You might also like
- Simple Linear Regression in RDocument17 pagesSimple Linear Regression in RGianni GorgoglioneNo ratings yet
- August Morning WorkDocument20 pagesAugust Morning Workapi-471325484No ratings yet
- COE10205, Other Corrosion Monitoring TechniquesDocument62 pagesCOE10205, Other Corrosion Monitoring Techniquesامين100% (1)
- Piperack Design PhiloshipyDocument10 pagesPiperack Design PhiloshipyGautam PaulNo ratings yet
- Simpack Off-Line and Real Time SimulationDocument23 pagesSimpack Off-Line and Real Time SimulationAnderson ZambrzyckiNo ratings yet
- English P5 TGDocument133 pagesEnglish P5 TGIradukunda PatrickNo ratings yet
- Solutions Manual to accompany Introduction to Linear Regression AnalysisFrom EverandSolutions Manual to accompany Introduction to Linear Regression AnalysisRating: 1 out of 5 stars1/5 (1)
- Laser PsicosegundoDocument14 pagesLaser PsicosegundoCristiane RalloNo ratings yet
- Integer Optimization and its Computation in Emergency ManagementFrom EverandInteger Optimization and its Computation in Emergency ManagementNo ratings yet
- A1w2017 PDFDocument2 pagesA1w2017 PDFSarika UppalNo ratings yet
- Quiz Questions on Regression Analysis and CorrelationDocument10 pagesQuiz Questions on Regression Analysis and CorrelationHarsh ShrinetNo ratings yet
- Correlation and Regression Skill SetDocument8 pagesCorrelation and Regression Skill SetKahloon ThamNo ratings yet
- Data Analysis Assignment HelpDocument8 pagesData Analysis Assignment HelpStatistics Homework SolverNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6yitagesu eshetuNo ratings yet
- Assignment 1 - AnswerDocument11 pagesAssignment 1 - AnswerNurliani Mohd IsaNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- PLDocument5 pagesPLMy SpotifyNo ratings yet
- Ptest 2 v1mrs ch9Document7 pagesPtest 2 v1mrs ch9Solanchs SotoNo ratings yet
- All All: % (A) Construct Side-By-Side Stem-And-Leaf PlotsDocument34 pagesAll All: % (A) Construct Side-By-Side Stem-And-Leaf PlotsJASHWIN GAUTAMNo ratings yet
- MI-362 MI-362Tutorial 3 MI362Document1 pageMI-362 MI-362Tutorial 3 MI362Shubham BansalNo ratings yet
- Tugas Statel IndividuDocument17 pagesTugas Statel IndividuNur HafizahNo ratings yet
- Confidence LevelDocument31 pagesConfidence LevelMuhammad Nauman UsmaniNo ratings yet
- Significant Figures, Scientific Notation and Metric PrefixesDocument3 pagesSignificant Figures, Scientific Notation and Metric PrefixesmphoNo ratings yet
- Fitting Linear and Quadratic Regression ModelsDocument4 pagesFitting Linear and Quadratic Regression ModelsPragyan NandaNo ratings yet
- Stat 305 Final Practice - SolutionsDocument10 pagesStat 305 Final Practice - SolutionsMorgan SanchezNo ratings yet
- Econometrics Assignment 2Document3 pagesEconometrics Assignment 2Peter ChenzaNo ratings yet
- Final Review QuestionsDocument5 pagesFinal Review QuestionsJeremy PearsonNo ratings yet
- Problem Set 3Document2 pagesProblem Set 3dxd032No ratings yet
- Problemas Bono para Tercer Examen de Estadística - Verano 2012Document8 pagesProblemas Bono para Tercer Examen de Estadística - Verano 2012David Meza CarbajalNo ratings yet
- Probability and Statistics With R For Engineers and Scientists 1St Edition Michael Akritas Solutions Manual Full Chapter PDFDocument35 pagesProbability and Statistics With R For Engineers and Scientists 1St Edition Michael Akritas Solutions Manual Full Chapter PDFEarlCollinsmapcs100% (8)
- Variance CovarianceDocument6 pagesVariance CovarianceJoseph JoeNo ratings yet
- University of Michigan STATS 500 hw3 F2020Document2 pagesUniversity of Michigan STATS 500 hw3 F2020wasabiwafflesNo ratings yet
- RegressionDocument6 pagesRegressionmirelaasmanNo ratings yet
- Programming With R Test 2Document5 pagesProgramming With R Test 2KamranKhan50% (2)
- Final SolDocument5 pagesFinal SolcesardakoNo ratings yet
- Mathematical Modelling: 6.1 Development of A Mathematical ModelDocument9 pagesMathematical Modelling: 6.1 Development of A Mathematical ModelMahesh PatilNo ratings yet
- Introduction to Model Parameter EstimationDocument37 pagesIntroduction to Model Parameter EstimationKutha ArdanaNo ratings yet
- Data Analysis Exam HelpDocument8 pagesData Analysis Exam HelpStatistics Exam HelpNo ratings yet
- Computational Techniques in Statistics: Exercise 1Document5 pagesComputational Techniques in Statistics: Exercise 1وجدان الشداديNo ratings yet
- Explains The Relationship Between Cost The Number of PassengersDocument2 pagesExplains The Relationship Between Cost The Number of PassengersRay Francis TanchulingNo ratings yet
- Project1Report (Prakash)Document12 pagesProject1Report (Prakash)pgnepal100% (1)
- MIT18 05S14 Prac Fnal ExmDocument8 pagesMIT18 05S14 Prac Fnal ExmIslamSharafNo ratings yet
- Lab 1: Model SelectionDocument6 pagesLab 1: Model SelectionthomasverbekeNo ratings yet
- Homework 3Document6 pagesHomework 3maxNo ratings yet
- PhD Econ Applied Econometrics 2021/22 TakehomeDocument20 pagesPhD Econ Applied Econometrics 2021/22 TakehomeKarim BekhtiarNo ratings yet
- Polynomial Curve Fitting in MatlabDocument3 pagesPolynomial Curve Fitting in MatlabKhan Arshid IqbalNo ratings yet
- Lecture 6Document3 pagesLecture 6Syeda Umyma FaizNo ratings yet
- ML Lab - Sukanya RajaDocument23 pagesML Lab - Sukanya RajaRick MitraNo ratings yet
- ECON310 Q1 - KeyDocument5 pagesECON310 Q1 - KeyRefiye ÇakmakNo ratings yet
- Individual Homework #3 Design of Experiment AnalysisDocument6 pagesIndividual Homework #3 Design of Experiment AnalysisstudycamNo ratings yet
- Reservoir Characterisation 2012Document7 pagesReservoir Characterisation 2012T C0% (1)
- Assignments Module03Document9 pagesAssignments Module03Jessica jesNo ratings yet
- Numerical Methods for Civil Engineers: Linear RegressionDocument34 pagesNumerical Methods for Civil Engineers: Linear Regressionsohail66794154No ratings yet
- Hypothesis Testing SeminarDocument10 pagesHypothesis Testing SeminarJacky C.Y. HoNo ratings yet
- Estimation ProblemsDocument4 pagesEstimation ProblemsAnkur GuptaNo ratings yet
- Validación Formulario CMM y Software Evaluación ToleranciaDocument10 pagesValidación Formulario CMM y Software Evaluación ToleranciaAdolfo RodriguezNo ratings yet
- Industrial Statistics - A Computer Based Approach With PythonDocument140 pagesIndustrial Statistics - A Computer Based Approach With PythonhtapiaqNo ratings yet
- Numerical Solution of Ordinary Differential Equations Part 5 - Least Square RegressionDocument23 pagesNumerical Solution of Ordinary Differential Equations Part 5 - Least Square RegressionMelih TecerNo ratings yet
- RegressionDocument6 pagesRegressionmalp23No ratings yet
- L.J. Institute MCA Numerical Methods Question BankDocument5 pagesL.J. Institute MCA Numerical Methods Question BankconmngNo ratings yet
- Simple Linear Regression (Solutions To Exercises)Document28 pagesSimple Linear Regression (Solutions To Exercises)blu runner1No ratings yet
- 06 05 Adequacy of Regression ModelsDocument11 pages06 05 Adequacy of Regression ModelsJohn Bofarull GuixNo ratings yet
- Quess 2: The 95% Confidence Interval For The Population Proportion P Is (0.1608, 0.2392)Document7 pagesQuess 2: The 95% Confidence Interval For The Population Proportion P Is (0.1608, 0.2392)Tajinder SinghNo ratings yet
- MATLAB Lecture 3. Polynomials and Curve Fitting PDFDocument3 pagesMATLAB Lecture 3. Polynomials and Curve Fitting PDFTan HuynhNo ratings yet
- Integrated Neurology MCQ'sDocument5 pagesIntegrated Neurology MCQ'sStella ParkerNo ratings yet
- Notes On Errors of Refraction by DR Sudha Seetharam PW Med EdDocument1 pageNotes On Errors of Refraction by DR Sudha Seetharam PW Med EdStella ParkerNo ratings yet
- Practical 7 BoneDocument3 pagesPractical 7 BoneStella ParkerNo ratings yet
- Medicine FMGE Sprint by Dr. Santosh Patil (PW Med Ed)Document31 pagesMedicine FMGE Sprint by Dr. Santosh Patil (PW Med Ed)Stella ParkerNo ratings yet
- General Anatomy QuestionsDocument1 pageGeneral Anatomy QuestionsStella ParkerNo ratings yet
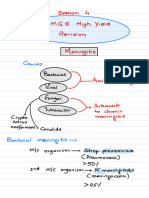
- Session 4Document19 pagesSession 4Stella ParkerNo ratings yet
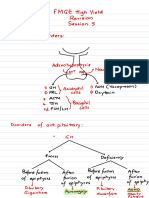
- Session 3 SupplementDocument8 pagesSession 3 SupplementStella ParkerNo ratings yet
- Shiv Ashish Revision Sheet Physics ProblemsDocument2 pagesShiv Ashish Revision Sheet Physics ProblemsStella ParkerNo ratings yet
- ETS and ATP Synthesis ExplainedDocument19 pagesETS and ATP Synthesis ExplainedStella ParkerNo ratings yet
- Session 5 EndocrinologyDocument21 pagesSession 5 EndocrinologyStella ParkerNo ratings yet
- The Cell UltimateDocument164 pagesThe Cell UltimateStella ParkerNo ratings yet
- Electric Machine Design 01 Electric Machine DesignDocument10 pagesElectric Machine Design 01 Electric Machine Designkhodabandelou100% (1)
- Cryptography and Network Security": Sir Syed University of Engineering & TechnologyDocument5 pagesCryptography and Network Security": Sir Syed University of Engineering & TechnologySehar KhanNo ratings yet
- MR Explorer: Magnetic Resonance Logging ServiceDocument7 pagesMR Explorer: Magnetic Resonance Logging ServiceRoberto DominguezNo ratings yet
- Management Science PDFDocument131 pagesManagement Science PDFAngela Lei SanJuan BucadNo ratings yet
- Oc Curve BasicsDocument25 pagesOc Curve BasicsRohit SoniNo ratings yet
- Call Log ReportDocument44 pagesCall Log ReportHun JhayNo ratings yet
- Certificate of Incorporation Phlips India LimitedDocument1 pageCertificate of Incorporation Phlips India LimitedRam AgarwalNo ratings yet
- Resume summary of monthly sparepart costs and production in 2021Document590 pagesResume summary of monthly sparepart costs and production in 2021winda listya ningrumNo ratings yet
- 4.2 Force and Motion 1Document19 pages4.2 Force and Motion 1ammarsyahmiNo ratings yet
- Tutorial Chapter 1 Thermochemistry QuestionsDocument4 pagesTutorial Chapter 1 Thermochemistry Questionssiti nur masyitah nasaruddinNo ratings yet
- Homework1 SKKK1113 1112-2Document1 pageHomework1 SKKK1113 1112-2Khairul Anwar Abd HamidNo ratings yet
- Chapter 14: Redundant Arithmetic: Keshab K. ParhiDocument21 pagesChapter 14: Redundant Arithmetic: Keshab K. ParhiInJune YeoNo ratings yet
- BrochureDocument2 pagesBrochureNarayanaNo ratings yet
- 3.4 Linearization of Nonlinear State Space Models: 1 F X Op 1 F X Op 2 F U Op 1 F U Op 2Document3 pages3.4 Linearization of Nonlinear State Space Models: 1 F X Op 1 F X Op 2 F U Op 1 F U Op 2Ilija TomicNo ratings yet
- EPI Manual Part1 2013 2Document350 pagesEPI Manual Part1 2013 2digger1833No ratings yet
- PqdifsdkDocument2 pagesPqdifsdkrafaelcbscribdNo ratings yet
- Jhamuna Tower Design DataDocument15 pagesJhamuna Tower Design DataArindam RoyNo ratings yet
- Group Case Study: Premier Automotive Services LimitedDocument2 pagesGroup Case Study: Premier Automotive Services LimitedKryzel Jean Tumbaga ValdezNo ratings yet
- Cylinder Head Cover, 6T-830 and 6ta-830 Emissions Certified EngineDocument3 pagesCylinder Head Cover, 6T-830 and 6ta-830 Emissions Certified EngineJose A PerezNo ratings yet
- How to Critique a Work in 40 StepsDocument16 pagesHow to Critique a Work in 40 StepsGavrie TalabocNo ratings yet
- Data Table CarbonDocument2 pagesData Table Carbonyodaswarrior33% (15)
- IEU - BBA - Final Project - Business Plan - Guidelines and Requirements - v02.07Document11 pagesIEU - BBA - Final Project - Business Plan - Guidelines and Requirements - v02.07Jorge Eduardo Ortega PalaciosNo ratings yet
- Cesp 105 - Foundation Engineering and Retaining Wall Design Lesson 11. Structural Design of Spread FootingDocument7 pagesCesp 105 - Foundation Engineering and Retaining Wall Design Lesson 11. Structural Design of Spread FootingJadeNo ratings yet
- Products For Enhanced Oil RecoveryDocument4 pagesProducts For Enhanced Oil RecoverypmarteeneNo ratings yet