You might also like
- Convolutional Neural NetworksDocument46 pagesConvolutional Neural NetworksLamis Ahmad100% (1)
- Pattern Classification 08. Gaussian Mixture Model: Abdelmoniem Bayoumi, PHDDocument12 pagesPattern Classification 08. Gaussian Mixture Model: Abdelmoniem Bayoumi, PHDMostafa MohamedNo ratings yet
- Rumus MPC Uts Gasal 2017/2018 Angkatan 58: Standar ErrorDocument2 pagesRumus MPC Uts Gasal 2017/2018 Angkatan 58: Standar ErrorAhmad Nur HadieNo ratings yet
- Lecture 04 - Supervised Learning by Computing Distances (2) - PlainDocument16 pagesLecture 04 - Supervised Learning by Computing Distances (2) - PlainRajaNo ratings yet
- CEE 5403 Lecture 6Document18 pagesCEE 5403 Lecture 6EmmanuelNo ratings yet
- SDET Formulae MidSem2 2018 Ver3Document2 pagesSDET Formulae MidSem2 2018 Ver3Ritvick GuptaNo ratings yet
- Gradient Descent: Disclaimer: This PPT Is Modified Based On Hung-Yi LeeDocument38 pagesGradient Descent: Disclaimer: This PPT Is Modified Based On Hung-Yi Leeaniketshrimal986749No ratings yet
- Regularization and Feature Selectio NDocument102 pagesRegularization and Feature Selectio NEhab EmamNo ratings yet
- Optimization SchemesDocument15 pagesOptimization SchemesNegin OroujiNo ratings yet
- Optics Formula Sheet Study Sheet PhysicsA 2010Document1 pageOptics Formula Sheet Study Sheet PhysicsA 2010Mark Riley100% (1)
- Optimization ProblemDocument21 pagesOptimization ProblemLyes BrNo ratings yet
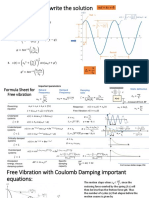
- Formula Sheet For Free VibrationDocument5 pagesFormula Sheet For Free VibrationCesar MolinaNo ratings yet
- A 4 TH Order 7-Dimensional Polynomial WHDocument11 pagesA 4 TH Order 7-Dimensional Polynomial WHAkshaya Kumar RathNo ratings yet
- Rumus Uts Mps Semester 3Document2 pagesRumus Uts Mps Semester 3Mala NingsihNo ratings yet
- Steady State Plug Flow Reactor: Hernandez PineDocument17 pagesSteady State Plug Flow Reactor: Hernandez PineJez Jaycris HernandezNo ratings yet
- Practical Research 2 Quantitative Research: Inferential Statistics Reference of Formulas Hypothesis-Testing ProcessDocument4 pagesPractical Research 2 Quantitative Research: Inferential Statistics Reference of Formulas Hypothesis-Testing Processjessa barbosaNo ratings yet
- Linear RegressionDocument34 pagesLinear RegressionRaksa KunNo ratings yet
- Neural Network: Sudipta RoyDocument25 pagesNeural Network: Sudipta RoymanNo ratings yet
- SPH3U2 Formula SheetDocument2 pagesSPH3U2 Formula SheetFrederick DingNo ratings yet
- CE687A Lecture15Document21 pagesCE687A Lecture15varunNo ratings yet
- Pattern Classification 10. Linear Perceptron, Least Squares & Multi-Layer NnsDocument38 pagesPattern Classification 10. Linear Perceptron, Least Squares & Multi-Layer NnsMostafa MohamedNo ratings yet
- EE-101 Frequency Response - 1 July-Nov 2017Document5 pagesEE-101 Frequency Response - 1 July-Nov 2017Alpha WolfNo ratings yet
- Neural Networks: 25 October, 2016Document44 pagesNeural Networks: 25 October, 2016Marius_2010100% (1)
- 1phase-Half Wave Uncontrolled Rectifier: RL - Load: R-Load With Capacitor FilterDocument1 page1phase-Half Wave Uncontrolled Rectifier: RL - Load: R-Load With Capacitor FilterAhmad Ash SharkawiNo ratings yet
- Lecture 8 BackpropagationDocument28 pagesLecture 8 BackpropagationHodatama Karanna OneNo ratings yet
- Lecture - 4 - Understanding of First & Second Order Systems-V3Document31 pagesLecture - 4 - Understanding of First & Second Order Systems-V3cesar ruizNo ratings yet
- Formulas in Business MathDocument1 pageFormulas in Business MathGeraldo MejillanoNo ratings yet
- Formulas in Business MathDocument1 pageFormulas in Business MathGeraldo MejillanoNo ratings yet
- Lesson 1 and 2 - Solving Quadratic Equations by Extracting Square Roots and FactoringDocument21 pagesLesson 1 and 2 - Solving Quadratic Equations by Extracting Square Roots and FactoringRosalyn CalapitcheNo ratings yet
- Statistics Sheet I (Descriptive Statistics)Document3 pagesStatistics Sheet I (Descriptive Statistics)Priyanka ShanbhagNo ratings yet
- FORMULASDocument4 pagesFORMULASirish cerezaNo ratings yet
- Lecture5 23Document14 pagesLecture5 23HassanNo ratings yet
- Oxford AQA A Level Physics Unit 3 Insert Jan19Document4 pagesOxford AQA A Level Physics Unit 3 Insert Jan19Pop VNo ratings yet
- Kernel Embeddings of Conditional DistributionsDocument33 pagesKernel Embeddings of Conditional DistributionsDaniel VelezNo ratings yet
- Pattern Classification 11. Backpropagation & Time-Series ForecastingDocument78 pagesPattern Classification 11. Backpropagation & Time-Series ForecastingMostafa MohamedNo ratings yet
- CQE Academy Equation Cheat Sheet - DDocument15 pagesCQE Academy Equation Cheat Sheet - DAmr AlShenawyNo ratings yet
- 11 Simple Part D Vol 2 EM PDFDocument19 pages11 Simple Part D Vol 2 EM PDFNaveen 18No ratings yet
- MIE100H1 - 20195 - 631572298320MIE 100 CheatsheetDocument2 pagesMIE100H1 - 20195 - 631572298320MIE 100 CheatsheetSCR PpelusaNo ratings yet
- All Formulae CH # 03Document2 pagesAll Formulae CH # 03abbas ZafarNo ratings yet
- Implement Neural Networks Using Keras and Pytorch: Liang LiangDocument32 pagesImplement Neural Networks Using Keras and Pytorch: Liang LiangraveritaNo ratings yet
- Mech 430 Final Formula Sheet UpdatedDocument12 pagesMech 430 Final Formula Sheet UpdatedSalman MasriNo ratings yet
- PCA (v3)Document34 pagesPCA (v3)daredevilchoNo ratings yet
- Final Formula SheetDocument4 pagesFinal Formula SheetBerkay EkenNo ratings yet
- Extension of Limit Concept-1Document30 pagesExtension of Limit Concept-1EZRA GERWHEL HERRERANo ratings yet
- 19 09 VariationalFormulationDocument12 pages19 09 VariationalFormulationatharva.betawadkarNo ratings yet
- Quant Interviews CheatsheetDocument1 pageQuant Interviews CheatsheetAnshuman GhoshNo ratings yet
- Module 11 Unit 3 Multiple Linear RegressionDocument8 pagesModule 11 Unit 3 Multiple Linear RegressionBeatriz LorezcoNo ratings yet
- Logistic-RegressionDocument3 pagesLogistic-RegressionAqua ManNo ratings yet
- Inverters: Eng. Ibrahim Mahmoud IbrahimDocument9 pagesInverters: Eng. Ibrahim Mahmoud IbrahimMahmoud A. AboulhasanNo ratings yet
- 1.1 Hard Margin SVM (Insert Diagrams)Document4 pages1.1 Hard Margin SVM (Insert Diagrams)shabaazkurmally.um1No ratings yet
- L18 - PN Homojunction - 1Document14 pagesL18 - PN Homojunction - 1Poddutoori Sankeerth ReddyNo ratings yet
- Lecture 05 Time Domain Performance PDocument47 pagesLecture 05 Time Domain Performance Pcesar ruizNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Applications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankFrom EverandApplications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankNo ratings yet
- GCSE Maths Revision: Cheeky Revision ShortcutsFrom EverandGCSE Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (2)
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningFrom EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNo ratings yet
- Part 1.2. Back PropagationDocument30 pagesPart 1.2. Back PropagationViệt HoàngNo ratings yet
- Part 1.5. Recurrent Neural NetworkDocument28 pagesPart 1.5. Recurrent Neural NetworkViệt HoàngNo ratings yet
- Part 1.1.neural Network and Training AlgorithmDocument34 pagesPart 1.1.neural Network and Training AlgorithmViệt HoàngNo ratings yet
- Part 1.4. Convolution Neural NetworkDocument24 pagesPart 1.4. Convolution Neural NetworkViệt HoàngNo ratings yet
- Test - Reading Explorer 3 8A - QuizletDocument4 pagesTest - Reading Explorer 3 8A - QuizletTatjana Modea SibulNo ratings yet
- Generative NLP Robert Dilts PDFDocument11 pagesGenerative NLP Robert Dilts PDFCristina LorinczNo ratings yet
- IHS Markit Seed Market Analysis and Data InfographicDocument1 pageIHS Markit Seed Market Analysis and Data Infographictripurari pandeyNo ratings yet
- 003 Users Manuel of Safir 2016 - MechanicalDocument74 pages003 Users Manuel of Safir 2016 - Mechanicalenrico_britaiNo ratings yet
- Multifocal AntennaDocument5 pagesMultifocal AntennaLazni NalogNo ratings yet
- CSC-160 Series Numerical Line Protection EquipmentDocument112 pagesCSC-160 Series Numerical Line Protection EquipmentMarkusKunNo ratings yet
- Practice For Group Work Week 2 Case 2.1 - Assigning Plants To Products (Better Products Company)Document2 pagesPractice For Group Work Week 2 Case 2.1 - Assigning Plants To Products (Better Products Company)Thu TrangNo ratings yet
- (IMP) Ancient Indian JurisprudenceDocument28 pages(IMP) Ancient Indian JurisprudenceSuraj AgarwalNo ratings yet
- IE54500 - Exam 1: Dr. David Johnson Fall 2020Document7 pagesIE54500 - Exam 1: Dr. David Johnson Fall 2020MNo ratings yet
- OLET1139 - Essay - July 21 - InstructionDocument3 pagesOLET1139 - Essay - July 21 - InstructionPriscaNo ratings yet
- Tentative Schedule For Mid Odd Semester Exam 2023-24Document7 pagesTentative Schedule For Mid Odd Semester Exam 2023-24gimtce GIMTCE2022No ratings yet
- Diamantina Shire BrochureDocument13 pagesDiamantina Shire BrochurefionaNo ratings yet
- Design of Deep Supported Excavations: Comparison Between Numerical and Empirical MethodsDocument7 pagesDesign of Deep Supported Excavations: Comparison Between Numerical and Empirical MethodsNajihaNo ratings yet
- Filtergehà Use - Beutel Und - Kerzen - enDocument5 pagesFiltergehà Use - Beutel Und - Kerzen - ennabila OktavianiNo ratings yet
- 5 Đề Thi Giữa Học Kì 2 Môn Tiếng Anh 10 Ilearn Smart World Năm Học 2022-2023 (Có File Nghe)Document48 pages5 Đề Thi Giữa Học Kì 2 Môn Tiếng Anh 10 Ilearn Smart World Năm Học 2022-2023 (Có File Nghe)Dạy Kèm Quy Nhơn OfficialNo ratings yet
- Gravity Distribution Systems: A System Design and ConstructionDocument40 pagesGravity Distribution Systems: A System Design and ConstructionTooma DavidNo ratings yet
- Various Executions MA: Series Foodstuffs ExecutionDocument17 pagesVarious Executions MA: Series Foodstuffs ExecutionKyriakos MichalakiNo ratings yet
- Topic 2.9 WorksheetDocument3 pagesTopic 2.9 WorksheethaniaNo ratings yet
- Week 3 Forecasting HomeworkDocument4 pagesWeek 3 Forecasting HomeworkMargot LaGrandNo ratings yet
- Unit 5Document3 pagesUnit 5api-665951284No ratings yet
- Free Downloads: Type Matters!Document3 pagesFree Downloads: Type Matters!Shinko Art Studio9% (11)
- Proton-Halo Breakup DynamicsDocument7 pagesProton-Halo Breakup DynamicsBharat KashyapNo ratings yet
- Project Work Class 11Document17 pagesProject Work Class 11DipeshNo ratings yet
- Structural-Analysis SyDocument30 pagesStructural-Analysis Symark philip denilaNo ratings yet
- DIRECTION: Read Each Question Carefully. Encircle The Letter That Corresponds To The Letter of Your AnswerDocument2 pagesDIRECTION: Read Each Question Carefully. Encircle The Letter That Corresponds To The Letter of Your AnswerMea-Ann OscianasNo ratings yet
- Spouse Visa AttorneyDocument2 pagesSpouse Visa AttorneyShaheen SadiqueNo ratings yet
- October 2016 2Document16 pagesOctober 2016 2Tanvika AroraNo ratings yet
- Iefem English Guide Reported Speech 3Document6 pagesIefem English Guide Reported Speech 3Laury Yocely Perea MenaNo ratings yet
- Hill & Jones CH 01Document29 pagesHill & Jones CH 01Ishraque MahmudNo ratings yet
- CTS Company Profile Rev0Document11 pagesCTS Company Profile Rev0khalesnabilNo ratings yet