You might also like
- Rainfall - Prediction - Ipynb - ColaboratoryDocument10 pagesRainfall - Prediction - Ipynb - Colaboratoryprarabdhasharma98No ratings yet
- A Survey of Computational Physics: Introductory Computational ScienceFrom EverandA Survey of Computational Physics: Introductory Computational ScienceNo ratings yet
- RainFall - Prediction - Ipynb - ColaboratoryDocument7 pagesRainFall - Prediction - Ipynb - ColaboratoryBalaji ChowdaryNo ratings yet
- Earthquake PredictionDocument10 pagesEarthquake Predictionkinglegend3103No ratings yet
- Basics of ClusteringDocument19 pagesBasics of ClusteringAbel MontielNo ratings yet
- New ANN-Copy1Document1 pageNew ANN-Copy1raveendrareddyeeeNo ratings yet
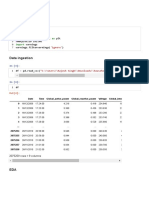
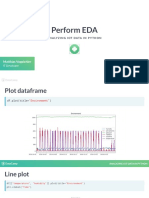
- Column - Nam Es: Exploratory Data Analysis: Exploratory Data Analysis (EDA) Is A Process of Performing InitialDocument10 pagesColumn - Nam Es: Exploratory Data Analysis: Exploratory Data Analysis (EDA) Is A Process of Performing InitialSaurabhNo ratings yet
- Network Simulator (NS-2)Document60 pagesNetwork Simulator (NS-2)devarum100% (1)
- Period Start Time PLMN Name: Voice Call Setup SR (Rrc+Cu) CSSR Ps NRT RrcblockingcongestioncsDocument44 pagesPeriod Start Time PLMN Name: Voice Call Setup SR (Rrc+Cu) CSSR Ps NRT RrcblockingcongestioncsdanielNo ratings yet
- Total Alarm Count Alarm Text: Data - 1Document14 pagesTotal Alarm Count Alarm Text: Data - 1Manu KulshreshthaNo ratings yet
- Task 1Document9 pagesTask 1vansh.jain2021No ratings yet
- American Airlines Flight Arrival Delay AnalysisDocument11 pagesAmerican Airlines Flight Arrival Delay AnalysisHyder MurtazaNo ratings yet
- Period Start Time PLMN Name: Voice Call Setup SR (Rrc+Cu) CSSR Ps NRT RrcblockingcongestioncsDocument44 pagesPeriod Start Time PLMN Name: Voice Call Setup SR (Rrc+Cu) CSSR Ps NRT Rrcblockingcongestioncsdenoo williamNo ratings yet
- Qian Attentive Generative Adversarial CVPR 2018 PaperDocument10 pagesQian Attentive Generative Adversarial CVPR 2018 PaperVishal PurohitNo ratings yet
- CleaningData Chapter 1 With RDocument21 pagesCleaningData Chapter 1 With RMahmoud TriguiNo ratings yet
- Solar Power Plant AbnormalitiesDocument26 pagesSolar Power Plant Abnormalitiesedsf70No ratings yet
- IdePix Sentinel-3 OLCI ATBD v1.0Document25 pagesIdePix Sentinel-3 OLCI ATBD v1.0Dilipkumar J oe18d018No ratings yet
- Cloud and Shadow Detection and Removal For Landsat-8 DataDocument10 pagesCloud and Shadow Detection and Removal For Landsat-8 DataoktianaNo ratings yet
- CleaningDocument1 pageCleaningmirziauddinNo ratings yet
- News Network AnalysisDocument23 pagesNews Network AnalysisKaartik ModiNo ratings yet
- Google Earth ConferenceDocument92 pagesGoogle Earth ConferenceYecid Alberto Mateus PradaNo ratings yet
- CLEANING DATA SET - Jupyter NotebookDocument15 pagesCLEANING DATA SET - Jupyter Notebooknitindibai3No ratings yet
- Lab 7Document6 pagesLab 7RAGURU NISHIKANTH REDDY 20BLC1045No ratings yet
- GPS BasicDocument4 pagesGPS BasicrameshNo ratings yet
- Chapter5-Case Study Analyzing Flight DelaysDocument32 pagesChapter5-Case Study Analyzing Flight DelaysKomi David ABOTSITSENo ratings yet
- Decision Tree Regressor and Ensemble Techniques - RegressorsDocument18 pagesDecision Tree Regressor and Ensemble Techniques - RegressorsS ANo ratings yet
- LogDocument5 pagesLogLa rudianto La rudianto la ariyantoNo ratings yet
- EDA - Ciclo2022 - 2 - EstadisticaByvariadaDocument9 pagesEDA - Ciclo2022 - 2 - EstadisticaByvariadaRicardo CremaNo ratings yet
- Projection BasicsDocument12 pagesProjection BasicsMatheus PalujayNo ratings yet
- 10KWp Landscape Structure - 3m Super Structure For 200KmphDocument97 pages10KWp Landscape Structure - 3m Super Structure For 200KmphRajat MarvalNo ratings yet
- LogDocument8 pagesLogMelani AmandaNo ratings yet
- Linear Regression and SVRDocument25 pagesLinear Regression and SVRARCHANA RNo ratings yet
- Krishna - Chavda - I077 - 60003220149 - CN - Experiment 4Document6 pagesKrishna - Chavda - I077 - 60003220149 - CN - Experiment 4www.krishnachavda9No ratings yet
- MLT Use CaseDocument13 pagesMLT Use Casemanchal2204No ratings yet
- Sip ML 2020 Forecasting e FC WeatherDocument21 pagesSip ML 2020 Forecasting e FC WeatherJuan Carlos Olivares RojasNo ratings yet
- Snow Layer Prediction Model Using Back Scattering Co-EfficientDocument7 pagesSnow Layer Prediction Model Using Back Scattering Co-EfficientIJRASETPublicationsNo ratings yet
- Period Start Time Mrbts/Sbts Namelnbts Type Lnbts NameDocument24 pagesPeriod Start Time Mrbts/Sbts Namelnbts Type Lnbts NamedanielNo ratings yet
- Genna Donchyts - GEE TrainingDocument48 pagesGenna Donchyts - GEE TrainingAbi AeeraNo ratings yet
- Estudio Comparativo de Las Bases de Datos de RadiaciónDocument9 pagesEstudio Comparativo de Las Bases de Datos de RadiaciónMario PerezNo ratings yet
- Xavier's Institute of Engineering, Mumbai: Session 1Document43 pagesXavier's Institute of Engineering, Mumbai: Session 1Harsh ParekhNo ratings yet
- Heat Equation Matlab CodeDocument12 pagesHeat Equation Matlab CodeSakil MollahNo ratings yet
- IS2SITMOGR4 V001 UserGuideDocument8 pagesIS2SITMOGR4 V001 UserGuideyizhoupoNo ratings yet
- Operation Analytics and Investigating Metric SpikeDocument20 pagesOperation Analytics and Investigating Metric Spikehedator300No ratings yet
- RunCrossCorrelations AcrossSmallArray PlotAndMapResults-forStudents-AfterCompletingRunningDocument75 pagesRunCrossCorrelations AcrossSmallArray PlotAndMapResults-forStudents-AfterCompletingRunningAde Surya PutraNo ratings yet
- Final Report 1301174460 1301174539 AMLdocxDocument12 pagesFinal Report 1301174460 1301174539 AMLdocxwindaNo ratings yet
- Amazon Stocks PriceDocument16 pagesAmazon Stocks PriceDineshkumar VhananavarNo ratings yet
- Exploratory Data Analysis and Forecasting The Output Power Generated by Solar PhotovoltaicDocument13 pagesExploratory Data Analysis and Forecasting The Output Power Generated by Solar PhotovoltaicIJRASETPublications100% (1)
- An Interactive Framework For Analysis of Weather Prediction Using Digital Image ProcessingDocument8 pagesAn Interactive Framework For Analysis of Weather Prediction Using Digital Image ProcessingInternational Journal of Innovative Science and Research Technology100% (1)
- Pronosticos - Ipynb - ColaboratoryDocument13 pagesPronosticos - Ipynb - ColaboratoryFrancisco Javier RESTREPO GRANOBLESNo ratings yet
- Multisensor Data Fusion For Cloud Removal in Global and All-Season Sentinel-2 ImageryDocument13 pagesMultisensor Data Fusion For Cloud Removal in Global and All-Season Sentinel-2 ImageryOdeNo ratings yet
- 20CS2018L Design and Analysis of Algorithms: 1 2 From Sys Import Maxsize Def Min - Index (Dist, Vis)Document3 pages20CS2018L Design and Analysis of Algorithms: 1 2 From Sys Import Maxsize Def Min - Index (Dist, Vis)Alan DanielsNo ratings yet
- 7-8 Feature Engineering 101-NormalizationDocument8 pages7-8 Feature Engineering 101-NormalizationKhan RafiNo ratings yet
- Lab 4Document14 pagesLab 4ShinchanNo ratings yet
- S191129u PDFDocument9 pagesS191129u PDFASHINI MODINo ratings yet
- P1 STD - AnalysisReport - CIFSDocument6 pagesP1 STD - AnalysisReport - CIFSJagannath A RaoNo ratings yet
- 3G KPIS SWAP-WS RSRAN-WBTS-day-PM 17363-2020 12 06-20 08 10 175Document59 pages3G KPIS SWAP-WS RSRAN-WBTS-day-PM 17363-2020 12 06-20 08 10 175danielNo ratings yet
- Analyzing IoT Data in Python Chapter2Document35 pagesAnalyzing IoT Data in Python Chapter2FgpeqwNo ratings yet
- Mod07 Qc.a2019257.0255.061.2019257132041Document188 pagesMod07 Qc.a2019257.0255.061.2019257132041Sartika SaidNo ratings yet
- Zendel Unifying Panoptic Segmentation For Autonomous Driving CVPR 2022 PaperDocument10 pagesZendel Unifying Panoptic Segmentation For Autonomous Driving CVPR 2022 PaperAndroid HackerNo ratings yet
- Seaborn Cheat SheetDocument48 pagesSeaborn Cheat SheetAntonio FernandezNo ratings yet
- Applsci 12 01409Document14 pagesApplsci 12 01409Antonio FernandezNo ratings yet
- Lendario de Actividades de Evaluación Continua Comunes A Todos Los Grupos de La AsignaturaDocument3 pagesLendario de Actividades de Evaluación Continua Comunes A Todos Los Grupos de La AsignaturaAntonio FernandezNo ratings yet
- Ex MLDocument33 pagesEx MLAntonio FernandezNo ratings yet
- ML Notesv1Document300 pagesML Notesv1Antonio Fernandez100% (1)
- 75 BottanietalDocument8 pages75 BottanietalAntonio FernandezNo ratings yet
- 1 s2.0 S1270963821005198 MainDocument20 pages1 s2.0 S1270963821005198 MainAntonio FernandezNo ratings yet
- AWE PHD Opportunity UC3MDocument2 pagesAWE PHD Opportunity UC3MAntonio FernandezNo ratings yet
- Calendario - 2020 2021 - Master - Habil - v12 - Nevada - Versión InglesDocument1 pageCalendario - 2020 2021 - Master - Habil - v12 - Nevada - Versión InglesAntonio FernandezNo ratings yet
- CurveDocument2 pagesCurveAntonio FernandezNo ratings yet
- Non LinearDocument1 pageNon LinearAntonio FernandezNo ratings yet
- Open Source Software Framework For Applications inDocument12 pagesOpen Source Software Framework For Applications inAntonio FernandezNo ratings yet
- 01-BASICS-v2017 2 3Document100 pages01-BASICS-v2017 2 3Antonio FernandezNo ratings yet
- On Detection of Outliers and Their Effect in SuperDocument15 pagesOn Detection of Outliers and Their Effect in SuperAntonio FernandezNo ratings yet
- Calendario - 2021 2022 - Master - Habil - Versión Ingles - v3Document1 pageCalendario - 2021 2022 - Master - Habil - Versión Ingles - v3Antonio FernandezNo ratings yet
- Ad Phdstudent1Document2 pagesAd Phdstudent1Antonio FernandezNo ratings yet
- Sensors: EEMD and Multiscale PCA-Based Signal Denoising Method and Its Application To Seismic P-Phase Arrival PickingDocument15 pagesSensors: EEMD and Multiscale PCA-Based Signal Denoising Method and Its Application To Seismic P-Phase Arrival PickingAntonio FernandezNo ratings yet
- T & T 1374 - OptiStruct - Mode Tracking and Rotor Energy From Complex Eigen Value AnalysisDocument2 pagesT & T 1374 - OptiStruct - Mode Tracking and Rotor Energy From Complex Eigen Value AnalysisAntonio FernandezNo ratings yet
- TempDocument36 pagesTempAntonio FernandezNo ratings yet
- Predicting Real Exoplanets Using Machine Learning Techniques (Evaluator-OMID-BAGHCHEH-SARAEI)Document44 pagesPredicting Real Exoplanets Using Machine Learning Techniques (Evaluator-OMID-BAGHCHEH-SARAEI)Antonio FernandezNo ratings yet
- Acbuilder: User Manual ForDocument9 pagesAcbuilder: User Manual ForAntonio FernandezNo ratings yet
- Campbell DiagramDocument8 pagesCampbell DiagramAntonio FernandezNo ratings yet
- Adf Aap - 7001 054Document510 pagesAdf Aap - 7001 054Antonio FernandezNo ratings yet
- What Does A Software Engineer DoDocument6 pagesWhat Does A Software Engineer DoAlhasan A. RayyanNo ratings yet
- Easy 1Document6 pagesEasy 1Budi SantoNo ratings yet
- DSADocument1 pageDSAhanifsipai2006100% (3)
- Modeling: Authorization in SAP NW BIDocument6 pagesModeling: Authorization in SAP NW BIKarthik EgNo ratings yet
- 04 - Fme01 Jet ImpactDocument2 pages04 - Fme01 Jet Impactwaleed.murad@gmail.comNo ratings yet
- Mototrbo™: DEP 450 Portable RadioDocument12 pagesMototrbo™: DEP 450 Portable RadioPablo ToscanoNo ratings yet
- 2023 Assignment 3 (Group Assignment) - 1Document4 pages2023 Assignment 3 (Group Assignment) - 1MoonNo ratings yet
- PythonDocument8 pagesPythondesaikrish713No ratings yet
- 181309-180503-Process Simulation and OptimizationDocument2 pages181309-180503-Process Simulation and OptimizationAniruddh ModiNo ratings yet
- Metasploit Guide InstallDocument6 pagesMetasploit Guide InstallImnot AndyNo ratings yet
- That:Dbx2002 VcaDocument4 pagesThat:Dbx2002 VcashirtquittersNo ratings yet
- Florida Civics End-Of-course Assessment Test Preparation Workbook AnswersDocument5 pagesFlorida Civics End-Of-course Assessment Test Preparation Workbook Answersf675ztsf50% (2)
- Ladder Logic BasicsDocument13 pagesLadder Logic BasicsBILLYNo ratings yet
- FRPDocument463 pagesFRParunavarayNo ratings yet
- Logopress3 News 2016 SP0-xDocument21 pagesLogopress3 News 2016 SP0-xLndIngenieriaNo ratings yet
- Pan Calibration in The Field - Revised FINALDocument10 pagesPan Calibration in The Field - Revised FINALkirk urreaNo ratings yet
- MP3 Trigger Onboard Chip DatasheetDocument82 pagesMP3 Trigger Onboard Chip DatasheetQuinn BastNo ratings yet
- Databse Systems (Lab Manual) COT-313 and IT-216Document12 pagesDatabse Systems (Lab Manual) COT-313 and IT-216minakshiNo ratings yet
- Software Processes: The Software Process ModelDocument16 pagesSoftware Processes: The Software Process Modelmadhurajeewantha7074No ratings yet
- List of Screw DrivesDocument17 pagesList of Screw DrivesShanaka AluthwewaNo ratings yet
- Module 3 Sts Pre FinalDocument14 pagesModule 3 Sts Pre FinalJonnel BalizaNo ratings yet
- CE144 OOPC Unit-03Document74 pagesCE144 OOPC Unit-03Priyanshu PurohitNo ratings yet
- 74490Document5 pages74490Kayo MoscardiniNo ratings yet
- ParaFlare UNSW Detection and Response 2023Document46 pagesParaFlare UNSW Detection and Response 2023Darren NguyenNo ratings yet
- Word 2007Document272 pagesWord 2007Akshay PatelNo ratings yet
- Perkembangan Arsitektur KomputerDocument39 pagesPerkembangan Arsitektur KomputerJaluprasetyoNo ratings yet
- Simcoder & Ti-F28335 Hardware Target Modules: For Automatic Code GenerationDocument1 pageSimcoder & Ti-F28335 Hardware Target Modules: For Automatic Code GenerationSebastian RamirezNo ratings yet
- Assignment1 Class X, 2022 23Document4 pagesAssignment1 Class X, 2022 23RAZE GAMER ZINDABADNo ratings yet
- RFID Based Attendance System With Storing Data On Google SpreadsheetDocument39 pagesRFID Based Attendance System With Storing Data On Google SpreadsheetKing YadavNo ratings yet
- Monte Carlo Tree SearchDocument9 pagesMonte Carlo Tree Searchjoseph676No ratings yet
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (3)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeFrom EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeRating: 4.5 out of 5 stars4.5/5 (69)
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- T-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerFrom EverandT-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerRating: 4 out of 5 stars4/5 (4)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- Four Battlegrounds: Power in the Age of Artificial IntelligenceFrom EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceRating: 5 out of 5 stars5/5 (5)
- Working with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)From EverandWorking with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Rating: 5 out of 5 stars5/5 (5)
- Artificial Intelligence & Generative AI for Beginners: The Complete GuideFrom EverandArtificial Intelligence & Generative AI for Beginners: The Complete GuideRating: 5 out of 5 stars5/5 (1)
- System Design Interview: 300 Questions And Answers: Prepare And PassFrom EverandSystem Design Interview: 300 Questions And Answers: Prepare And PassNo ratings yet
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziFrom Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNo ratings yet
- The Digital Mind: How Science is Redefining HumanityFrom EverandThe Digital Mind: How Science is Redefining HumanityRating: 4.5 out of 5 stars4.5/5 (2)
- Rise of Generative AI and ChatGPT: Understand how Generative AI and ChatGPT are transforming and reshaping the business world (English Edition)From EverandRise of Generative AI and ChatGPT: Understand how Generative AI and ChatGPT are transforming and reshaping the business world (English Edition)No ratings yet
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- Hands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesFrom EverandHands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesNo ratings yet
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- How to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.From EverandHow to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.No ratings yet
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryFrom EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryNo ratings yet
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsFrom EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsNo ratings yet
- Our Final Invention: Artificial Intelligence and the End of the Human EraFrom EverandOur Final Invention: Artificial Intelligence and the End of the Human EraRating: 4 out of 5 stars4/5 (82)
- ChatGPT 4 $10,000 per Month #1 Beginners Guide to Make Money Online Generated by Artificial IntelligenceFrom EverandChatGPT 4 $10,000 per Month #1 Beginners Guide to Make Money Online Generated by Artificial IntelligenceNo ratings yet
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsFrom EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNo ratings yet