You might also like
- STAT1008 Cheat SheetDocument1 pageSTAT1008 Cheat SheetynottripNo ratings yet
- 2022 CFA Level II - Schweser's Quicksheet (Kaplan) (Z-Library)Document6 pages2022 CFA Level II - Schweser's Quicksheet (Kaplan) (Z-Library)muntasirbillah1992No ratings yet
- Lec 3 - Linear RegressionDocument9 pagesLec 3 - Linear Regression14 Asif AkhtarNo ratings yet
- Cheatsheet - MidtermDocument3 pagesCheatsheet - MidtermRiyaNo ratings yet
- Bach Optim 2020 Chap1Document8 pagesBach Optim 2020 Chap1AbiyNo ratings yet
- Class Note 4Document10 pagesClass Note 4Pooja ChughNo ratings yet
- Conservative HD: Wax DLDocument5 pagesConservative HD: Wax DLArctic TurtleNo ratings yet
- Class Note 2Document20 pagesClass Note 2Pooja ChughNo ratings yet
- Motivation and Contribution Stabilizer Codes and Logical Pauli OperatorsDocument1 pageMotivation and Contribution Stabilizer Codes and Logical Pauli OperatorsNarayanan RengaswamyNo ratings yet
- Cost Functions: Machine Learning Course - CS-433Document8 pagesCost Functions: Machine Learning Course - CS-433Diego Iriarte SainzNo ratings yet
- Mathematical Tools For Physics: Class-6Document19 pagesMathematical Tools For Physics: Class-6RAKSHIT GOYALNo ratings yet
- Simon Chapter 3Document12 pagesSimon Chapter 3shreyas srNo ratings yet
- IMAposterDocument1 pageIMApostersomefodemNo ratings yet
- Class 2 NotesDocument24 pagesClass 2 NotesSoniaNo ratings yet
- Econometrics Lecture NotesDocument16 pagesEconometrics Lecture NotesfarmerNo ratings yet
- Diff Eq SummaryDocument5 pagesDiff Eq SummaryLuca MorenoNo ratings yet
- Formula Book SDSIDocument6 pagesFormula Book SDSInotajinkya04No ratings yet
- Lecture02a Optimization Annotated PDFDocument23 pagesLecture02a Optimization Annotated PDFNing YangNo ratings yet
- Wave OpticsDocument10 pagesWave Opticstheamaanahmad786No ratings yet
- Extra Practice MaterialsDocument12 pagesExtra Practice MaterialsWendyNo ratings yet
- 05 ShellDocument13 pages05 ShellHicham Al FalouNo ratings yet
- Vector Spaces Lecture NotesDocument48 pagesVector Spaces Lecture NoteswannafadedNo ratings yet
- 20Document12 pages20Rajat Verma X D 39No ratings yet
- Do Chi Kien-20200299Document3 pagesDo Chi Kien-20200299dckien2002No ratings yet
- ملخص - (1-2-4) ChaptersDocument5 pagesملخص - (1-2-4) Chapterssmbarky729No ratings yet
- 02 09 22Document5 pages02 09 22Mahima AroraNo ratings yet
- HW1 AnswerDocument4 pagesHW1 Answeraaaa102234No ratings yet
- 4160 Lecture 28Document7 pages4160 Lecture 28jjwfishNo ratings yet
- Gradient: InterpretationDocument10 pagesGradient: InterpretationHeaven in Home StudentNo ratings yet
- Binomial Theorem (Class-1)Document10 pagesBinomial Theorem (Class-1)Idhant SinghNo ratings yet
- Script Lecture 5Document19 pagesScript Lecture 5jsebas635No ratings yet
- Slides LearnersDocument49 pagesSlides LearnersHoàng Lê VănNo ratings yet
- CHPT 7 SolDocument39 pagesCHPT 7 Solsyed MahdiNo ratings yet
- Microstrip Discontinuity Capacitances For Right-An81e Bends, T Junctions, and CrossingsDocument6 pagesMicrostrip Discontinuity Capacitances For Right-An81e Bends, T Junctions, and CrossingsElectronic BoyNo ratings yet
- Variatinal Quantum Algorithms Lesson 4Document17 pagesVariatinal Quantum Algorithms Lesson 4Ernesto CamposNo ratings yet
- B. IntegrationDocument28 pagesB. Integrationarmoniramdhanie36No ratings yet
- Intro To RegressionDocument30 pagesIntro To RegressionShewakena GirmaNo ratings yet
- Mechanics Waves and Oscillations MidsemesterDocument24 pagesMechanics Waves and Oscillations MidsemesterAshman MehraNo ratings yet
- Advancing: DelayDocument5 pagesAdvancing: DelaySimanta SahooNo ratings yet
- Nthfs Couillet MatricesDocument95 pagesNthfs Couillet MatricesBo LuNo ratings yet
- Deflection of Beams Double Integration MethodDocument4 pagesDeflection of Beams Double Integration MethodJoeron Caezar Del Rosario (Joe)No ratings yet
- Lementarysi-Gna-S-Ontd - Es: SignalDocument4 pagesLementarysi-Gna-S-Ontd - Es: SignalSimanta SahooNo ratings yet
- 1 IntroDocument25 pages1 Introwiyemo6275No ratings yet
- Quantum Mechanics Notes - Ii: Amit Kumar Jha (Iitian)Document15 pagesQuantum Mechanics Notes - Ii: Amit Kumar Jha (Iitian)Tiasha DevNo ratings yet
- Lecture 00Document10 pagesLecture 00Samy YNo ratings yet
- Perturbation and Projection Methods For Solving DSGE Models: Lawrence J. ChristianoDocument69 pagesPerturbation and Projection Methods For Solving DSGE Models: Lawrence J. ChristianoJovannyNo ratings yet
- Perturbation and Projection Methods For Solving DSGE Models: Lawrence J. ChristianoDocument93 pagesPerturbation and Projection Methods For Solving DSGE Models: Lawrence J. ChristianoJovannyNo ratings yet
- Linear Algebra-37 PDFDocument15 pagesLinear Algebra-37 PDFremo remoNo ratings yet
- Math 223 - Lecture 24Document5 pagesMath 223 - Lecture 24rachelh0205No ratings yet
- Formula in StatsDocument2 pagesFormula in StatsHanchey ElipseNo ratings yet
- W7 L1 CompleteDocument19 pagesW7 L1 CompleteNiroshan KarunarathnaNo ratings yet
- Particle Filter NotesDocument26 pagesParticle Filter NotesPrathyusha MNo ratings yet
- Fie Un Npgtiuvutoml Real.Document14 pagesFie Un Npgtiuvutoml Real.ioanaNo ratings yet
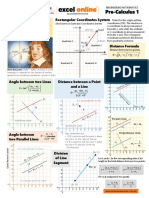
- Notes Pre Calculus 1Document1 pageNotes Pre Calculus 1Sydrey Jada-ongNo ratings yet
- Methods Lecture 2Document1 pageMethods Lecture 2KingsleyNo ratings yet
- Caie A2 Biology 9700 Practical v1Document10 pagesCaie A2 Biology 9700 Practical v1ARMANI ROYNo ratings yet
- d9ac94f3EndSem 2019Document2 pagesd9ac94f3EndSem 2019Aayush Kumar SinghNo ratings yet
- Fermat Last Theorem PDFDocument69 pagesFermat Last Theorem PDFRobertNo ratings yet
- Lec 12 - ANNDocument18 pagesLec 12 - ANN14 Asif AkhtarNo ratings yet
- Fractal Formation and Trend Trading Strategy in Futures MarketDocument5 pagesFractal Formation and Trend Trading Strategy in Futures Market14 Asif AkhtarNo ratings yet
- Lec 1 - Maths in ML IDocument38 pagesLec 1 - Maths in ML I14 Asif AkhtarNo ratings yet
- CSV File HandlingDocument5 pagesCSV File Handling14 Asif AkhtarNo ratings yet
- Lec 2 - Maths in ML IIDocument28 pagesLec 2 - Maths in ML II14 Asif AkhtarNo ratings yet
- PYQ ChoppersDocument20 pagesPYQ Choppers14 Asif AkhtarNo ratings yet
- PYQ InvertersDocument18 pagesPYQ Inverters14 Asif AkhtarNo ratings yet
- PYQ Phase Controlled RectifiersDocument32 pagesPYQ Phase Controlled Rectifiers14 Asif AkhtarNo ratings yet
- Change The World. Love Your Job.: About Texas Instruments India Groups Within TIDocument2 pagesChange The World. Love Your Job.: About Texas Instruments India Groups Within TI14 Asif AkhtarNo ratings yet
- 5th EE-BDocument1 page5th EE-B14 Asif AkhtarNo ratings yet
- S.No Faculty Short NameDocument3 pagesS.No Faculty Short Name14 Asif AkhtarNo ratings yet
- CSE Dept Mooc Order 22-23 Odd SemDocument1 pageCSE Dept Mooc Order 22-23 Odd Sem14 Asif AkhtarNo ratings yet
- 5th EE-ADocument1 page5th EE-A14 Asif AkhtarNo ratings yet
- (@dtualertbot) E22 Btech IV 1445 (Sem-4 Result)Document423 pages(@dtualertbot) E22 Btech IV 1445 (Sem-4 Result)14 Asif AkhtarNo ratings yet
- ITEE FE (Level 2) Syllabus Version 4 PDFDocument140 pagesITEE FE (Level 2) Syllabus Version 4 PDFOpenTsubasaNo ratings yet
- Sutherland Interview Question and AnswerDocument11 pagesSutherland Interview Question and AnswerSaumya KumariNo ratings yet
- Acvuracy Precision Error Unit-1Document29 pagesAcvuracy Precision Error Unit-1manjot kaurNo ratings yet
- Lecture 6 Simple Linear RegressionDocument36 pagesLecture 6 Simple Linear RegressionAshley Sophia GarciaNo ratings yet
- Analytical Chemistry (Chem. 2021) : Statistical Evaluation of Analytical DataDocument46 pagesAnalytical Chemistry (Chem. 2021) : Statistical Evaluation of Analytical DataMathewos AberaNo ratings yet
- Ms08 Sem-II, 2010 SaviDocument10 pagesMs08 Sem-II, 2010 SaviAnand SelvarajNo ratings yet
- Investigation of The Relationships Between Phubbing, Attachment Styles and Social Anxiety Variables in AdultsDocument13 pagesInvestigation of The Relationships Between Phubbing, Attachment Styles and Social Anxiety Variables in AdultsAJHSSR JournalNo ratings yet
- Linear Regression Bus Solution Part 1Document4 pagesLinear Regression Bus Solution Part 1sourav abhishekNo ratings yet
- API Reference - Scikit-Learn 0.19.2 DocumentationDocument21 pagesAPI Reference - Scikit-Learn 0.19.2 Documentation08mpe026No ratings yet
- Interpreting CorrelationDocument13 pagesInterpreting CorrelationAnonymous AQ9cNmNo ratings yet
- Nota Topik 1Document25 pagesNota Topik 1nursyafira8927No ratings yet
- Solution Manual For Corporate Finance Linking Theory To What Companies Do 3rd Edition by GrahamDocument16 pagesSolution Manual For Corporate Finance Linking Theory To What Companies Do 3rd Edition by GrahamLarryHickseqfsc100% (82)
- Foundation of Machine Learning F-PMLFML02-WSDocument352 pagesFoundation of Machine Learning F-PMLFML02-WSAINDRILA GHOSHNo ratings yet
- Aqueous Extraction of Oil and Protein From Soybeans With Subcritical WaterDocument10 pagesAqueous Extraction of Oil and Protein From Soybeans With Subcritical WaterelokwaziirohNo ratings yet
- GlmselectDocument104 pagesGlmselectjapelsf5830No ratings yet
- An Intelligent Approach To Demand ForecastingDocument8 pagesAn Intelligent Approach To Demand ForecastingUzair Ullah KhanNo ratings yet
- Econometrics LecturesDocument240 pagesEconometrics LecturesDevin-KonulRichmondNo ratings yet
- Advanced Regression in Excel SDocument53 pagesAdvanced Regression in Excel SIvanNo ratings yet
- Quality Control and Assurance (QAQC)Document25 pagesQuality Control and Assurance (QAQC)JuanMa TurraNo ratings yet
- Anulom VilomDocument5 pagesAnulom VilomAkhilesh KumarNo ratings yet
- ANOVA Tables F-Tests: BMTRY 701 Biostatistical Methods IIDocument29 pagesANOVA Tables F-Tests: BMTRY 701 Biostatistical Methods IIAlan J CedenoNo ratings yet
- TimeseriesDocument98 pagesTimeseriesAnup M UpadhyayaNo ratings yet
- World Class Quality To Achieve Zero PPM 231111Document108 pagesWorld Class Quality To Achieve Zero PPM 231111Gyanesh_DBNo ratings yet
- Data TransfermationDocument16 pagesData TransfermationBhuvanaNo ratings yet
- Major ProjectDocument17 pagesMajor ProjectRISHABH GIRINo ratings yet
- Chapter 2Document50 pagesChapter 2Shalin IlyaniNo ratings yet
- Linear RegressionDocument5 pagesLinear RegressionlxsiiNo ratings yet
- Autocorrelation STATA ResultsDocument18 pagesAutocorrelation STATA Resultscosgapacyril21No ratings yet
- Prediks I MovieDocument25 pagesPrediks I MovieNurul Eka LestariNo ratings yet
- Service Quality From Customer Perception: Comparative Analysis Between Islamic and Conventional BankDocument14 pagesService Quality From Customer Perception: Comparative Analysis Between Islamic and Conventional BankMegy AwanNo ratings yet