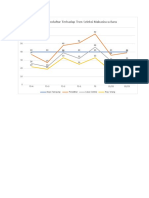
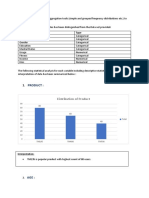
You might also like
- O Z. Preparation For Activity On Data Management .ExcelDocument4 pagesO Z. Preparation For Activity On Data Management .ExcelJethro Z. GiananNo ratings yet
- Freq. Dist.Document40 pagesFreq. Dist.Web Developer OfficialsNo ratings yet
- Box-Plot: Employee Scores Ordered (Sorted) Scores Unique ScoresDocument17 pagesBox-Plot: Employee Scores Ordered (Sorted) Scores Unique ScoresAmit JhaNo ratings yet
- Frequency DistributionDocument1 pageFrequency DistributionGerelyn EstiloNo ratings yet
- Statistics - EnglishDocument6 pagesStatistics - EnglishPalanichamy MuthuNo ratings yet
- MPS CompTech9Document44 pagesMPS CompTech9Norilyn TorresNo ratings yet
- Rasio Pendaftar Terhadap Tren Seleksi Mahasiswa BaruDocument2 pagesRasio Pendaftar Terhadap Tren Seleksi Mahasiswa BaruNur afni afifahNo ratings yet
- PANGILINAN - Biostat MIDTERMDocument8 pagesPANGILINAN - Biostat MIDTERMMira Swan100% (2)
- Subject: Type of Test Highest Possible ScoreDocument74 pagesSubject: Type of Test Highest Possible ScoreAn Rose AdepinNo ratings yet
- QUIZ No.2Document4 pagesQUIZ No.2ariansofia1031No ratings yet
- Data From 3 Quarterly Exams (Math & Science) of Grade 7 - Benevolent and Grade 8 - BegoniaDocument73 pagesData From 3 Quarterly Exams (Math & Science) of Grade 7 - Benevolent and Grade 8 - BegoniaAll ÃløñéNo ratings yet
- Maxfort School-Rohini Worksheet 1 - Organisation of Data Q1Document3 pagesMaxfort School-Rohini Worksheet 1 - Organisation of Data Q1piyush rohiraNo ratings yet
- Borja Group 5 Set B AssessmentDocument3 pagesBorja Group 5 Set B AssessmentRenz Christopher TangcaNo ratings yet
- Mps English 7 First Quarter NewDocument17 pagesMps English 7 First Quarter NewJhay Mhar ANo ratings yet
- Statistics For FinanceDocument2 pagesStatistics For FinanceFasil TadesseNo ratings yet
- Quiz4: Descriptive Stats For Continuous Variables Name: Bianca Correa Student Number: 24Document2 pagesQuiz4: Descriptive Stats For Continuous Variables Name: Bianca Correa Student Number: 24PohuyistNo ratings yet
- Aulia Ahsahra (2201030010)Document3 pagesAulia Ahsahra (2201030010)Andiimtitsal BilqisarsyamNo ratings yet
- Esnani - Assesment - SET BDocument1 pageEsnani - Assesment - SET BRenz Christopher TangcaNo ratings yet
- Gujarat Technological University (Diploma Ii-Sem July-10) : Institute Wise ResultDocument4 pagesGujarat Technological University (Diploma Ii-Sem July-10) : Institute Wise ResultParamjit Singh SahotaNo ratings yet
- BCA - 240-18, 240-20, BCA-CS-240-20 StatisticsDocument3 pagesBCA - 240-18, 240-20, BCA-CS-240-20 Statisticsiammahek123No ratings yet
- MMW L4.1 Mathematics As A ToolDocument16 pagesMMW L4.1 Mathematics As A ToolJovito D. Cabilis100% (1)
- Assignments On 9 Math Girls GroupDocument27 pagesAssignments On 9 Math Girls Group8 . zarin tabassumNo ratings yet
- FC301 - WORKSHEET 1 - The Line of Best FitDocument2 pagesFC301 - WORKSHEET 1 - The Line of Best Fitlouloujoli97No ratings yet
- Measures of Central Tendency - III: Age Group No. of StudentsDocument2 pagesMeasures of Central Tendency - III: Age Group No. of StudentsMohammad UdaipurwalaNo ratings yet
- Lecture 5 Frequency DistributionDocument2 pagesLecture 5 Frequency DistributionmaglangitmarvincNo ratings yet
- Frequency Bar Chart: Semester Frequency Relative Frequency Relative Frequency (Method)Document4 pagesFrequency Bar Chart: Semester Frequency Relative Frequency Relative Frequency (Method)vinoedhnaidu_rajagopalNo ratings yet
- AniscalMA - Learning Activity 2.1 2.3Document6 pagesAniscalMA - Learning Activity 2.1 2.3HeliNo ratings yet
- Activity For MeanDocument2 pagesActivity For MeanJoshua Mhel SamaniegoNo ratings yet
- GRADE 7 10 TLE SLAR With HighlightDocument27 pagesGRADE 7 10 TLE SLAR With HighlightChenneyCastroNo ratings yet
- Module 14 GonzalesDocument2 pagesModule 14 GonzalesWayne LipataNo ratings yet
- Stat 1&2Document35 pagesStat 1&2Owais KadiriNo ratings yet
- U.S. Public Perceptions and Communications: Safety, Security and The EnvironmentDocument21 pagesU.S. Public Perceptions and Communications: Safety, Security and The EnvironmentDaniel VenablesNo ratings yet
- Dweling Units Power FactorDocument1 pageDweling Units Power Factorefmartin21No ratings yet
- Module Exercises: Directions: Answer The Following. Show All Pertinent SolutionsDocument3 pagesModule Exercises: Directions: Answer The Following. Show All Pertinent SolutionsRojim Asio DilaoNo ratings yet
- Table No. 1 Frequency Distribution of Entrance Examination ScoresDocument5 pagesTable No. 1 Frequency Distribution of Entrance Examination ScoresRose Ann PaduaNo ratings yet
- Item Analysis Grade 10 Fourth Periodic Test 2022 2023Document1 pageItem Analysis Grade 10 Fourth Periodic Test 2022 2023RONA ANDREA TAMAYONo ratings yet
- BUS STAT Chapter-3Document22 pagesBUS STAT Chapter-3olmezestNo ratings yet
- Sts 2Document2 pagesSts 2Teereg VINo ratings yet
- Exercise Chapter 2: C) by Using Appropriate Calculation, Identify The Shape of Distribution For The Above DataDocument3 pagesExercise Chapter 2: C) by Using Appropriate Calculation, Identify The Shape of Distribution For The Above DataShasha KimNo ratings yet
- Lrdi 9Document16 pagesLrdi 9sujay giriNo ratings yet
- Elevation Section A-A-Layout1Document1 pageElevation Section A-A-Layout1lawrenceNo ratings yet
- "Weather Analysis": Agra GujaratDocument4 pages"Weather Analysis": Agra GujaratAMAN JANGIDNo ratings yet
- Quartile For Grouped DataDocument7 pagesQuartile For Grouped DataCei-Cei100% (2)
- Class Width Max Value - Min Value No. of IntervalsDocument2 pagesClass Width Max Value - Min Value No. of IntervalsbrohihassanNo ratings yet
- Statistics For Social Science 3Document20 pagesStatistics For Social Science 3TCNo ratings yet
- D6G Track-Type Tractor Super Rural 3SR00001-UP, Powered by 3306 Engine (SEBP2578 - 49) GP Do Freio e Direção.Document5 pagesD6G Track-Type Tractor Super Rural 3SR00001-UP, Powered by 3306 Engine (SEBP2578 - 49) GP Do Freio e Direção.Alex CarvalhoNo ratings yet
- Scan Feb 08, 2023Document1 pageScan Feb 08, 2023Aniket ShrivastavaNo ratings yet
- English 7 Diagnostic TestDocument7 pagesEnglish 7 Diagnostic TestJhay Mhar ANo ratings yet
- Lrdi 09 - QDocument8 pagesLrdi 09 - QadhithiaNo ratings yet
- Case Study AnalysisDocument7 pagesCase Study Analysisamandeep singhNo ratings yet
- 8102 Assignment 1 - Statistical AnalysisDocument8 pages8102 Assignment 1 - Statistical AnalysistNo ratings yet
- Biostat Lab Midterm Exam-LUMOSADDocument8 pagesBiostat Lab Midterm Exam-LUMOSADquirenicoleNo ratings yet
- Tristar AnswersDocument22 pagesTristar AnswersMine SayracNo ratings yet
- Lec 1aDocument45 pagesLec 1aHaisham AliNo ratings yet
- 0 - 2 Tahun Co (Lingkaran MNRT Usia)Document1 page0 - 2 Tahun Co (Lingkaran MNRT Usia)valencia suwardiNo ratings yet
- MADERAZO, Dheine Louise - Modmath - MMMDocument8 pagesMADERAZO, Dheine Louise - Modmath - MMMDheine MaderazoNo ratings yet
- LRDI-03 Mixed Graph With SolutionsDocument16 pagesLRDI-03 Mixed Graph With SolutionsPratyush GoelNo ratings yet
- 199 - Siti Muslihatul Jannah - Statistik - Tugas 4Document4 pages199 - Siti Muslihatul Jannah - Statistik - Tugas 4Siti Muslihatul JannahNo ratings yet
- Measures of Variability: Range: WK07-LAS1-SAP-II-11Document9 pagesMeasures of Variability: Range: WK07-LAS1-SAP-II-11Benj Jamieson DuagNo ratings yet
- Essentials of Management - 1st SemDocument8 pagesEssentials of Management - 1st SemParichay PalNo ratings yet
- Business Communication - 1st SEMDocument9 pagesBusiness Communication - 1st SEMParichay PalNo ratings yet
- Essentials of Financial Accounting - 1st SEMDocument10 pagesEssentials of Financial Accounting - 1st SEMParichay PalNo ratings yet
- Organizational Behavior - 1st SemDocument6 pagesOrganizational Behavior - 1st SemParichay PalNo ratings yet
- NMIMS Microeconomics - BookDocument312 pagesNMIMS Microeconomics - BookParichay PalNo ratings yet
- Siningbayan Field Book PDFDocument232 pagesSiningbayan Field Book PDFnathaniel zNo ratings yet
- Allison at 500, at 1500 Series Parts Catalog: 2 1 See Section 10Document7 pagesAllison at 500, at 1500 Series Parts Catalog: 2 1 See Section 10amin chaabenNo ratings yet
- Edu 637 Lesson Plan Gallivan TerryDocument11 pagesEdu 637 Lesson Plan Gallivan Terryapi-161680522No ratings yet
- Fax Cross ReferenceDocument32 pagesFax Cross ReferenceBranga CorneliuNo ratings yet
- COEN 252 Computer Forensics: Incident ResponseDocument39 pagesCOEN 252 Computer Forensics: Incident ResponseDudeviswaNo ratings yet
- Pmgsy Unified BSR December 2019 PDFDocument87 pagesPmgsy Unified BSR December 2019 PDFRoopesh Chaudhary100% (1)
- Code of Ethics Multiple Choice QuestionsDocument4 pagesCode of Ethics Multiple Choice QuestionsGideon P. Casas88% (24)
- Slates Cembrit Berona 600x300 Datasheet SirDocument2 pagesSlates Cembrit Berona 600x300 Datasheet SirJNo ratings yet
- Making The Quantum LeapDocument22 pagesMaking The Quantum LeapRJ DeLongNo ratings yet
- TVS 1 PDFDocument24 pagesTVS 1 PDFPooja PreetiNo ratings yet
- ION 900 Series Owners ManualDocument24 pagesION 900 Series Owners ManualParosanu IonelNo ratings yet
- Kesehatan Dan Keadilan Sosial inDocument20 pagesKesehatan Dan Keadilan Sosial inBobbyGunarsoNo ratings yet
- DPC Clinical PaperDocument2 pagesDPC Clinical PaperAnkita KhullarNo ratings yet
- Railway CircularsDocument263 pagesRailway CircularsDrPvss Gangadhar80% (5)
- April 24, 2008Document80 pagesApril 24, 2008Reynaldo EstomataNo ratings yet
- Forging 2Document17 pagesForging 2Amin ShafanezhadNo ratings yet
- 2019 Specimen Paper 3 Mark SchemeDocument6 pages2019 Specimen Paper 3 Mark SchemeProjeck HendraNo ratings yet
- 1.0 Design Andheri Khola Bridge, 1x25m 8.4m 3 GirderDocument18 pages1.0 Design Andheri Khola Bridge, 1x25m 8.4m 3 GirderManoj ChaudharyNo ratings yet
- Icd-10 CM Step by Step Guide SheetDocument12 pagesIcd-10 CM Step by Step Guide SheetEdel DurdallerNo ratings yet
- Introduction To SCILABDocument14 pagesIntroduction To SCILABMertwysef DevrajNo ratings yet
- Debugging With The PL/SQL Debugger: PhilippDocument51 pagesDebugging With The PL/SQL Debugger: PhilippBenjytox BenjytoxNo ratings yet
- Time-Series Forecasting: 2000 by Chapman & Hall/CRCDocument9 pagesTime-Series Forecasting: 2000 by Chapman & Hall/CRCeloco_2200No ratings yet
- Snubbing PDFDocument134 pagesSnubbing PDFNavin SinghNo ratings yet
- Enerpac Hydratight Powergen CapabilitiesDocument81 pagesEnerpac Hydratight Powergen CapabilitiesAhmed El TayebNo ratings yet
- Hyperformance Plasma: Manual GasDocument272 pagesHyperformance Plasma: Manual GasSinan Aslan100% (1)
- Research Paper About Charter ChangeDocument5 pagesResearch Paper About Charter Changegz46ktxrNo ratings yet
- Subject: Industrial Marketing Topic/Case Name: Electrical Equipment LTDDocument4 pagesSubject: Industrial Marketing Topic/Case Name: Electrical Equipment LTDRucha ShirudkarNo ratings yet
- W01 358 7304Document29 pagesW01 358 7304MROstop.comNo ratings yet
- Project 2 - Home InsuranceDocument15 pagesProject 2 - Home InsuranceNaveen KumarNo ratings yet
- 4-Sided Planer & Moulder Operation Manual: For Spares and Service ContactDocument48 pages4-Sided Planer & Moulder Operation Manual: For Spares and Service ContactAlfred TsuiNo ratings yet