You might also like
- Machine Learning Course - Kernel RegressionDocument9 pagesMachine Learning Course - Kernel RegressionnagybalyNo ratings yet
- SVM and KernelsDocument13 pagesSVM and KernelsUlil HerdiantoNo ratings yet
- Lecture5 PartitionspectralDocument14 pagesLecture5 Partitionspectralapi-3834272No ratings yet
- 04 KernelizationDocument10 pages04 Kernelizationanonymous 127No ratings yet
- Antiderivative and Indefinite IntegralDocument5 pagesAntiderivative and Indefinite IntegralDimas HernadyNo ratings yet
- PQT PDFDocument113 pagesPQT PDFchandu pandhareNo ratings yet
- DX D X DX D X X X X: 2 Cos - 2 Cos 1 2 - 2 Cos 2 Sin 2 Sin 2Document7 pagesDX D X DX D X X X X: 2 Cos - 2 Cos 1 2 - 2 Cos 2 Sin 2 Sin 2Hamad KtkNo ratings yet
- Mathematics Formulary PDFDocument30 pagesMathematics Formulary PDFfizarimaeNo ratings yet
- CS 179: GPU ProgrammingDocument40 pagesCS 179: GPU ProgrammingRajulNo ratings yet
- KalkDocument27 pagesKalkHafidz NurrahmanNo ratings yet
- hw4 SolDocument4 pageshw4 SolemersonNo ratings yet
- Derivatives of Transcendental FunctionsDocument10 pagesDerivatives of Transcendental FunctionsCole NadzNo ratings yet
- Yogesh Meena (BCA-M15 4th SEM) CONM CCEDocument10 pagesYogesh Meena (BCA-M15 4th SEM) CONM CCEYogesh MeenaNo ratings yet
- 9.3 Integration by Parts 4Document9 pages9.3 Integration by Parts 4Hin Wa LeungNo ratings yet
- Lévy Stable Probability Laws, Lévy Flights, Space-Fractional Diffusion and Kinetic Equations (Two Lectures)Document17 pagesLévy Stable Probability Laws, Lévy Flights, Space-Fractional Diffusion and Kinetic Equations (Two Lectures)Dony HidayatNo ratings yet
- ML CheatsheetDocument1 pageML Cheatsheetfrancoisroyer7709No ratings yet
- Improper Integral1Document25 pagesImproper Integral1Lev DunNo ratings yet
- Coordinate Descent: Ryan Tibshirani Convex Optimization 10-725/36-725Document29 pagesCoordinate Descent: Ryan Tibshirani Convex Optimization 10-725/36-725Yang LongNo ratings yet
- Chapter 9: Numerical DifferentiationDocument22 pagesChapter 9: Numerical DifferentiationDlgash Bahri FatoNo ratings yet
- North South University: Dy DXDocument5 pagesNorth South University: Dy DXRifat Tasfia OtriNo ratings yet
- Function Approximation, Interpolation, and Curve FittingDocument53 pagesFunction Approximation, Interpolation, and Curve FittingAlexis Bryan RiveraNo ratings yet
- Chapter ThreeDocument15 pagesChapter ThreeMustafa SagbanNo ratings yet
- Math 2 Mid Sample QuestionDocument2 pagesMath 2 Mid Sample QuestionJamiul HasanNo ratings yet
- Function Approximation, Interpolation, and Curve Fitting PDFDocument53 pagesFunction Approximation, Interpolation, and Curve Fitting PDFMikhail Tabucal100% (1)
- Integrales Una Variable by CortésDocument23 pagesIntegrales Una Variable by CortésAlex Prim NavajasNo ratings yet
- C 06 Anti DifferentiationDocument31 pagesC 06 Anti Differentiationebrahimipour1360No ratings yet
- 20 2 Product NormsDocument4 pages20 2 Product NormsDmitri ZaitsevNo ratings yet
- Introduction To Rstudio: Creating VectorsDocument11 pagesIntroduction To Rstudio: Creating VectorsMandeep SinghNo ratings yet
- RT-2 Set-C SolDocument4 pagesRT-2 Set-C Solsachinplayer2006No ratings yet
- 2 - IntegrationDocument19 pages2 - IntegrationSri Devi NagarjunaNo ratings yet
- Basic Integration Methods MaDocument9 pagesBasic Integration Methods MaTOI 1802No ratings yet
- Methods of Applied Mathematics-II: M L+M L M L M M L M M LDocument2 pagesMethods of Applied Mathematics-II: M L+M L M L M M L M M LJatin RamboNo ratings yet
- Cheat MLDocument1 pageCheat MLRahul BabarwalNo ratings yet
- Assignment 1Document2 pagesAssignment 1Shivam PatidarNo ratings yet
- Chem 373 - Lecture 2: The Born Interpretation of The WavefunctionDocument29 pagesChem 373 - Lecture 2: The Born Interpretation of The WavefunctionNuansak3No ratings yet
- Gaussian Process - Part 2: 1 2 N T I 1 2 N TDocument4 pagesGaussian Process - Part 2: 1 2 N T I 1 2 N TmeoxauNo ratings yet
- Random Signals: EE 524, Fall 2004, # 7 1Document22 pagesRandom Signals: EE 524, Fall 2004, # 7 1Md. Mizanur RahmanNo ratings yet
- Cs 229, Autumn 2016 Problem Set #2: Naive Bayes, SVMS, and TheoryDocument20 pagesCs 229, Autumn 2016 Problem Set #2: Naive Bayes, SVMS, and TheoryZeeshan Ali SayyedNo ratings yet
- Lec 1Document15 pagesLec 1Muhammed YasserNo ratings yet
- 18.650 Statistics For ApplicationsDocument15 pages18.650 Statistics For ApplicationsbobNo ratings yet
- DERIVADAS 4to ADocument2 pagesDERIVADAS 4to AAlexander Eddy Pacha ChallcoNo ratings yet
- Non Linear Iterative MethodsDocument11 pagesNon Linear Iterative Methodstahiruabdulrahmanbaaba3No ratings yet
- 13 Generalized Programming and Subgradient Optimization PDFDocument20 pages13 Generalized Programming and Subgradient Optimization PDFAbrar HashmiNo ratings yet
- DERIVATIVESDocument12 pagesDERIVATIVESmike capitoNo ratings yet
- Name - MTH 1001 GSA Name GradeDocument6 pagesName - MTH 1001 GSA Name GradechinnasaibNo ratings yet
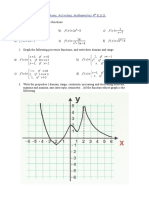
- Functions. ActivitiesDocument5 pagesFunctions. ActivitiesJuan Manuel Veigas BuendiaNo ratings yet
- Legendre PDFDocument2 pagesLegendre PDFgabao123No ratings yet
- MECOM093Document17 pagesMECOM093Jose RissoNo ratings yet
- Ed TareaDocument8 pagesEd TareaJosé M. Rivera TapiaNo ratings yet
- Differentiation RulesDocument7 pagesDifferentiation Ruleszidminhcd1992No ratings yet
- TBS INt-EntDocument4 pagesTBS INt-EntAnonymous HSXJ3qIAeFNo ratings yet
- Calculus1 Final Exam (2020)Document1 pageCalculus1 Final Exam (2020)xwsc4dzzyrNo ratings yet
- Integration TechniquesDocument18 pagesIntegration Techniquesஏம்மனுஎல்லெ செலேச்டினோNo ratings yet
- Homework 10 - SolutionDocument8 pagesHomework 10 - SolutionAlaa SaadNo ratings yet
- Formula Sheet DEF121Document6 pagesFormula Sheet DEF121Andy Ngo100% (1)
- KDE Optimization PrimerDocument8 pagesKDE Optimization PrimerNumXL ProNo ratings yet
- Bridge Course - Differentiation - 1 - VMathDocument56 pagesBridge Course - Differentiation - 1 - VMathTusharkanti SahuNo ratings yet
- Namma Kalvi 11th Maths Book Back and Creative Questions em 219385Document209 pagesNamma Kalvi 11th Maths Book Back and Creative Questions em 219385Think BetterNo ratings yet
- CCTV Proposal Quotation-1 Orine EdutechDocument5 pagesCCTV Proposal Quotation-1 Orine EdutechĄrpit Rāz100% (1)
- 2946 1308 00 Leroy Somer LSA47.2 Installation & MaintenanceDocument20 pages2946 1308 00 Leroy Somer LSA47.2 Installation & MaintenanceJORGE ARMANDO CARRASCO TICLLENo ratings yet
- Data Science BooksDocument11 pagesData Science BooksAnalytics Insight100% (1)
- Neonatal HypothermiaDocument8 pagesNeonatal Hypothermiamia liaNo ratings yet
- ECN 331 Fall 2018 SyllabusDocument6 pagesECN 331 Fall 2018 SyllabusDat BoiNo ratings yet
- A 268 - A 268M - 01 Qti2oc0wmq - PDFDocument6 pagesA 268 - A 268M - 01 Qti2oc0wmq - PDFMan98No ratings yet
- Classification by Depth Distribution of Phytoplankton and ZooplanktonDocument31 pagesClassification by Depth Distribution of Phytoplankton and ZooplanktonKeanu Denzel BolitoNo ratings yet
- Initial 2Document6 pagesInitial 2Asad HoseinyNo ratings yet
- Reflective EssayDocument4 pagesReflective Essayapi-385380366No ratings yet
- Sample CISSP ResumeDocument4 pagesSample CISSP ResumeAskia MappNo ratings yet
- Music and Yoga Are Complementary To Each OtherDocument9 pagesMusic and Yoga Are Complementary To Each OthersatishNo ratings yet
- 1250kva DG SetDocument61 pages1250kva DG SetAnagha Deb100% (1)
- Additional Clinical Case Study TemplatesDocument4 pagesAdditional Clinical Case Study TemplatesMikhaela Andree MarianoNo ratings yet
- Generation Transmission and Distribution Notes.Document88 pagesGeneration Transmission and Distribution Notes.Abhishek NirmalkarNo ratings yet
- The Explanatory GapDocument2 pagesThe Explanatory GapPapuna ChivadzeNo ratings yet
- HLTARO001 HLTAROO05 Student Assessment Booklet 1 1Document68 pagesHLTARO001 HLTAROO05 Student Assessment Booklet 1 1Amber PreetNo ratings yet
- Boot Time Memory ManagementDocument22 pagesBoot Time Memory Managementblack jamNo ratings yet
- Emmanuel John MangahisDocument15 pagesEmmanuel John MangahisEmmanuel MangahisNo ratings yet
- Air Quality StandardsDocument2 pagesAir Quality StandardsJanmejaya BarikNo ratings yet
- S.NO. Students Name Contact Number CAP 10TH: Ideal Institute of Pharamacy, Wada SESSION-2020-21Document12 pagesS.NO. Students Name Contact Number CAP 10TH: Ideal Institute of Pharamacy, Wada SESSION-2020-21DAMBALENo ratings yet
- Machine Design Key 2014Document15 pagesMachine Design Key 2014SouvikDasNo ratings yet
- NS2-DVN-2540.Rev4 - Profomal Packing List BLR Piping Hanger Support Beam-Unit 2 - 20200710Document27 pagesNS2-DVN-2540.Rev4 - Profomal Packing List BLR Piping Hanger Support Beam-Unit 2 - 20200710PHAM PHI HUNGNo ratings yet
- Screen 2014 Uricchio 119 27Document9 pagesScreen 2014 Uricchio 119 27NazishTazeemNo ratings yet
- Pasir Ex UD - Am Tes 2024Document8 pagesPasir Ex UD - Am Tes 2024Achmad MaulanaNo ratings yet
- Patchu Time Management and Its Relation To The Working StudentsDocument17 pagesPatchu Time Management and Its Relation To The Working StudentsGui De OcampoNo ratings yet
- How To Draw The Platform Business Model Map-David RogersDocument5 pagesHow To Draw The Platform Business Model Map-David RogersworkneshNo ratings yet
- FreeBSD HandbookDocument26 pagesFreeBSD Handbookhembeck119No ratings yet
- Analysis and Design of Suspended Buildings: Creative and Innovative Report-1Document14 pagesAnalysis and Design of Suspended Buildings: Creative and Innovative Report-1Nirmal RaviNo ratings yet
- SN Quick Reference 2018Document6 pagesSN Quick Reference 2018pinakin4uNo ratings yet
- ESET TechnologyDocument21 pagesESET TechnologyValentin SalcianuNo ratings yet