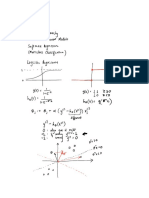
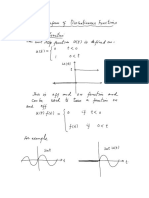
You might also like
- Delta Green Static ProtocolDocument42 pagesDelta Green Static ProtocolJesse BerenfeldNo ratings yet
- Automatic Control NotesDocument7 pagesAutomatic Control NotesFady KamilNo ratings yet
- Zohar Ringel - Mappings From DNNs To GPS - Part 1Document16 pagesZohar Ringel - Mappings From DNNs To GPS - Part 1L VNo ratings yet
- Electric Charges and Field Short NotesDocument12 pagesElectric Charges and Field Short Notesanmolsaini2905No ratings yet
- DocScanner 25-Apr-2024 7-59 AmDocument1 pageDocScanner 25-Apr-2024 7-59 Ammahalakshmi periyasamyNo ratings yet
- Rkkek EjejDocument5 pagesRkkek EjejJuan Pérez CuéllarNo ratings yet
- Trees5 Adv AprilDocument11 pagesTrees5 Adv AprilAshish SoniNo ratings yet
- 11 GravitationDocument8 pages11 GravitationSuryansh VatsaaNo ratings yet
- Lecture 1 - Ideal Chains PDFDocument8 pagesLecture 1 - Ideal Chains PDFBrandon RawsonNo ratings yet
- Unit 4 (Notes)Document19 pagesUnit 4 (Notes)Prince RajNo ratings yet
- 02 Kinematics-1DDocument3 pages02 Kinematics-1DfrosterlitegamingNo ratings yet
- Sa CND 3em Xam: Koll No. B'Ti8Eceo26Document14 pagesSa CND 3em Xam: Koll No. B'Ti8Eceo26AnujNo ratings yet
- Petnica Notes Cosmology 2019Document31 pagesPetnica Notes Cosmology 2019MatejaBoskovicNo ratings yet
- FET&OPAMP Handwritten NotesDocument15 pagesFET&OPAMP Handwritten NotesShubh BadoniaNo ratings yet
- I Ngredi Ents I Nstructi ONS: Jordan' SDocument1 pageI Ngredi Ents I Nstructi ONS: Jordan' SPeterNo ratings yet
- Bcreatveanalysis: CompanyDocument16 pagesBcreatveanalysis: CompanyRajat AgrawalNo ratings yet
- UntitledDocument4 pagesUntitledAnoushka DeyNo ratings yet
- Free Fall and Projectile - 230702 - 170925Document9 pagesFree Fall and Projectile - 230702 - 170925Mathew MohanNo ratings yet
- 04 - Newton's Laws of MotionDocument4 pages04 - Newton's Laws of Motionseemagoyal0206No ratings yet
- DBMS Unit-4 PDFDocument17 pagesDBMS Unit-4 PDFHari Ram MaadamNo ratings yet
- DBMS (Sindhu Aasign1)Document22 pagesDBMS (Sindhu Aasign1)Charan Kumar ReddyNo ratings yet
- SPCC Assignment 3-8Document10 pagesSPCC Assignment 3-8URVI BALEKUNDRINo ratings yet
- Falling: ObjectDocument4 pagesFalling: ObjectYul KwonNo ratings yet
- Samartha SFTP AssignmentDocument8 pagesSamartha SFTP Assignmentkrish rawatNo ratings yet
- CW RadarDocument4 pagesCW RadarKanduri Jaya LakshmiNo ratings yet
- Ichignation: EeguahossnfcxrgelDocument11 pagesIchignation: EeguahossnfcxrgelRAJU CNo ratings yet
- Recitation 2 Elementary Algebra II Sep 10 2020Document7 pagesRecitation 2 Elementary Algebra II Sep 10 2020Shanmuga SundaramNo ratings yet
- Newton's Laws of Motion Short NotesDocument7 pagesNewton's Laws of Motion Short NotesadilawriteNo ratings yet
- Adobe Scan Mar 11, 2023Document25 pagesAdobe Scan Mar 11, 2023EriswamyNo ratings yet
- Intermediate Python 20 Jan 2021 09.51.29Document14 pagesIntermediate Python 20 Jan 2021 09.51.29Dwika WidyantamaNo ratings yet
- cs236 Livenotes Lecture4 PDFDocument7 pagescs236 Livenotes Lecture4 PDFd anchorNo ratings yet
- Physical Education-13Document23 pagesPhysical Education-13veerpratap2022No ratings yet
- Antenna - Lecture 1Document11 pagesAntenna - Lecture 1soumyalovely01No ratings yet
- Lesson 3Document17 pagesLesson 3Danielle GuerraNo ratings yet
- Robotics Notes - MCT 511Document15 pagesRobotics Notes - MCT 511Stephen NwankwoNo ratings yet
- Note 3 Mar 2023 at 09 - 10 - 09Document10 pagesNote 3 Mar 2023 at 09 - 10 - 09arijNo ratings yet
- ProbabilityDocument4 pagesProbabilityPreethi VictorNo ratings yet
- DR K B Singh Final Lecture Notes UG I - Joule Thompson EffectsDocument6 pagesDR K B Singh Final Lecture Notes UG I - Joule Thompson EffectsDeep RanjanNo ratings yet
- Literature Study Co Working OfficeDocument1 pageLiterature Study Co Working OfficeAr.V V MATHI VENKATNo ratings yet
- Astro Tutorials 6-10Document7 pagesAstro Tutorials 6-10Sudhir SharmaNo ratings yet
- Nacario, Vanessa M. Task Sheet 8Document1 pageNacario, Vanessa M. Task Sheet 8Vanessa NacarioNo ratings yet
- Unityotunction: TransformofdiscontinsfunctionsDocument12 pagesUnityotunction: TransformofdiscontinsfunctionsMary GraceNo ratings yet
- BDA Cie-2 ImpDocument6 pagesBDA Cie-2 Impit.was.spamNo ratings yet
- Data Structure Basic NotesDocument10 pagesData Structure Basic Notesramesh2specialNo ratings yet
- Cyber InstructionsDocument3 pagesCyber InstructionsNgoc Nguyen Binh TranNo ratings yet
- BL Ues F or Dus T: ST Eve VaiDocument6 pagesBL Ues F or Dus T: ST Eve VaiSteve PembertonNo ratings yet
- Priyanka GS 1DB17TE020 17EC82 Assignment 1Document14 pagesPriyanka GS 1DB17TE020 17EC82 Assignment 1Naga SonikaNo ratings yet
- Transport Anurag Kanpur: TripathiDocument18 pagesTransport Anurag Kanpur: TripathiPankaj Kumar SainiNo ratings yet
- Note 21-Jun-2022Document26 pagesNote 21-Jun-2022Peri SubrahmanyamNo ratings yet
- Equationsofchavgeo - NO: TransportDocument12 pagesEquationsofchavgeo - NO: TransportPankaj Kumar SainiNo ratings yet
- Adobe Scan Mar 05 2023 1 PDFDocument4 pagesAdobe Scan Mar 05 2023 1 PDFJohn Rey BalansagNo ratings yet
- Armaments of The Damned v1.0Document6 pagesArmaments of The Damned v1.0Martín FierroNo ratings yet
- Midterm 05Document3 pagesMidterm 05Micki BuiNo ratings yet
- Notes About General Relativity Lecture - 6Document13 pagesNotes About General Relativity Lecture - 6Daniel PaggiattoNo ratings yet
- Complete Class 11th HandPickedDocument71 pagesComplete Class 11th HandPickedSamyak Jain100% (1)
- ADS Assignment-2 12E3Document4 pagesADS Assignment-2 12E320R21A12G3 PINNAMREDDY TEJASWININo ratings yet
- Case Study - : Wood Court RestaurantDocument1 pageCase Study - : Wood Court RestaurantkathyNo ratings yet
- CountifsDocument3 pagesCountifsgavimanigNo ratings yet
- ATF X TTB - Projects Catalogue - P.PDF - Coredownload.015911638Document20 pagesATF X TTB - Projects Catalogue - P.PDF - Coredownload.015911638Lomon SamNo ratings yet
- Milman, Rotem - Novel View On Classical Convexity TheoryDocument20 pagesMilman, Rotem - Novel View On Classical Convexity TheoryL VNo ratings yet
- Хинчин - Цепные дробиDocument58 pagesХинчин - Цепные дробиL VNo ratings yet
- Benn - The L2 Geometry of The Symplectomorphism GroupDocument162 pagesBenn - The L2 Geometry of The Symplectomorphism GroupL VNo ratings yet
- Table of Content: (Page Numbers in PDF File)Document223 pagesTable of Content: (Page Numbers in PDF File)L VNo ratings yet
- Dunne - Resurgence in Quantum Field Theory and Quantum MechanicsDocument58 pagesDunne - Resurgence in Quantum Field Theory and Quantum MechanicsL VNo ratings yet
- Algebraic Theory of Penrose's Non-Periodic Tilings of The Plane. IDocument28 pagesAlgebraic Theory of Penrose's Non-Periodic Tilings of The Plane. IL VNo ratings yet