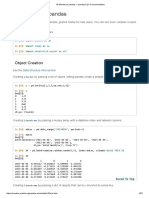
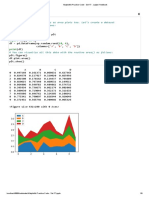
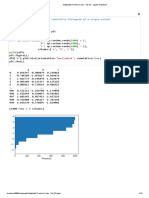
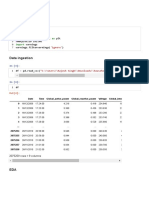
You might also like
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- 10 Minutes To Pandas - Pandas 0.21Document23 pages10 Minutes To Pandas - Pandas 0.21Aditya SinghNo ratings yet
- PandasDocument16 pagesPandaslalkrishna123No ratings yet
- PCA Code-CheckpointDocument4 pagesPCA Code-CheckpointАурел ПNo ratings yet
- Import As Import As Import AsDocument8 pagesImport As Import As Import AsDavid EsparzaArellanoNo ratings yet
- Assignment1 VidulGargDocument2 pagesAssignment1 VidulGargvidulgarg1524No ratings yet
- PandasDocument21 pagesPandasShubham dattatray koteNo ratings yet
- Name: Muhammad Sarfraz Seat: EP1850086 Section: A Course Code: 514 Course Name: Data Warehousing and Data MiningDocument39 pagesName: Muhammad Sarfraz Seat: EP1850086 Section: A Course Code: 514 Course Name: Data Warehousing and Data MiningMuhammad SarfrazNo ratings yet
- Marvel Vs DCDocument1 pageMarvel Vs DCManoj MNo ratings yet
- Tree Example - Hitters - Jupyter NotebookDocument10 pagesTree Example - Hitters - Jupyter Notebookeleni giannopoulouNo ratings yet
- 10 Minutes To PANDASDocument26 pages10 Minutes To PANDASruchirmandoraNo ratings yet
- Matplotlib 1652960400Document13 pagesMatplotlib 1652960400Washington AzevedoNo ratings yet
- AP19110010030 Assiggnmnet-3Document5 pagesAP19110010030 Assiggnmnet-3Sravan Kilaru AP19110010030No ratings yet
- 10 Minutes To PandasDocument26 pages10 Minutes To Pandastofy79No ratings yet
- 0501 Indexing and Selecting DataDocument16 pages0501 Indexing and Selecting DataKumara SNo ratings yet
- Decision Tree Regressor and Ensemble Techniques - RegressorsDocument18 pagesDecision Tree Regressor and Ensemble Techniques - RegressorsS ANo ratings yet
- 6 XG Boost - Jupyter NotebookDocument3 pages6 XG Boost - Jupyter Notebookvenkatesh m100% (1)
- Know Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730Document1 pageKnow Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730SHANTI ROKKANo ratings yet
- California 1673295505Document18 pagesCalifornia 1673295505doudoudzNo ratings yet
- Clustering Documentation R CodeDocument9 pagesClustering Documentation R Codenehal gundrapally100% (1)
- Some Important Function of Pandas LibraryDocument24 pagesSome Important Function of Pandas LibraryRania DirarNo ratings yet
- Ash RegressionDocument11 pagesAsh Regressionsarpateashish5No ratings yet
- MatplotlibDocument8 pagesMatplotlibMahevish FatimaNo ratings yet
- 2 and 3Document6 pages2 and 3Radhika KhandelwalNo ratings yet
- Fmsa315 - s11 - A.ipynb - Fernández - ConstanzaDocument6 pagesFmsa315 - s11 - A.ipynb - Fernández - ConstanzaScribdTranslationsNo ratings yet
- DS - Assig-03-Part-I - Jupyter NotebookDocument8 pagesDS - Assig-03-Part-I - Jupyter NotebookYash ShindeNo ratings yet
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- From Import: Image Image (Filename, Height, Width)Document10 pagesFrom Import: Image Image (Filename, Height, Width)Trishala KumariNo ratings yet
- ? Pandas ?Document116 pages? Pandas ?Anuj KaushikNo ratings yet
- Assignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Document7 pagesAssignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Manikanta Sai100% (1)
- Assignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Document7 pagesAssignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Manikanta Sai100% (1)
- Stock Prediction Web App - Jupyter NotebookDocument12 pagesStock Prediction Web App - Jupyter Notebookashutosh312004No ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- 10 Minutes To PandasDocument19 pages10 Minutes To PandasPraveen KandhalaNo ratings yet
- Chapter 5Document22 pagesChapter 5Rajat BansalNo ratings yet
- Amazon Stocks PriceDocument16 pagesAmazon Stocks PriceDineshkumar VhananavarNo ratings yet
- ModelDocument164 pagesModelSanjayNo ratings yet
- Simple Linear RegressionDocument4 pagesSimple Linear Regressionjaymehta1444No ratings yet
- TP RegressionDocument1 pageTP RegressionMOHAMED EL BACHIR BERRIOUA100% (1)
- Goal - Perform Eda Over A Dataset 'Samplesuperstore' Goal - Perform Eda Over A Dataset 'Samplesuperstore'Document9 pagesGoal - Perform Eda Over A Dataset 'Samplesuperstore' Goal - Perform Eda Over A Dataset 'Samplesuperstore'nishantNo ratings yet
- MScFE 300 Group Work Project 2 Python CodesDocument2 pagesMScFE 300 Group Work Project 2 Python CodesBryanNo ratings yet
- Numpy - Pandas - Lab - Jupyter NotebookDocument29 pagesNumpy - Pandas - Lab - Jupyter NotebookRavi goelNo ratings yet
- Setup: Chapter 2 - End-To-End Machine Learning ProjectDocument31 pagesSetup: Chapter 2 - End-To-End Machine Learning ProjectAmitNo ratings yet
- Exp 4 (Movie Review)Document7 pagesExp 4 (Movie Review)pameluftNo ratings yet
- DeltapdfDocument3 pagesDeltapdfVIJAY YADAVNo ratings yet
- Metnum - Uts - Mochamad Shobirin 073PDocument20 pagesMetnum - Uts - Mochamad Shobirin 073PKiro KiroNo ratings yet
- Pa66 ML Exp6Document9 pagesPa66 ML Exp6Pratik ManeNo ratings yet
- Lecture Material 8Document9 pagesLecture Material 8Ali NaseerNo ratings yet
- Heart: Our "Goal" Predict The Presence of Heart Disease in The PatientDocument73 pagesHeart: Our "Goal" Predict The Presence of Heart Disease in The Patientaditya b100% (1)
- Logistic Regression 205Document8 pagesLogistic Regression 205Ranadeep DeyNo ratings yet
- EastWestAirlines ClusterDocument6 pagesEastWestAirlines ClusterNiranjana MenonNo ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Tutorial Pandas Bag-5Document11 pagesTutorial Pandas Bag-5NUR JAYANo ratings yet
- Day42 SVM RegressionDocument3 pagesDay42 SVM RegressionIgor FernandesNo ratings yet
- Python Pandas Tutorial: Dataframe, Date Range, Slice What Is Pandas?Document7 pagesPython Pandas Tutorial: Dataframe, Date Range, Slice What Is Pandas?Anish kr SinghNo ratings yet
- 1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyDocument50 pages1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyP Venkata Krishna Rao100% (19)
- Data Munging - Ipynb - Colaboratory - Yodhi Adhi SanjayaDocument4 pagesData Munging - Ipynb - Colaboratory - Yodhi Adhi SanjayaadhiNo ratings yet
- ML Project - Jupyter NotebookDocument5 pagesML Project - Jupyter NotebookJAISURYA S B.Sc.AIDANo ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- AP19110010030 R Lab-Assignment-7Document7 pagesAP19110010030 R Lab-Assignment-7Sravan Kilaru AP19110010030No ratings yet
- AP19110010030 R Lab-Assignment-6Document6 pagesAP19110010030 R Lab-Assignment-6Sravan Kilaru AP19110010030No ratings yet
- AP19110010030 R Lab-Assignment-3Document7 pagesAP19110010030 R Lab-Assignment-3Sravan Kilaru AP19110010030No ratings yet
- AP19110010030 R Lab-Assignment-8Document6 pagesAP19110010030 R Lab-Assignment-8Sravan Kilaru AP19110010030No ratings yet
- AP19110010030 R Lab-Assignment-5Document5 pagesAP19110010030 R Lab-Assignment-5Sravan Kilaru AP19110010030No ratings yet
- AP19110010030 R Lab-Assignment-4Document7 pagesAP19110010030 R Lab-Assignment-4Sravan Kilaru AP19110010030No ratings yet
- AP19110010030 R Lab-Assignment-2Document8 pagesAP19110010030 R Lab-Assignment-2Sravan Kilaru AP19110010030No ratings yet
- AP19110010030 R Lab-Assignment-1Document12 pagesAP19110010030 R Lab-Assignment-1Sravan Kilaru AP19110010030No ratings yet
- AP19110010030 Assiggnmnet-3Document5 pagesAP19110010030 Assiggnmnet-3Sravan Kilaru AP19110010030No ratings yet
- AP19110010030 Assignmnet-1 LabDocument24 pagesAP19110010030 Assignmnet-1 LabSravan Kilaru AP19110010030No ratings yet
- AP19110010030 Assignment-5 LabDocument11 pagesAP19110010030 Assignment-5 LabSravan Kilaru AP19110010030No ratings yet
- AP19110010030 Assignment-2 LabDocument7 pagesAP19110010030 Assignment-2 LabSravan Kilaru AP19110010030No ratings yet
- Zaman Multivariable Calculus With ProofsDocument23 pagesZaman Multivariable Calculus With Proofsmazenhaydar271No ratings yet
- Optimal Control Homework 5Document2 pagesOptimal Control Homework 5jo TenNo ratings yet
- Attractor: 1 MotivationDocument8 pagesAttractor: 1 MotivationChampumaharajNo ratings yet
- Solution For Kriging CalculationDocument6 pagesSolution For Kriging CalculationAzka Roby Antari100% (2)
- Method of Steepest Descent and Its Applications: Department of Engineering, University of Tennessee, Knoxville, TN 37996Document3 pagesMethod of Steepest Descent and Its Applications: Department of Engineering, University of Tennessee, Knoxville, TN 37996seenagregoryNo ratings yet
- 10 Mathematics Ncert ch05 Arithmetic Progressions Ex 5.2 PDFDocument20 pages10 Mathematics Ncert ch05 Arithmetic Progressions Ex 5.2 PDFĂĺëx KìñģNo ratings yet
- Random Vectors 1Document8 pagesRandom Vectors 1bNo ratings yet
- (Mai 2.3-2.4) FunctionsDocument20 pages(Mai 2.3-2.4) FunctionsafakfNo ratings yet
- G12 Basic-Calculus Q3 W1 PDFDocument9 pagesG12 Basic-Calculus Q3 W1 PDFmarvin siegaNo ratings yet
- Metin Arik, Gökhan Ünel Auth., Bruno Gruber, Michael Ramek Eds. Symmetries in Science IXDocument351 pagesMetin Arik, Gökhan Ünel Auth., Bruno Gruber, Michael Ramek Eds. Symmetries in Science IXdeblazeNo ratings yet
- ALGEBRA I - Course Syllabus: Instructor Martin Keller Phone School E-Mail Course DescriptionDocument4 pagesALGEBRA I - Course Syllabus: Instructor Martin Keller Phone School E-Mail Course DescriptionMAHAK RAJVANSHINo ratings yet
- The Stepping Stone Method Is An Optimization Technique Used To Find The Optimal Solution To A Transportation ProblemDocument7 pagesThe Stepping Stone Method Is An Optimization Technique Used To Find The Optimal Solution To A Transportation ProblemRoyette Dela CruzNo ratings yet
- Mathematicaleconomics PDFDocument84 pagesMathematicaleconomics PDFSayyid JifriNo ratings yet
- By Assist. Prof. Dr. Karim H. Ali 2019-2020 21 May 2020Document17 pagesBy Assist. Prof. Dr. Karim H. Ali 2019-2020 21 May 2020Ali MadridNo ratings yet
- Math 8-Q1-L1-Factoring by The Greatest Common FactorDocument22 pagesMath 8-Q1-L1-Factoring by The Greatest Common FactorPearl De CastroNo ratings yet
- Soal HolonomicDocument34 pagesSoal HolonomicpestaNo ratings yet
- Ila 0306Document11 pagesIla 0306Hong ChenNo ratings yet
- Unit Assesment MapDocument3 pagesUnit Assesment MapYuri IssangNo ratings yet
- Torsional Vibration RotorDocument59 pagesTorsional Vibration Rotordaongocha108100% (1)
- Column Design LRFDDocument3 pagesColumn Design LRFDPhuc Ha Vinh Phuc100% (1)
- Lesson Plan Matrix - 12th Grade ScienceDocument5 pagesLesson Plan Matrix - 12th Grade ScienceAhmad ApriyantoNo ratings yet
- 3D TransformationDocument11 pages3D TransformationVeer SinghNo ratings yet
- Probability DistributionsDocument17 pagesProbability DistributionsAnad DanaNo ratings yet
- Preliminary Draft Subject To Revision: Advanced Microeconomics I: Syllabus GECO 6200Document23 pagesPreliminary Draft Subject To Revision: Advanced Microeconomics I: Syllabus GECO 6200popov357No ratings yet
- Add Maths 2004 Suggested SolutionDocument10 pagesAdd Maths 2004 Suggested Solutionapi-26423290No ratings yet
- 미분적분학1 기말고사 기출문제Document21 pages미분적분학1 기말고사 기출문제원준식No ratings yet
- Height of A Parabolic FlightDocument7 pagesHeight of A Parabolic Flightapi-309812031No ratings yet
- Study Guide in Greatest Common FactorDocument19 pagesStudy Guide in Greatest Common FactorkennedyNo ratings yet
- AugustinDocument12 pagesAugustinMohd HilmiNo ratings yet
- Continuum MechanicsDocument120 pagesContinuum Mechanicsxsaraneel2474No ratings yet