You might also like
- Greenhouses for Year-Round Tulip CultivationDocument11 pagesGreenhouses for Year-Round Tulip CultivationOmar Obaid100% (1)
- Experimental Design FundamentalsDocument12 pagesExperimental Design FundamentalsBoryana100% (2)
- MCQ-LD AmsDocument16 pagesMCQ-LD AmsASWIN KUMAR N SNo ratings yet
- GP Rating CET Exam InstructionsDocument6 pagesGP Rating CET Exam InstructionsPrakash KapadnisNo ratings yet
- Murashige and Skoog NotesDocument18 pagesMurashige and Skoog NotesRaymond Katabazi100% (1)
- Canopy Management in FruitsDocument4 pagesCanopy Management in FruitsjdmanishkapoorNo ratings yet
- Soda Bottle CompostingDocument3 pagesSoda Bottle CompostingKenneth Lucena100% (1)
- A Report On Brinjal Shoot and Fruit Borer and Its ManagementDocument15 pagesA Report On Brinjal Shoot and Fruit Borer and Its ManagementBabu Ram Panthi75% (4)
- Effects of Modern Agriculture PDFDocument3 pagesEffects of Modern Agriculture PDFkaleemullah100% (1)
- Measuring Plant Frequency: Rangeland & Riparian Habitat Assessment 1Document4 pagesMeasuring Plant Frequency: Rangeland & Riparian Habitat Assessment 1cozzy'mozzy..dozzy.;No ratings yet
- General Microbiology Laboratory Manual: Biology 490Document83 pagesGeneral Microbiology Laboratory Manual: Biology 490Ibnul MubarokNo ratings yet
- Herbaceous PlantsDocument151 pagesHerbaceous PlantsRey Mark Balaod IINo ratings yet
- Rose Protected CultivationDocument25 pagesRose Protected CultivationDheeran NarendiranNo ratings yet
- 7.TOMATO PPT - 0Document22 pages7.TOMATO PPT - 0Senthil MuruganNo ratings yet
- Chapter 4 PDFDocument25 pagesChapter 4 PDFGopinath RamakrishnanNo ratings yet
- Pre-Cooling and RefrigerationDocument9 pagesPre-Cooling and RefrigerationOliver TalipNo ratings yet
- 501 Modern Concepts in Crop Production SSR MCR PDFDocument146 pages501 Modern Concepts in Crop Production SSR MCR PDFSanket BhadkeNo ratings yet
- HORT 135 Interiorscaping and Floral Design SyllabusDocument5 pagesHORT 135 Interiorscaping and Floral Design SyllabusppunziNo ratings yet
- Stress Modelling For Different Stress Situations in Fruit CropsDocument5 pagesStress Modelling For Different Stress Situations in Fruit CropsMukesh Bishnoi100% (1)
- Biofertilizers Assignment PDF by LodhaDocument7 pagesBiofertilizers Assignment PDF by LodhaGovardhanNo ratings yet
- Bioinstrumentation Lab ManualDocument19 pagesBioinstrumentation Lab ManualRitayan DeyNo ratings yet
- Natural Vegetation and WildlifeDocument27 pagesNatural Vegetation and WildlifeSujitnkbpsNo ratings yet
- Agro 3612Document55 pagesAgro 3612rushikesh Kanire100% (1)
- 1-2. Centre of OriginDocument54 pages1-2. Centre of OriginJyoti IngoleNo ratings yet
- Farming System Note Final 31 Aug 018Document88 pagesFarming System Note Final 31 Aug 018Dikshya NiraulaNo ratings yet
- Advisory For Management of Apple 2023Document19 pagesAdvisory For Management of Apple 2023Juzlan JavedNo ratings yet
- DRIS Concepts and Applications On Nutritional Diagnosis in Fruit CropsDocument11 pagesDRIS Concepts and Applications On Nutritional Diagnosis in Fruit CropsRómulo Del ValleNo ratings yet
- China Aster 336Document9 pagesChina Aster 336Manish M. RamaniNo ratings yet
- Preparation of Structure Contour MapDocument6 pagesPreparation of Structure Contour MapAn Open Letter100% (1)
- The null hypothesis was that the two traits (wing shape and body color) are independently assorting in the Drosophila melanogaster experimentDocument11 pagesThe null hypothesis was that the two traits (wing shape and body color) are independently assorting in the Drosophila melanogaster experimentNarmiNo ratings yet
- Cucurbitaceae: (Assignment # 02 Semester Spring-2020) Submission Date (April 27, 2020) BY Group #04Document14 pagesCucurbitaceae: (Assignment # 02 Semester Spring-2020) Submission Date (April 27, 2020) BY Group #04Aqib ShahzadNo ratings yet
- Ammonium SulfateDocument35 pagesAmmonium SulfateEDWIN RAJANo ratings yet
- Lecture 2 - Introduction To Heat Transfer Spring 2019 PDFDocument24 pagesLecture 2 - Introduction To Heat Transfer Spring 2019 PDFKHALIL-UR-REHMANNo ratings yet
- 11-07-2013-AGRO 101 Principles of Agronomy 1Document133 pages11-07-2013-AGRO 101 Principles of Agronomy 1Kavita Mohite100% (3)
- Practical Manual 171Document85 pagesPractical Manual 171Souvik Roy Chowdhury100% (1)
- COUNTING AND MEASURING BACTERIADocument9 pagesCOUNTING AND MEASURING BACTERIAProbioticsAnywhere100% (1)
- Horti Books PDFDocument9 pagesHorti Books PDFRupa SreeNo ratings yet
- Greenhouse Effect: Green BuildingsDocument26 pagesGreenhouse Effect: Green BuildingsAmulya GullapalliNo ratings yet
- Nano-Edible Coatings: A Novel Approach To Improve Shelf Life in VegetablesDocument49 pagesNano-Edible Coatings: A Novel Approach To Improve Shelf Life in VegetablesAnkita SharmaNo ratings yet
- Diversity of Timber Yielding Plants Found in Different Parts of DistrictDocument7 pagesDiversity of Timber Yielding Plants Found in Different Parts of DistrictESSENCE - International Journal for Environmental Rehabilitation and ConservaionNo ratings yet
- Hort 232 Practical ExamDocument1 pageHort 232 Practical ExamVikki Nandeshwar100% (1)
- DalbergiasissooDocument32 pagesDalbergiasissooprajesh612No ratings yet
- Csir Net Examination Life Sciences December 2012 PDFDocument77 pagesCsir Net Examination Life Sciences December 2012 PDFAbhay KumarNo ratings yet
- Pharmacy Practice-VIII (Pharmaceutical Management and Marketing)Document8 pagesPharmacy Practice-VIII (Pharmaceutical Management and Marketing)Umair Mazhar100% (1)
- GroundnutDocument62 pagesGroundnutShiv singh yadavNo ratings yet
- Reviewer LeaDocument13 pagesReviewer LeaChristian AlfornonNo ratings yet
- Effect of Temperature On Crop ProductionDocument14 pagesEffect of Temperature On Crop ProductionKashif Akram100% (1)
- 1-Factorial Experiments PDFDocument14 pages1-Factorial Experiments PDFVikki NandeshwarNo ratings yet
- Cereal Based Cropping System in IndiaDocument20 pagesCereal Based Cropping System in IndiaNicholas Cooper100% (1)
- Green HouseDocument25 pagesGreen Housejayananda yumnam100% (1)
- Plant Disease DiagnosisDocument16 pagesPlant Disease DiagnosisVictor Garcia Jimenez100% (1)
- Transposons in HumansDocument22 pagesTransposons in HumansRishiNo ratings yet
- Institution LandscapingDocument45 pagesInstitution Landscapingyorika moktanNo ratings yet
- 2 Chain SurveyingDocument42 pages2 Chain SurveyingIshtiaq hussainNo ratings yet
- Harmful Effects of Green RevolutionDocument2 pagesHarmful Effects of Green Revolutionniyorraj90No ratings yet
- Kader-6-Maturation and Maturity IndicesDocument8 pagesKader-6-Maturation and Maturity Indicesronalit malintad100% (1)
- ANOVA - Unit II SNMDocument54 pagesANOVA - Unit II SNMS. ASHA ALICE HSCNo ratings yet
- Latin Square Design: ModelDocument5 pagesLatin Square Design: ModelRaShika RashiNo ratings yet
- 1a. 202110 FWA ReviewDocument9 pages1a. 202110 FWA ReviewmaryamNo ratings yet
- Power Electronics and Drives EEE3004 Lab Assessment 1: Reg No: SlotDocument43 pagesPower Electronics and Drives EEE3004 Lab Assessment 1: Reg No: SlotK Lokesh LingaiahNo ratings yet
- Securing and Strengthening 5G Based Iot Infrastructure-An Effort Towards Efficient Iot Using 5GDocument12 pagesSecuring and Strengthening 5G Based Iot Infrastructure-An Effort Towards Efficient Iot Using 5GK Lokesh LingaiahNo ratings yet
- Unit 3 - Variable Frequency Control of Synchronous MotorDocument11 pagesUnit 3 - Variable Frequency Control of Synchronous MotorChinnu ChinniNo ratings yet
- IOT Based Night Patrolling Robot With Arduino and ESP 32Document8 pagesIOT Based Night Patrolling Robot With Arduino and ESP 32K Lokesh LingaiahNo ratings yet
- Semiconductor Devices and Circuits: By: Visweshwar S 19BEE0123 Lokesh K 19BEE0118Document21 pagesSemiconductor Devices and Circuits: By: Visweshwar S 19BEE0123 Lokesh K 19BEE0118K Lokesh LingaiahNo ratings yet
- Induction Motor Speed Control MethodsDocument55 pagesInduction Motor Speed Control MethodsK Lokesh LingaiahNo ratings yet
- Induction Motor Speed Control MethodsDocument55 pagesInduction Motor Speed Control MethodsK Lokesh LingaiahNo ratings yet
- Controlled Rectifiers GuideDocument51 pagesControlled Rectifiers GuideVAHEESNo ratings yet
- 3 Pulse R and RLDocument4 pages3 Pulse R and RLK Lokesh LingaiahNo ratings yet
- Two Transistor Model and Turn On MethodsDocument19 pagesTwo Transistor Model and Turn On MethodsSahale Shera Lutse 18BEE0376No ratings yet
- Controlled Rectifiers GuideDocument51 pagesControlled Rectifiers GuideVAHEESNo ratings yet
- 3 Phase Full Wave Converter - Mine - NewDocument48 pages3 Phase Full Wave Converter - Mine - NewK Lokesh LingaiahNo ratings yet
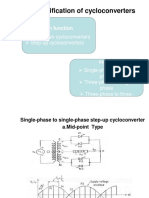
- Classification of Cycloconverters: 1.based On FunctionDocument5 pagesClassification of Cycloconverters: 1.based On FunctionK Lokesh LingaiahNo ratings yet
- Full Converter With RL Load NotesDocument4 pagesFull Converter With RL Load NotesK Lokesh LingaiahNo ratings yet
- Two Transistor Model and Turn On MethodsDocument19 pagesTwo Transistor Model and Turn On MethodsSahale Shera Lutse 18BEE0376No ratings yet
- Performance Parameters NotesDocument2 pagesPerformance Parameters NotesK Lokesh LingaiahNo ratings yet
- Power Electronics: THYRISTOR ProtectionDocument12 pagesPower Electronics: THYRISTOR ProtectionK Lokesh LingaiahNo ratings yet
- Application of Power Diode in Power ElectronicsDocument18 pagesApplication of Power Diode in Power ElectronicsSahale Shera Lutse 18BEE0376No ratings yet
- LAB-12 Chi-Square Test (Independence of Attributes and Goodness of Fit)Document9 pagesLAB-12 Chi-Square Test (Independence of Attributes and Goodness of Fit)K Lokesh LingaiahNo ratings yet
- SCR - VI Characteristics - Switching CharacteristicsDocument50 pagesSCR - VI Characteristics - Switching CharacteristicsSahale Shera Lutse 18BEE0376No ratings yet
- LAB-12 Chi-Square Test (Independence of Attributes and Goodness of Fit)Document9 pagesLAB-12 Chi-Square Test (Independence of Attributes and Goodness of Fit)K Lokesh LingaiahNo ratings yet
- Java ProgrammingDocument127 pagesJava ProgrammingSurya Teja100% (3)
- Neural Network Fuzzy Control 2019-10-20 20.57.48Document1 pageNeural Network Fuzzy Control 2019-10-20 20.57.48K Lokesh LingaiahNo ratings yet
- Applications of Differential and Difference Equations 2019-10-20 21.10.33Document9 pagesApplications of Differential and Difference Equations 2019-10-20 21.10.33K Lokesh LingaiahNo ratings yet
- Engineering Optimization2019-10-20 20.59.45Document1 pageEngineering Optimization2019-10-20 20.59.45K Lokesh LingaiahNo ratings yet
- 4amatlab 2019-10-14 23.31.59 PDFDocument16 pages4amatlab 2019-10-14 23.31.59 PDFK Lokesh LingaiahNo ratings yet
- LAB-12 Chi-Square Test (Independence of Attributes and Goodness of Fit)Document9 pagesLAB-12 Chi-Square Test (Independence of Attributes and Goodness of Fit)K Lokesh LingaiahNo ratings yet
- Water Hardness Using EDTA 2019-09-10 20.21.41 PDFDocument1 pageWater Hardness Using EDTA 2019-09-10 20.21.41 PDFK Lokesh LingaiahNo ratings yet
- Listening Skills 2 2019-10-23 10.15.22Document1 pageListening Skills 2 2019-10-23 10.15.22K Lokesh LingaiahNo ratings yet
- Mathematics 11 Basic Calculus - Stem: Third Quarter - Week 4Document15 pagesMathematics 11 Basic Calculus - Stem: Third Quarter - Week 4Pede CasingNo ratings yet
- Mathematics P2 2020Document32 pagesMathematics P2 2020uzilebanda30No ratings yet
- Laws of Motion Iit &neetDocument14 pagesLaws of Motion Iit &neetIITNo ratings yet
- Applications of Taylor SeriesDocument4 pagesApplications of Taylor Serieschukwu solomonNo ratings yet
- Mathematics Topical Questions and Answers Form 1 4 All Topics 1Document332 pagesMathematics Topical Questions and Answers Form 1 4 All Topics 1tinomuda100% (1)
- PQM Final SPCDocument5 pagesPQM Final SPCgalavaNo ratings yet
- Delhi Public School Bangalore North Mathematics Revision W/S - 2019-20 Fractions and Decimals ClassviiDocument3 pagesDelhi Public School Bangalore North Mathematics Revision W/S - 2019-20 Fractions and Decimals ClassviiVijay KumarNo ratings yet
- HKUST COMP3211 Quiz1 SolutionDocument6 pagesHKUST COMP3211 Quiz1 SolutionTKFNo ratings yet
- Taller II Corte 3Document4 pagesTaller II Corte 3Davidsantiago Murillo AvilaNo ratings yet
- Da MathDocument5 pagesDa MathArvella AlbayNo ratings yet
- ECB 2243-05-Traversing and Coordinat Calculation-NezaDocument25 pagesECB 2243-05-Traversing and Coordinat Calculation-NezaSUNNYWAY CONSTRUCTIONNo ratings yet
- Probabilistic Information Retrieval ModelDocument51 pagesProbabilistic Information Retrieval ModelBirhane Bekele KebedeNo ratings yet
- CIVL 361 Earthwork AnalysisDocument59 pagesCIVL 361 Earthwork AnalysisKave KavinNo ratings yet
- 2021-2022 Math CP S6 Mock Paper 1 (Marking) - v3Document20 pages2021-2022 Math CP S6 Mock Paper 1 (Marking) - v3[5B23] Zhang JiayiNo ratings yet
- Combinational Logic Circuit PDFDocument2 pagesCombinational Logic Circuit PDFChrisNo ratings yet
- Wave HydrodynamicsDocument344 pagesWave HydrodynamicsSathishSrsNo ratings yet
- TD SS1 Easter TermDocument5 pagesTD SS1 Easter TermMorgan InyangNo ratings yet
- STATA Data SummariesDocument15 pagesSTATA Data SummariesjminyosoNo ratings yet
- Characteristics of Hypothesis in Research MethodologyDocument11 pagesCharacteristics of Hypothesis in Research MethodologybaltejNo ratings yet
- Chapter 5Document37 pagesChapter 5Glydel Ann MercadoNo ratings yet
- Research Variables GuideDocument3 pagesResearch Variables GuideClaraNo ratings yet
- DiffusionDocument83 pagesDiffusionmohamedNo ratings yet
- Synonymy: 5 Lexical Semantics: Sense RelationsDocument5 pagesSynonymy: 5 Lexical Semantics: Sense RelationsDjunaidi Komet SharkysNo ratings yet
- 2009amc12 BDocument8 pages2009amc12 BChew Guo QiangNo ratings yet
- The Implementation of A Stochastic Reactor (Stor) Combustion ModelDocument37 pagesThe Implementation of A Stochastic Reactor (Stor) Combustion ModelCarlos AlarconNo ratings yet
- JavaScript: The Programming Language of the WebDocument15 pagesJavaScript: The Programming Language of the WebMary EcargNo ratings yet
- Cubic Spline Interpolation: J. R. ShresthaDocument11 pagesCubic Spline Interpolation: J. R. ShresthaSashank GaudelNo ratings yet
- 100 Question 100 Min. Series ElectrostaticsDocument13 pages100 Question 100 Min. Series Electrostaticsumved singh yadavNo ratings yet
- A New Approach To Linear Filtering and Prediction Problems: R. E. KalmanDocument12 pagesA New Approach To Linear Filtering and Prediction Problems: R. E. KalmanKevinXavierNo ratings yet
- Geometry LabsDocument266 pagesGeometry LabsAnthony Gatchalian100% (1)