Column K Column O Column I Linear (Column I)Document8 pagesOrder No: Column K Column O Column I Linear (Column I)api-3700568No ratings yet
- Bxa 80090 8CFDocument1 pageBxa 80090 8CFFrancisco NascimentoNo ratings yet
- GRP10-50 BrochureDocument2 pagesGRP10-50 BrochureETIENNENo ratings yet
- Endo Gia Curved Tip Reload With Tri StapleDocument4 pagesEndo Gia Curved Tip Reload With Tri StapleAntiGeekNo ratings yet
- University of Tripoli Faculty of Engineering Petroleum Engineering DepartmentDocument6 pagesUniversity of Tripoli Faculty of Engineering Petroleum Engineering DepartmentMokbel MosbahNo ratings yet
- Electronegativity Periodic TableDocument3 pagesElectronegativity Periodic TableShan YahyaNo ratings yet
- Technical Bulletin:: LG ESP Controller - LB Models OnlyDocument6 pagesTechnical Bulletin:: LG ESP Controller - LB Models OnlyПедро СлеваNo ratings yet
- Building LayoutDocument1 pageBuilding LayoutFaisal TehseenNo ratings yet
- Table 20210906214931Document4 pagesTable 20210906214931Luiizz MartiinezzNo ratings yet
- Test Flow Data 324D SN DFP01082 06 April 2020Document11 pagesTest Flow Data 324D SN DFP01082 06 April 2020Robel KebedeNo ratings yet
- Latihan Weldment 2Document1 pageLatihan Weldment 207Andhika IqbalNo ratings yet
- 1621440158TI Sanitas International Students enDocument1 page1621440158TI Sanitas International Students enAndy OrtizNo ratings yet
- Linear Algebra I: Skills, Concepts and ApplicationsDocument59 pagesLinear Algebra I: Skills, Concepts and ApplicationsAndy OrtizNo ratings yet
- Florida Department of Corrections: Criminal Investigation Investigative AssistDocument8 pagesFlorida Department of Corrections: Criminal Investigation Investigative AssistAndy OrtizNo ratings yet
- 404 8 QueryProcessingDocument136 pages404 8 QueryProcessingAndy OrtizNo ratings yet
- Insurance Application Form: To Be Completed by SanitasDocument6 pagesInsurance Application Form: To Be Completed by SanitasAndy OrtizNo ratings yet
- 223 Gram SchmidtDocument3 pages223 Gram SchmidtAndy OrtizNo ratings yet
- Micha El Bensimhoun,: AbstractDocument4 pagesMicha El Bensimhoun,: AbstractAndy OrtizNo ratings yet
- SF2729 Groups and Rings Final Exam Solutions: Solution ( )Document3 pagesSF2729 Groups and Rings Final Exam Solutions: Solution ( )Andy OrtizNo ratings yet
- BuforDocument8 pagesBuforAndy OrtizNo ratings yet
- GPU Architecture and Parallel Programming: Tiled Convolution AnalysisDocument18 pagesGPU Architecture and Parallel Programming: Tiled Convolution AnalysisAndy OrtizNo ratings yet
- For (I 0 I Outputsize I++) (Y (I) 0 For (J 0 J Kernelsize J++) (Y (I) + X (I - J) H (J) ) )Document7 pagesFor (I 0 I Outputsize I++) (Y (I) 0 For (J 0 J Kernelsize J++) (Y (I) + X (I - J) H (J) ) )Andy OrtizNo ratings yet
- 1PropZInterval StatI NspireDocument2 pages1PropZInterval StatI NspireAndy OrtizNo ratings yet
- Course: Physics I Degree: Aerospace Engineering YEAR: 1st TERM: 1st Weekly Programming Description Weekly Programming For Student DescriptionDocument3 pagesCourse: Physics I Degree: Aerospace Engineering YEAR: 1st TERM: 1st Weekly Programming Description Weekly Programming For Student DescriptionAndy OrtizNo ratings yet
- 10th Grade Elective Sheet 2021-22Document2 pages10th Grade Elective Sheet 2021-22Andy OrtizNo ratings yet
- Supreme Court of The United States: Groh V. RamirezDocument33 pagesSupreme Court of The United States: Groh V. RamirezAndy OrtizNo ratings yet
- 10 Cuda Dgemm TiledDocument33 pages10 Cuda Dgemm TiledAndy OrtizNo ratings yet
- AY2021 Entrance Examination Guide Department of Electrical Engineering and Information Systems (EEIS)Document9 pagesAY2021 Entrance Examination Guide Department of Electrical Engineering and Information Systems (EEIS)Andy OrtizNo ratings yet
- Constraints and Updates: CHAPTER 3 (6/E) CHAPTER 5 (5/E)Document22 pagesConstraints and Updates: CHAPTER 3 (6/E) CHAPTER 5 (5/E)Andy OrtizNo ratings yet
- COP 4600 Spring 2016 Project 2 - Semaphores: Implement Semaphores in Minix3Document2 pagesCOP 4600 Spring 2016 Project 2 - Semaphores: Implement Semaphores in Minix3Andy OrtizNo ratings yet
- Room Rental Agreement With Special Conditions of Use, Supplementary To The Rental AgreementDocument7 pagesRoom Rental Agreement With Special Conditions of Use, Supplementary To The Rental AgreementAndy OrtizNo ratings yet
- First Practical Work-3Document2 pagesFirst Practical Work-3Andy OrtizNo ratings yet
- 1.5 Elementary Matrices and A Method For Finding The InverseDocument10 pages1.5 Elementary Matrices and A Method For Finding The InverseAndy OrtizNo ratings yet
- Lesson 406 Level 4 Pay Attention 1Document11 pagesLesson 406 Level 4 Pay Attention 1Andy OrtizNo ratings yet
- Study Habits: by The End of This Lesson, You Will Be Able ToDocument12 pagesStudy Habits: by The End of This Lesson, You Will Be Able ToAndy OrtizNo ratings yet
- 12 Gpu Cuda 3Document58 pages12 Gpu Cuda 3Andy OrtizNo ratings yet
- HPE MSA Gen6 Virtual Storage Technical Reference Guide-A00103247enwDocument32 pagesHPE MSA Gen6 Virtual Storage Technical Reference Guide-A00103247enwHernan HerreraNo ratings yet
- Wave-Current Interaction Using The Vortex Force MethodDocument31 pagesWave-Current Interaction Using The Vortex Force MethodJosephNo ratings yet
- Cisco SPA 502G 1-Line IP PhoneDocument5 pagesCisco SPA 502G 1-Line IP PhonemastrNo ratings yet
- IMDG Code E-Learning Activation InstructionsDocument2 pagesIMDG Code E-Learning Activation InstructionsAndreas IoannouNo ratings yet
- Ajay AnandDocument17 pagesAjay AnandSanjaNo ratings yet
- Infotec Ai 1000 Program-hcia-Ai Lab GuideDocument82 pagesInfotec Ai 1000 Program-hcia-Ai Lab Guidemicke juarezNo ratings yet
- CPC Program DeviceDocument3 pagesCPC Program DeviceJohn DollNo ratings yet
- CHAPTER 3 Initializing An ACI FabricDocument75 pagesCHAPTER 3 Initializing An ACI Fabricscribdmax404No ratings yet
- 4 - Networks and Cloud ComputingDocument4 pages4 - Networks and Cloud Computingcyka blyatNo ratings yet
- Bentley Watercad Brosura PDFDocument2 pagesBentley Watercad Brosura PDFNeng RohmaNo ratings yet
- Cloud Computing 2022-23 Course FileDocument69 pagesCloud Computing 2022-23 Course FileTejasvi QueenyNo ratings yet
- General Specifications CO-920-01: GS48D20Z01-00E-NDocument4 pagesGeneral Specifications CO-920-01: GS48D20Z01-00E-N赵先生No ratings yet
- Dwnload Full Managerial Economics 12th Edition Hirschey Solutions Manual PDFDocument21 pagesDwnload Full Managerial Economics 12th Edition Hirschey Solutions Manual PDFladonnamerone1214100% (8)
- Socket ProgrammingDocument15 pagesSocket Programmingshubhamg_38No ratings yet
- Solve Me First - Submissions 11002052 - Warmup - Algorithms - HackerRankDocument1 pageSolve Me First - Submissions 11002052 - Warmup - Algorithms - HackerRankPaulo Cesar Menegon CastroNo ratings yet
- Inls 623 - Database Systems Ii - File Structures, Indexing, and HashingDocument41 pagesInls 623 - Database Systems Ii - File Structures, Indexing, and HashingAkriti AgrawalNo ratings yet
- 4 MuxDocument12 pages4 MuxsunnysNo ratings yet
- ACD Unit-5Document20 pagesACD Unit-5gdsc.pragatiNo ratings yet
- Export 3d Model PDFDocument2 pagesExport 3d Model PDFLisaNo ratings yet
- Jupyter Notebook Markdown Cheat SheetDocument1 pageJupyter Notebook Markdown Cheat SheetdaveNo ratings yet
- NETVOLC (Version 1.1) : User ManualDocument11 pagesNETVOLC (Version 1.1) : User ManualJS AbadiaNo ratings yet
- Mikroc Dspic Manual v100Document782 pagesMikroc Dspic Manual v100Mauricio Huacho ChecaNo ratings yet
- Computers & Security: Masike Malatji, Annlizé Marnewick, Suné Von SolmsDocument17 pagesComputers & Security: Masike Malatji, Annlizé Marnewick, Suné Von SolmsSAMI PENo ratings yet