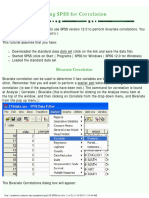
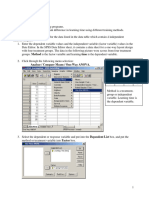
You might also like
- Stats 3Document12 pagesStats 3Marianne Christie RagayNo ratings yet
- Psychology 117 Study GuideDocument41 pagesPsychology 117 Study GuideVanessa100% (3)
- Statistics For Data ScienceDocument93 pagesStatistics For Data ScienceCesar LobatoNo ratings yet
- Week 2 Central Tendency and VariabilityDocument28 pagesWeek 2 Central Tendency and VariabilityMuhaimin Abdu AzizNo ratings yet
- Measures of Dispersion, Relative Standing and Shape: No. Biostat - 8 Date:25.01.2009Document49 pagesMeasures of Dispersion, Relative Standing and Shape: No. Biostat - 8 Date:25.01.2009pradeepNo ratings yet
- ZGE1104 Chapter 4Document7 pagesZGE1104 Chapter 4Mae RocelleNo ratings yet
- Lecture 3 Notes - PSYC 204Document8 pagesLecture 3 Notes - PSYC 204SerenaNo ratings yet
- Statistical Analysis With Software Application: Module No. 4Document13 pagesStatistical Analysis With Software Application: Module No. 4Vanessa UbaNo ratings yet
- Instructor'S Manual: Statistical Techniques in Financial ManagementDocument3 pagesInstructor'S Manual: Statistical Techniques in Financial Managementjoebloggs1888No ratings yet
- Module 4: Measures of VariabilityDocument4 pagesModule 4: Measures of VariabilityMary Haley Queen BonalosNo ratings yet
- First Stage: Lecture ThreeDocument14 pagesFirst Stage: Lecture Three翻訳すると、40秒後に死にますOMGITZTWINZNo ratings yet
- Measures of DispersionDocument13 pagesMeasures of Dispersionsabnira AfrinNo ratings yet
- Statical Data 1Document32 pagesStatical Data 1Irma Estela Marie EstebanNo ratings yet
- Research methods: Data processing, analysis and interpretationDocument35 pagesResearch methods: Data processing, analysis and interpretationbojaNo ratings yet
- Final Measures of Dispersion DR LotfiDocument54 pagesFinal Measures of Dispersion DR Lotfi1givemesome1No ratings yet
- SD 05 Descriptive Statistics - VariabilityDocument18 pagesSD 05 Descriptive Statistics - Variabilitysamuel kebedeNo ratings yet
- Statistical Inference Vs Descriptive Statistics: ConclusionsDocument19 pagesStatistical Inference Vs Descriptive Statistics: ConclusionsMaxence AncelinNo ratings yet
- Estimation Bertinoro09 Cristiano Porciani 1Document42 pagesEstimation Bertinoro09 Cristiano Porciani 1shikha singhNo ratings yet
- BRM Data Analysis TechniquesDocument53 pagesBRM Data Analysis TechniquesS- AjmeriNo ratings yet
- Anova BiometryDocument33 pagesAnova Biometryadityanarang147No ratings yet
- Measures of Central Tendency and Statistical TestsDocument6 pagesMeasures of Central Tendency and Statistical TestsJude BautistaNo ratings yet
- StatestsDocument20 pagesStatestskebakaone marumoNo ratings yet
- Week One: Introduction To Quantitative Methods MBA 2013Document49 pagesWeek One: Introduction To Quantitative Methods MBA 2013Hardik NaikNo ratings yet
- Chapter 1 Descriptives StatisticsDocument27 pagesChapter 1 Descriptives StatisticsKamil IbraNo ratings yet
- STAT1301 Notes: Steps For Scientific StudyDocument31 pagesSTAT1301 Notes: Steps For Scientific StudyjohnNo ratings yet
- Measures of VariabilityDocument5 pagesMeasures of Variabilitymathworld_0204No ratings yet
- AP Stats Study GuideDocument17 pagesAP Stats Study Guidehappyhania23No ratings yet
- Basic Statistical Concepts ExplainedDocument12 pagesBasic Statistical Concepts ExplainedIlovedocumintNo ratings yet
- ShapesDocument36 pagesShapesaue.ponytoyNo ratings yet
- BSA - PUT - SEM I - 21-22 SolutionDocument16 pagesBSA - PUT - SEM I - 21-22 SolutionRizwan SaifiNo ratings yet
- Centrall - Tendency - IVDocument53 pagesCentrall - Tendency - IVRadhika MohataNo ratings yet
- Basic ConceptsDocument9 pagesBasic Conceptshsrinivas_7No ratings yet
- Measure of DispersionDocument15 pagesMeasure of DispersionshafeezNo ratings yet
- Analysing Quantitative Data - 13april2017Document41 pagesAnalysing Quantitative Data - 13april2017Janu BahnuNo ratings yet
- DSMLDocument510 pagesDSMLRohan Nani ChowdaryNo ratings yet
- IMS 504-Week 4&5 NewDocument40 pagesIMS 504-Week 4&5 NewAhmad ShahirNo ratings yet
- W1 Lesson 1 - Basic Statistical Concepts - Module PDFDocument11 pagesW1 Lesson 1 - Basic Statistical Concepts - Module PDFKoch KentNo ratings yet
- ML Unit2 SimpleLinearRegression pdf-60-97Document38 pagesML Unit2 SimpleLinearRegression pdf-60-97Deepali KoiralaNo ratings yet
- 2013 Trends in Global Employee Engagement ReportDocument8 pages2013 Trends in Global Employee Engagement ReportAnupam BhattacharyaNo ratings yet
- Stat (I) 4-6 MaterialDocument42 pagesStat (I) 4-6 Materialamareadios60No ratings yet
- Unit 4 Descriptive StatisticsDocument8 pagesUnit 4 Descriptive StatisticsHafizAhmadNo ratings yet
- Analysis Interpretation and Use of Test DataDocument50 pagesAnalysis Interpretation and Use of Test DataJayson EsperanzaNo ratings yet
- Week 5 - Result and Analysis 1 (UP)Document7 pagesWeek 5 - Result and Analysis 1 (UP)eddy siregarNo ratings yet
- Calculating Central Tendency MeasuresDocument30 pagesCalculating Central Tendency MeasuresAlyx UbiadasNo ratings yet
- Chapter 4 Measures of Dispersion (1)Document45 pagesChapter 4 Measures of Dispersion (1)monicabalamurugan27No ratings yet
- Data Types and DistributionsDocument1 pageData Types and Distributionssk112988No ratings yet
- FRM Part 1: Basic StatisticsDocument28 pagesFRM Part 1: Basic StatisticsRa'fat JalladNo ratings yet
- Stats Mid TermDocument22 pagesStats Mid TermvalkriezNo ratings yet
- Powerpoint Presentation On: "FrequencyDocument36 pagesPowerpoint Presentation On: "Frequencyasaduzzaman asad100% (1)
- 3 Numerical Descriptive MeasuresDocument62 pages3 Numerical Descriptive MeasuresSarika JayaswalNo ratings yet
- Estrellado Rommel E. - Activity 5Document11 pagesEstrellado Rommel E. - Activity 5CBME STRATEGIC MANAGEMENTNo ratings yet
- Physiological StatisticsDocument12 pagesPhysiological StatisticsGerlyn MortegaNo ratings yet
- Research Hypothesis and Statistical HypothesisDocument8 pagesResearch Hypothesis and Statistical HypothesiskkNo ratings yet
- Research IV - QTR 3 - Week 3Document7 pagesResearch IV - QTR 3 - Week 3andrei bercadezNo ratings yet
- IMP Video ConceptDocument56 pagesIMP Video ConceptParthJainNo ratings yet
- Business Analytics Course SummaryDocument15 pagesBusiness Analytics Course Summarymohita.gupta4No ratings yet
- Two-stage Cluster Sampling Design and AnalysisDocument119 pagesTwo-stage Cluster Sampling Design and AnalysisZahra HassanNo ratings yet
- ReviewDocument98 pagesReviewDenise FriedmanNo ratings yet
- Measures of Dispersion EditDocument8 pagesMeasures of Dispersion EditShimaa KashefNo ratings yet
- SPSSChapter 8Document8 pagesSPSSChapter 8Syeda Sehrish KiranNo ratings yet
- 0 Data Entry ADocument7 pages0 Data Entry ANazia SyedNo ratings yet
- 0 Data Entry BDocument5 pages0 Data Entry BNazia SyedNo ratings yet
- Edur 8131 Notes 5 T TestDocument23 pagesEdur 8131 Notes 5 T TestNazia SyedNo ratings yet
- 1 Correlation BDocument3 pages1 Correlation BNazia SyedNo ratings yet
- 0 Correlation ADocument5 pages0 Correlation ANazia SyedNo ratings yet
- 1 Frequencies BDocument3 pages1 Frequencies BNazia SyedNo ratings yet
- Edur 8131 Notes 2 Normal Standard ScoresDocument9 pagesEdur 8131 Notes 2 Normal Standard ScoresNazia SyedNo ratings yet
- 0 T-Tests ADocument17 pages0 T-Tests ANazia SyedNo ratings yet
- 0 Regression ADocument9 pages0 Regression ANazia SyedNo ratings yet
- Edur 8131 Notes 7 Chi SquareDocument16 pagesEdur 8131 Notes 7 Chi SquareNazia SyedNo ratings yet
- 0 Anova Oneway ADocument10 pages0 Anova Oneway ANazia SyedNo ratings yet
- Edur 8131 Graphical Display ExamplesDocument9 pagesEdur 8131 Graphical Display ExamplesNazia SyedNo ratings yet
- EDUR8132 IntroductoryNotes 17august2010Document5 pagesEDUR8132 IntroductoryNotes 17august2010Nazia SyedNo ratings yet
- EDUR8132 IntroductoryNotesDocument6 pagesEDUR8132 IntroductoryNotesNazia SyedNo ratings yet
- 1 Stemleaf CDocument3 pages1 Stemleaf CNazia SyedNo ratings yet
- Correlated Samples T-Test ExerciseDocument2 pagesCorrelated Samples T-Test ExerciseNazia SyedNo ratings yet
- Edur 8131 Notes 6 CorrelationDocument25 pagesEdur 8131 Notes 6 CorrelationNazia SyedNo ratings yet
- 1 Graphs CDocument30 pages1 Graphs CNazia SyedNo ratings yet
- EDUR 8131 Notes 8a Simple RegressionDocument19 pagesEDUR 8131 Notes 8a Simple RegressionNazia SyedNo ratings yet
- 1 Anova Oneway BDocument3 pages1 Anova Oneway BNazia SyedNo ratings yet
- 1 Frequencies ADocument8 pages1 Frequencies ANazia SyedNo ratings yet
- Homework 2 Correlated Ttests AnswersDocument2 pagesHomework 2 Correlated Ttests AnswersNazia SyedNo ratings yet
- Edur 8131 Notes 3 Statistical InferenceDocument9 pagesEdur 8131 Notes 3 Statistical InferenceNazia SyedNo ratings yet
- EDUR 8131 Notes 8b Multiple RegressionDocument16 pagesEDUR 8131 Notes 8b Multiple RegressionNazia SyedNo ratings yet
- Edur 8131 Notes 4 (Revised) Hypothesis Testing and One Sample Z TestDocument16 pagesEdur 8131 Notes 4 (Revised) Hypothesis Testing and One Sample Z TestNazia SyedNo ratings yet
- Correlation CoefficientsDocument9 pagesCorrelation CoefficientsNazia SyedNo ratings yet
- Fraas Johnson Neyman Interaction ProcedureDocument11 pagesFraas Johnson Neyman Interaction ProcedureNazia SyedNo ratings yet
- HypothesesDocument11 pagesHypothesesNazia SyedNo ratings yet
- Chi Square ExerciseDocument5 pagesChi Square ExerciseNazia SyedNo ratings yet
- Chap 4Document14 pagesChap 4Lue starNo ratings yet
- Critical ValueDocument12 pagesCritical ValueZAIRUL AMIN BIN RABIDIN (FRIM)No ratings yet
- Unit# 6 Basic Statistic Exercise 6.2Document12 pagesUnit# 6 Basic Statistic Exercise 6.2Asghar Ali90% (10)
- Ge 4 Sim UpdatedDocument79 pagesGe 4 Sim UpdatedAna Llemit MionesNo ratings yet
- BRM Presentation Group 5 - Univariate & Bivariate AnalysisDocument26 pagesBRM Presentation Group 5 - Univariate & Bivariate AnalysisMeet ShankhalaNo ratings yet
- Premet XL Vers 04.2008Document34 pagesPremet XL Vers 04.2008cajascNo ratings yet
- Corner Lot PDFDocument35 pagesCorner Lot PDFsureshchattuNo ratings yet
- A Level Biology Maths SkillsDocument3 pagesA Level Biology Maths SkillsmosulNo ratings yet
- Analysis of Financial Performance of Kumari BankDocument34 pagesAnalysis of Financial Performance of Kumari BankGopal Rimal100% (4)
- Sampling and Sampling DistributionDocument43 pagesSampling and Sampling DistributionShailendra Shastri100% (1)
- Stat 2 MCQDocument115 pagesStat 2 MCQGharsellaoui MuhamedNo ratings yet
- Chapter 8 Hypothesis Testing With Two SamplesDocument43 pagesChapter 8 Hypothesis Testing With Two Samplesdanilo roblico jr.No ratings yet
- Business Statistics End Term Exam (Set 1)Document5 pagesBusiness Statistics End Term Exam (Set 1)Shani KumarNo ratings yet
- Stat 110, Lecture 7 Continuous Probability Distributions: Bheavlin@stat - Stanford.eduDocument35 pagesStat 110, Lecture 7 Continuous Probability Distributions: Bheavlin@stat - Stanford.edujamesyuNo ratings yet
- Finding Percentiles Under the Normal CurveDocument4 pagesFinding Percentiles Under the Normal CurveFrank Hubay MananquilNo ratings yet
- Lordk Edid 6507-Case Study Assignment 1 2 3Document35 pagesLordk Edid 6507-Case Study Assignment 1 2 3api-310042469No ratings yet
- CH 123Document63 pagesCH 123bgsrizkiNo ratings yet
- Long-Term Measurements On A Cable-Stayed BridgeDocument6 pagesLong-Term Measurements On A Cable-Stayed Bridgeunistudent89No ratings yet
- Ravel - Clinical Laboratory MedicineDocument1,151 pagesRavel - Clinical Laboratory MedicineWiLaGatchaLianNo ratings yet
- Process Control Instrumentation Technology 8th EdDocument62 pagesProcess Control Instrumentation Technology 8th EdSaeed AshaNo ratings yet
- Fine CMT AllDocument355 pagesFine CMT AllArfan MehmoodNo ratings yet
- AML-2203 Advanced Python AI and ML Tools AssignmentDocument19 pagesAML-2203 Advanced Python AI and ML Tools AssignmentRohit NNo ratings yet
- Kuliah Minggu-3Document13 pagesKuliah Minggu-3teesaganNo ratings yet
- Mean Median Mode With Playing CardsDocument7 pagesMean Median Mode With Playing Cardsapi-4662265160% (1)
- Statistical Quality ControlDocument40 pagesStatistical Quality ControlCancelynshrnpNo ratings yet
- 2020 Mock Exam A - Morning SessionDocument22 pages2020 Mock Exam A - Morning SessionTaha TinwalaNo ratings yet
- Quantitative Techniques Trimester 1 Mba Ktu 2016Document2 pagesQuantitative Techniques Trimester 1 Mba Ktu 2016Athul RNo ratings yet
- Statistics GlossaryDocument3 pagesStatistics Glossaryapi-3836734No ratings yet
- Normal Distribution ProblemsDocument2 pagesNormal Distribution ProblemsAjitesh KumarNo ratings yet
- qm2 NotesDocument9 pagesqm2 NotesdeltathebestNo ratings yet