You might also like
- A.'.A.'. Syllabus and CurriculumDocument45 pagesA.'.A.'. Syllabus and CurriculumCelephaïs Press / Unspeakable Press (Leng)100% (7)
- PLDT Account No. 0193069916 PDFDocument4 pagesPLDT Account No. 0193069916 PDFEli FaustinoNo ratings yet
- Handouts On Freq DistributionDocument6 pagesHandouts On Freq DistributionJohn Rey Manolo BaylosisNo ratings yet
- A Flowering Tree NotesDocument4 pagesA Flowering Tree Notesparidhi50% (4)
- Utilization of Assessment DataDocument50 pagesUtilization of Assessment DataIvy Claris Ba-awa Iquin100% (3)
- List of All ProjectsDocument152 pagesList of All ProjectsMhm ReddyNo ratings yet
- Data Management: MidtermDocument85 pagesData Management: MidtermJerome James Lopez0% (1)
- 4th Exam Quarter - Math 7Document1 page4th Exam Quarter - Math 7JenniferCarabotMacasNo ratings yet
- Aircraft Strategy and Operations of The Soviet Air Force 1986 CompressDocument280 pagesAircraft Strategy and Operations of The Soviet Air Force 1986 CompressMatthew Guest100% (1)
- Frequency Distribution - Data Management PDFDocument69 pagesFrequency Distribution - Data Management PDFPolly VicenteNo ratings yet
- A Short Guide For Feature Engineering and Feature SelectionDocument32 pagesA Short Guide For Feature Engineering and Feature SelectionjainnitkNo ratings yet
- C.T.A. Case No. 4312-Central Cement Corporation Petitioner vs.Document14 pagesC.T.A. Case No. 4312-Central Cement Corporation Petitioner vs.Andrew Lastrollo100% (1)
- Math 7 - Q4, WK3 LasDocument5 pagesMath 7 - Q4, WK3 LasNiña Romina G. NavaltaNo ratings yet
- Measures of Central TendencyDocument5 pagesMeasures of Central TendencyAngelica FloraNo ratings yet
- Frequency Distribution: Education DepartmentDocument9 pagesFrequency Distribution: Education DepartmentLeo Cordel Jr.No ratings yet
- Stastics Chapt 3Document15 pagesStastics Chapt 3nityaNo ratings yet
- Stat & ProbabilityDocument67 pagesStat & Probabilityanna luna berryNo ratings yet
- Chapter 2: Frequency Distribution and Measures of Central Tendency 2.1 A FREQUENCY DISTRIBUTION Is A Tabular Arrangement of Data Whereby The Data Is GroupedDocument9 pagesChapter 2: Frequency Distribution and Measures of Central Tendency 2.1 A FREQUENCY DISTRIBUTION Is A Tabular Arrangement of Data Whereby The Data Is GroupedDaille Wroble GrayNo ratings yet
- Gec 4 Final Problem Sets With Answers HLDocument14 pagesGec 4 Final Problem Sets With Answers HLJo-anna CadigalNo ratings yet
- Statistika BisnisDocument20 pagesStatistika BisnisZkdlin 23No ratings yet
- Frequency Distribution TableDocument9 pagesFrequency Distribution TableMalano Charmaine B.No ratings yet
- Statistics in Education - Made SimpleDocument26 pagesStatistics in Education - Made SimpleSatheeshNo ratings yet
- Lesson 3 Frequency DistributionDocument55 pagesLesson 3 Frequency Distributionkookie bunnyNo ratings yet
- Module 3. Organizing and Summarizing Quantitative DataDocument13 pagesModule 3. Organizing and Summarizing Quantitative DataPrincess YmasNo ratings yet
- Frequency Distribution and Charts and GraphsDocument61 pagesFrequency Distribution and Charts and GraphsPriya ChughNo ratings yet
- Reviewer MathDocument18 pagesReviewer MathYAGI, Miyuki F.No ratings yet
- 3 Frequency DistributionDocument16 pages3 Frequency Distributionjavan borcelisNo ratings yet
- MODULE 3statistics1Document13 pagesMODULE 3statistics1mart arvyNo ratings yet
- Collecting Organizing and Presentation of DataDocument6 pagesCollecting Organizing and Presentation of DataYumeko SNo ratings yet
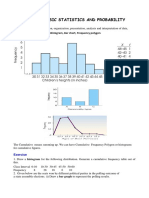
- Unit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonDocument6 pagesUnit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonVenkatesh WaranNo ratings yet
- Ken Black Solution Chapter 2Document29 pagesKen Black Solution Chapter 2maulikfromitNo ratings yet
- The Measures of Central TendencyDocument40 pagesThe Measures of Central TendencyMark Lester Brosas TorreonNo ratings yet
- Lesson Plan 16 (Science High)Document7 pagesLesson Plan 16 (Science High)Justin Paul VallinanNo ratings yet
- Chapter 11 Measures of Central TendencyDocument26 pagesChapter 11 Measures of Central TendencyJAMES DERESANo ratings yet
- AL1 Week 9Document4 pagesAL1 Week 9Reynante Louis DedaceNo ratings yet
- Medians: (Grouped Data)Document4 pagesMedians: (Grouped Data)Rico Tabu-aoNo ratings yet
- Statistics, mg4Document58 pagesStatistics, mg4Himanshu ChawlaNo ratings yet
- Other Statistical MethodsDocument55 pagesOther Statistical MethodsJean DelaNo ratings yet
- Quartile & DeviationDocument31 pagesQuartile & DeviationM Pavan KumarNo ratings yet
- Quartile & DeviationDocument31 pagesQuartile & DeviationM Pavan KumarNo ratings yet
- Measures of Central TendencyDocument26 pagesMeasures of Central Tendencydegraciajaylace6No ratings yet
- Measure of Central Tendency (Ungrouped and Grouped Data)Document40 pagesMeasure of Central Tendency (Ungrouped and Grouped Data)Ahlan Marciano Emmanuel De Silva100% (1)
- Measure of Central TendencyDocument18 pagesMeasure of Central Tendencyprince samNo ratings yet
- Q4 Summative Test 3Document7 pagesQ4 Summative Test 3Gerald MaimadNo ratings yet
- Measure of Position For Ingrouped DataDocument19 pagesMeasure of Position For Ingrouped DataRavie Acuna DiongsonNo ratings yet
- Statistical Treatment of Data: Frequency Distribution Graphical Representation Symmetry & SkewnessDocument12 pagesStatistical Treatment of Data: Frequency Distribution Graphical Representation Symmetry & SkewnessFrancis Carlo B. RamosNo ratings yet
- Statistics and Probability Chp4Document8 pagesStatistics and Probability Chp4Renor SagunNo ratings yet
- Chapter 02 PowerPointDocument29 pagesChapter 02 PowerPointtantriNo ratings yet
- StatsB FrequencyDistributionsDocument2 pagesStatsB FrequencyDistributionsmery9jean9lasamNo ratings yet
- Frequency DistributionDocument24 pagesFrequency DistributionFrank EsolanNo ratings yet
- Measures of Central TendencyDocument7 pagesMeasures of Central TendencyAnjo Pasiolco CanicosaNo ratings yet
- Chapter 3.2 - Graphical PresentationDocument17 pagesChapter 3.2 - Graphical PresentationMary Justine JumawanNo ratings yet
- Carpio, Joezerk A. - Unit 4 - Checked (PDF - Io)Document1 pageCarpio, Joezerk A. - Unit 4 - Checked (PDF - Io)Joezerk CarpioNo ratings yet
- Adv Stat Data PresentationDocument57 pagesAdv Stat Data Presentationjhoana patunganNo ratings yet
- Chapter 02 - PowerPointDocument20 pagesChapter 02 - PowerPointSimantoPreeom100% (1)
- For Chapter 2, Statistical Techniques in Business & EconomicsDocument61 pagesFor Chapter 2, Statistical Techniques in Business & EconomicsVic SzeNo ratings yet
- 7 Frequency Distribution - Quantitative DataDocument13 pages7 Frequency Distribution - Quantitative DataARC SVIORNo ratings yet
- Slides - B. Stat - I, Lecture 6 - Chap 3, Session 2, Median, ModeDocument22 pagesSlides - B. Stat - I, Lecture 6 - Chap 3, Session 2, Median, ModeKim NamjoonneNo ratings yet
- Worksheet in Measures of Central TendencyDocument5 pagesWorksheet in Measures of Central TendencyNormel De AsisNo ratings yet
- Chapter 02 PowerPointDocument31 pagesChapter 02 PowerPointMutiara BintangNo ratings yet
- Find Mean, Median, Modal Class From Grouped Data: Session - 4Document24 pagesFind Mean, Median, Modal Class From Grouped Data: Session - 4PRIYA KUMARINo ratings yet
- BBA (N) - 103 Central TendencyDocument20 pagesBBA (N) - 103 Central TendencyPratyum PradhanNo ratings yet
- Topic 11measures of Central Tendency For Grouped Data PDFDocument3 pagesTopic 11measures of Central Tendency For Grouped Data PDFThe ONeNo ratings yet
- Present Status of Advertising Industry in IndiaDocument25 pagesPresent Status of Advertising Industry in IndiaMeenal Kapoor100% (1)
- Anchoring BiasDocument2 pagesAnchoring Biassara collinNo ratings yet
- East Coast Yacht's Expansion Plans-06!02!2008 v2Document3 pagesEast Coast Yacht's Expansion Plans-06!02!2008 v2percyNo ratings yet
- Ebf Rehearsal RubricDocument1 pageEbf Rehearsal Rubricapi-518770643No ratings yet
- Land Laws LAW 446: AssignmentDocument21 pagesLand Laws LAW 446: AssignmentpriyaNo ratings yet
- The Road Not TakenDocument12 pagesThe Road Not TakenAnjanette De LeonNo ratings yet
- Screenshot 2024-02-14 at 11.35.01 PMDocument32 pagesScreenshot 2024-02-14 at 11.35.01 PMemaantejani10No ratings yet
- Michigan Clinic 2008 NotesDocument10 pagesMichigan Clinic 2008 NotesCoach Brown100% (3)
- Kelompok 1 Recount TextDocument11 pagesKelompok 1 Recount TextElvina RahmayaniNo ratings yet
- GST Compensation CessDocument2 pagesGST Compensation CessPalak JioNo ratings yet
- UNIT-5 ppspNOTESDocument29 pagesUNIT-5 ppspNOTESEverbloom EverbloomNo ratings yet
- Kanban COP - Lean Kanban Training PDFDocument14 pagesKanban COP - Lean Kanban Training PDFEdward Schaefer100% (1)
- Vienza: Lighting and SecurityDocument4 pagesVienza: Lighting and SecurityShadi AbdelsalamNo ratings yet
- Internal Guide-BE Project Groups 2015-16Document28 pagesInternal Guide-BE Project Groups 2015-16Aravind IyerNo ratings yet
- CHAPTER - 7 Managing Growth and TransactionDocument25 pagesCHAPTER - 7 Managing Growth and TransactionTesfahun TegegnNo ratings yet
- Data Coding SchemesDocument26 pagesData Coding SchemesJovanie CadungogNo ratings yet
- Advertising & SALES PROMOTIONAL-AirtelDocument78 pagesAdvertising & SALES PROMOTIONAL-AirtelDasari AnilkumarNo ratings yet
- PW 1989 12Document76 pagesPW 1989 12Milton NastNo ratings yet
- WN Ce1905 enDocument3 pagesWN Ce1905 enanuagarwal anuNo ratings yet
- Print Book FinalDocument25 pagesPrint Book FinalKhurram AliNo ratings yet
- Nec Exhibition BrochureDocument4 pagesNec Exhibition BrochurejppullepuNo ratings yet
- SnapManual PDFDocument77 pagesSnapManual PDFnaser150No ratings yet
- 3.6-6kva Battery Cabinet: 1600Xp/1600Xpi SeriesDocument22 pages3.6-6kva Battery Cabinet: 1600Xp/1600Xpi SeriesIsraelNo ratings yet