You might also like
- Nr2 PrelimsDocument5 pagesNr2 PrelimsCarl Angelo MahaitNo ratings yet
- The Professional Private Investigator Training Manual: Training ManualFrom EverandThe Professional Private Investigator Training Manual: Training ManualRating: 5 out of 5 stars5/5 (1)
- 5thexam Sir Archie Measurement and Data QualityDocument8 pages5thexam Sir Archie Measurement and Data QualityMary Dale Omanea AlmodalNo ratings yet
- Measurement in Nursing ResearchDocument31 pagesMeasurement in Nursing ResearchShaira GumaruNo ratings yet
- Measurement in ResearchDocument40 pagesMeasurement in ResearchAmmadNo ratings yet
- PSYCHSTATSDocument9 pagesPSYCHSTATSJesheryll ReasNo ratings yet
- WK12 Measurement Reliability and ValidityDocument8 pagesWK12 Measurement Reliability and Validitywisdumb rantsNo ratings yet
- Nres2 (My First and Last)Document16 pagesNres2 (My First and Last)Jordan LlegoNo ratings yet
- Chapter 5 - Concepts Operationalization and MeasurementDocument31 pagesChapter 5 - Concepts Operationalization and MeasurementjillianzolliNo ratings yet
- Data and MeasurementDocument21 pagesData and MeasurementKiran SawantNo ratings yet
- Unit 9 Measurements - ShortDocument27 pagesUnit 9 Measurements - ShortMitiku TekaNo ratings yet
- Statistical Analysis - MODULES 1,2 & 3Document19 pagesStatistical Analysis - MODULES 1,2 & 3Allana MierNo ratings yet
- Measurement & Scaling Technique1Document70 pagesMeasurement & Scaling Technique1sonalkumar1989No ratings yet
- (Latest Edited) Full Note Sta404 - 01042022Document108 pages(Latest Edited) Full Note Sta404 - 01042022Tiara SNo ratings yet
- Research MethodologyDocument17 pagesResearch MethodologyJoseph FawzyNo ratings yet
- Data Var2Document21 pagesData Var2Alper GmNo ratings yet
- Course Content: St. Paul University PhilippinesDocument33 pagesCourse Content: St. Paul University PhilippineslucasNo ratings yet
- REVIEWER RDL21st LessonDocument6 pagesREVIEWER RDL21st LessonTodo RokiNo ratings yet
- RM-3 KueDocument41 pagesRM-3 KueElias SeidNo ratings yet
- Researchreviewernijesiah 103229Document16 pagesResearchreviewernijesiah 103229Angela Kim S. BernardinoNo ratings yet
- 3 - Measurement ScaleDocument16 pages3 - Measurement ScaleShubham DixitNo ratings yet
- Goal of Statistics: Decision MakingDocument6 pagesGoal of Statistics: Decision MakingHAP Packers & Shippers Pvt. LimitedNo ratings yet
- ch06 MeasurementDocument33 pagesch06 MeasurementKashaf ButtNo ratings yet
- Reliablity Validity of Research Tools 1Document19 pagesReliablity Validity of Research Tools 1Free Escort Service100% (1)
- CH 13Document26 pagesCH 13Abdul BasitNo ratings yet
- Research Cha 7... 5m....Document15 pagesResearch Cha 7... 5m....RINU E ONo ratings yet
- FM 16 Notes Chapter 1Document2 pagesFM 16 Notes Chapter 1Jason AbanesNo ratings yet
- Measurement and ScalingDocument24 pagesMeasurement and ScalingAbou-Bakar JavedNo ratings yet
- Design Science Research Methods: By: Hussain NaushadDocument28 pagesDesign Science Research Methods: By: Hussain NaushadM. AmirNo ratings yet
- Introduction To Data Analysis in An EvidenceDocument4 pagesIntroduction To Data Analysis in An EvidenceSherrie Ann Delos SantosNo ratings yet
- BRM Chap 13Document28 pagesBRM Chap 13Vineet SuranaNo ratings yet
- Basic Concepts in StatisticsDocument19 pagesBasic Concepts in StatisticsMILBERT DE GRACIANo ratings yet
- Reviewer For Clinical PsychDocument21 pagesReviewer For Clinical PsychValerie FallerNo ratings yet
- Business Statistics: MBBA 501 First Semester, 2021-2022Document39 pagesBusiness Statistics: MBBA 501 First Semester, 2021-2022Maricon DimaunahanNo ratings yet
- Unit 3: Scale and MeasurementDocument77 pagesUnit 3: Scale and MeasurementkiomarsNo ratings yet
- LAS 3.4 Basic Statistics in Experimental Research No Answer KeyDocument6 pagesLAS 3.4 Basic Statistics in Experimental Research No Answer KeyErah Kim GomezNo ratings yet
- W6 - Measurement in Quantitative ResearchDocument5 pagesW6 - Measurement in Quantitative ResearchZuhair AqeelNo ratings yet
- Quantitative Research VariablesDocument62 pagesQuantitative Research VariablesJamaica Aranas LorellaNo ratings yet
- StatsDocument11 pagesStatsAkirha SoNo ratings yet
- 4 Data Analysis1Document32 pages4 Data Analysis1Mohamad AdibNo ratings yet
- Statistics LectureDocument35 pagesStatistics LectureEPOY JERSNo ratings yet
- BRM Chap 13Document46 pagesBRM Chap 13pallavi412No ratings yet
- BRM Measurement and Scale 2019Document50 pagesBRM Measurement and Scale 2019MEDISHETTY MANICHANDANANo ratings yet
- Informative Digital Poster SampleDocument1 pageInformative Digital Poster Samplekcx6g8dzdjNo ratings yet
- Chapter 1 OverviewDocument18 pagesChapter 1 OverviewCHEIKH SAD BOUH / UPMNo ratings yet
- CH IV. Measurement and ScalingDocument51 pagesCH IV. Measurement and ScalingBandana SigdelNo ratings yet
- Definitions in Statistics - 01Document43 pagesDefinitions in Statistics - 01Prudence MasimbeNo ratings yet
- Measurement and Scale Construction TechniquesDocument61 pagesMeasurement and Scale Construction TechniquesAbhishek kumarNo ratings yet
- Biostatistics PrelimDocument7 pagesBiostatistics PrelimLykisha Larraine CosmianoNo ratings yet
- PR2 ReviewerDocument4 pagesPR2 ReviewerMarlian ElgincolinNo ratings yet
- Module 3 - Statistics RefresherDocument16 pagesModule 3 - Statistics RefresherTapia, DarleenNo ratings yet
- Chapter 5 - Measurement TechniquesDocument46 pagesChapter 5 - Measurement TechniquesFarah A. RadiNo ratings yet
- Psych Assess NotesDocument10 pagesPsych Assess NotesASHLEA JANE VILBARNo ratings yet
- Pertemuan 2-Skala Pengukuran Dan Ukuran DataDocument96 pagesPertemuan 2-Skala Pengukuran Dan Ukuran DataRestu BisnisNo ratings yet
- Unit 7Document19 pagesUnit 7Susshmita UpadhayaNo ratings yet
- Quantitative Measurement, Reliablity, ValidityDocument36 pagesQuantitative Measurement, Reliablity, ValidityDiana Rizky YulizaNo ratings yet
- Data Anal NotesDocument10 pagesData Anal Notesnhisaalmoite1No ratings yet
- Statistics 1A Lecture Notes ArticleDocument123 pagesStatistics 1A Lecture Notes ArticleEnKay 11No ratings yet
- Techniques of Data CollectionDocument12 pagesTechniques of Data Collectionarinda franklinNo ratings yet
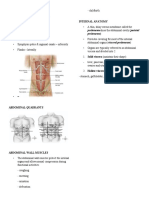
- The Abdomen: E Sther Sunday C. Faller, RMT, MDDocument7 pagesThe Abdomen: E Sther Sunday C. Faller, RMT, MDMarimiel PagulayanNo ratings yet
- Activities in Health AssessmentDocument7 pagesActivities in Health AssessmentMarimiel PagulayanNo ratings yet
- Researcher 4Document14 pagesResearcher 4Marimiel PagulayanNo ratings yet
- PAGULAYAN, M - Week1ReflectionJournal109Document2 pagesPAGULAYAN, M - Week1ReflectionJournal109Marimiel PagulayanNo ratings yet
- Assignment IN Health Assessment: Brgy.96, Calanipawan Road, Tacloban City, 6500Document7 pagesAssignment IN Health Assessment: Brgy.96, Calanipawan Road, Tacloban City, 6500Marimiel PagulayanNo ratings yet
- Anti-Parkinsonian Drugs: Lecturer: Sir Mark Angelo Cristino - 24 March 2022Document6 pagesAnti-Parkinsonian Drugs: Lecturer: Sir Mark Angelo Cristino - 24 March 2022Marimiel PagulayanNo ratings yet
- Requirements in Ob Ward: High Risk (September 21, 2021) : College of NursingDocument17 pagesRequirements in Ob Ward: High Risk (September 21, 2021) : College of NursingMarimiel PagulayanNo ratings yet
- Pedia Comprehensive Questionaire GuideDocument14 pagesPedia Comprehensive Questionaire GuideMarimiel PagulayanNo ratings yet
- 2 Community Organizing Rances Montibon NaridoDocument6 pages2 Community Organizing Rances Montibon NaridoMarimiel PagulayanNo ratings yet
- Ectopic Pregnancy - PathophysiologyDocument1 pageEctopic Pregnancy - PathophysiologyMarimiel PagulayanNo ratings yet
- Acetyl-L-carnitine:: 3.3: Introduction To Psychotropic DrugsDocument11 pagesAcetyl-L-carnitine:: 3.3: Introduction To Psychotropic DrugsMarimiel PagulayanNo ratings yet
- Specific Types of Quantitative ResearchDocument4 pagesSpecific Types of Quantitative ResearchMarimiel PagulayanNo ratings yet
- Spiritual Needs of A Patient With Acute IllnessDocument3 pagesSpiritual Needs of A Patient With Acute IllnessMarimiel PagulayanNo ratings yet
- Quadruple Aim in HealthcareDocument2 pagesQuadruple Aim in HealthcareMarimiel PagulayanNo ratings yet
- Community Organizing Three Basic Rights: 1.: Copar/CbprDocument7 pagesCommunity Organizing Three Basic Rights: 1.: Copar/CbprMarimiel PagulayanNo ratings yet
- Eastern Visayas Regional Medical Center: Tacloban City, Philippines, 6500Document1 pageEastern Visayas Regional Medical Center: Tacloban City, Philippines, 6500Marimiel PagulayanNo ratings yet
- CHN2 Environmental Health and SanitationDocument8 pagesCHN2 Environmental Health and SanitationMarimiel PagulayanNo ratings yet
- Ret Dem or PRSDocument4 pagesRet Dem or PRSMarimiel PagulayanNo ratings yet
- Doña Remedios Trinidad Romualdez Medical Foundation College of Nursing Performance Evaluation Checklist Musculoskeletal AssessmentDocument1 pageDoña Remedios Trinidad Romualdez Medical Foundation College of Nursing Performance Evaluation Checklist Musculoskeletal AssessmentMarimiel PagulayanNo ratings yet
- Nursing Assessment of Spiritual NeedsDocument5 pagesNursing Assessment of Spiritual NeedsMarimiel PagulayanNo ratings yet
- Middle-Range Theory of Spiritual Well-Being in IllnessDocument4 pagesMiddle-Range Theory of Spiritual Well-Being in IllnessMarimiel PagulayanNo ratings yet
- A Spiritual History of NursingDocument9 pagesA Spiritual History of NursingMarimiel Pagulayan100% (1)
- Suicide Prevention Awareness September 17 2021Document46 pagesSuicide Prevention Awareness September 17 2021Adrian CalubayanNo ratings yet
- Lesson Plan For DemonstrationDocument7 pagesLesson Plan For DemonstrationMa'am Ester S. BambaNo ratings yet
- Felman Turning The Screw of Interpretation PDFDocument115 pagesFelman Turning The Screw of Interpretation PDFsammyfenNo ratings yet
- Community Mobilization in AECD FInal NoteDocument35 pagesCommunity Mobilization in AECD FInal NoteRyizcNo ratings yet
- Community and Health For Med Lab Science CPH - Lecture Finals - 2 SemesterDocument29 pagesCommunity and Health For Med Lab Science CPH - Lecture Finals - 2 SemesterJanickee Faye BALIGNOTNo ratings yet
- PAF-Shiela Marie IsidroDocument2 pagesPAF-Shiela Marie IsidroShiela Marie IsidroNo ratings yet
- 7es Lesson PlanDocument3 pages7es Lesson PlanEZAR-casticNo ratings yet
- Communication Studies SBADocument11 pagesCommunication Studies SBAshylaNo ratings yet
- Jimmy Delgado Web Page SearchDocument4 pagesJimmy Delgado Web Page SearchLaura Magalys Chacon MendozaNo ratings yet
- Understanding The Dreams You Dream Revised and Expanded Read Free Books and Download EbooksDocument5 pagesUnderstanding The Dreams You Dream Revised and Expanded Read Free Books and Download EbooksChegwe Cornelius0% (1)
- Gen 002 Reviewer SAS 8Document3 pagesGen 002 Reviewer SAS 8KaartianeNo ratings yet
- Ernestine WiedenbachDocument7 pagesErnestine WiedenbachVien WhitlockNo ratings yet
- Is Literature Review Qualitative or QuantitativeDocument5 pagesIs Literature Review Qualitative or Quantitativeafmzhpeloejtzj100% (1)
- Complaint Filed With Washington Board of Medicine Re Treating Psychiatrists - August 20 1993Document11 pagesComplaint Filed With Washington Board of Medicine Re Treating Psychiatrists - August 20 1993Gary FreedmanNo ratings yet
- Academic Writing - Opinion EssayDocument2 pagesAcademic Writing - Opinion EssayAsya ÖzparlakNo ratings yet
- Chapter 5 Statement of The ProblemDocument21 pagesChapter 5 Statement of The ProblemJanzell Anne Borja AlbaniaNo ratings yet
- Code of Ethics-American Counseling AssociationDocument51 pagesCode of Ethics-American Counseling AssociationJohn Carlo PerezNo ratings yet
- Jflowershealth Wellness Wheel WorksheetDocument1 pageJflowershealth Wellness Wheel WorksheetchoiNo ratings yet
- Peplau's Nursing Theory (Theory of Interpersonal Relation)Document11 pagesPeplau's Nursing Theory (Theory of Interpersonal Relation)Gayatri Mudliyar100% (1)
- PsychologicallyDocument6 pagesPsychologicallyLaura IsabelNo ratings yet
- Capability Approach To DevelopmentDocument14 pagesCapability Approach To DevelopmentGunjan ChoudharyNo ratings yet
- Houses 101 WorksheetDocument7 pagesHouses 101 WorksheetLia SantchirdNo ratings yet
- Aud 0000000000000423Document11 pagesAud 0000000000000423CoAsst MuhammadNuhAlhudawyNo ratings yet
- Introduction: A New Hierarchy of NeedsDocument5 pagesIntroduction: A New Hierarchy of Needsgun2 block100% (1)
- Essay On Gaza WarDocument8 pagesEssay On Gaza Warafabkgddu100% (2)
- Color Therapy by Lacramioara BledeaDocument7 pagesColor Therapy by Lacramioara BledeaLily BledeaNo ratings yet
- Module 9 Personal RelationshipDocument13 pagesModule 9 Personal Relationshipprincess3canlasNo ratings yet
- DRUG-SYMPOSIUM (Macabalan)Document51 pagesDRUG-SYMPOSIUM (Macabalan)Seagal UmarNo ratings yet
- Clinical Performance Development and Management SystemDocument26 pagesClinical Performance Development and Management SystemJuanaNo ratings yet
- MKBS 317 - Group AssignmentDocument4 pagesMKBS 317 - Group AssignmentMbali MdlaloseNo ratings yet