You might also like
- Triumph Workshop Instruction ManualDocument213 pagesTriumph Workshop Instruction ManualhmanzillaNo ratings yet
- Regression Analysis Using Least Squares MethodDocument15 pagesRegression Analysis Using Least Squares MethodKhirstina CurryNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 4: Nonlinear Models and Transformations of VariablesDocument30 pagesIntroduction To Econometrics, 5 Edition: Chapter 4: Nonlinear Models and Transformations of VariablesRamarcha KumarNo ratings yet
- Assumptions C.1, C.3, C.4, C.5, and C.8, and The Consequences of Their Violations Are The Same As Those For Model B and They Will Not Be Discussed Further HereDocument70 pagesAssumptions C.1, C.3, C.4, C.5, and C.8, and The Consequences of Their Violations Are The Same As Those For Model B and They Will Not Be Discussed Further HereaamelsNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisDocument17 pagesIntroduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 6: Specification of Regression VariablesDocument17 pagesIntroduction To Econometrics, 5 Edition: Chapter 6: Specification of Regression VariablesRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisDocument38 pagesIntroduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisRamarcha KumarNo ratings yet
- Two-Variable Regression Model - The Problem of EstimationDocument35 pagesTwo-Variable Regression Model - The Problem of EstimationAyesha RehmanNo ratings yet
- Multiple Regression Analysis - EstimationDocument23 pagesMultiple Regression Analysis - EstimationujjwalNo ratings yet
- The Joint PDF of The RVs - X&YDocument5 pagesThe Joint PDF of The RVs - X&YDawood AliNo ratings yet
- Backward Elimination and Stepwise RegressionDocument5 pagesBackward Elimination and Stepwise RegressionNajwa AmellalNo ratings yet
- Backward Elimination and Stepwise RegressionDocument5 pagesBackward Elimination and Stepwise RegressionNajwa AmellalNo ratings yet
- Class Material - Multiple Linear RegressionDocument57 pagesClass Material - Multiple Linear RegressionVishvajit KumbharNo ratings yet
- Unit II D - Regression ModelingDocument14 pagesUnit II D - Regression ModelingarunaNo ratings yet
- Regression LinesDocument7 pagesRegression LinesManas KumarNo ratings yet
- Regression Analysis: Estimation and PropertiesDocument20 pagesRegression Analysis: Estimation and PropertiesRadityaNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 2: Properties of The Regression Coefficients and Hypothesis TestingDocument32 pagesIntroduction To Econometrics, 5 Edition: Chapter 2: Properties of The Regression Coefficients and Hypothesis TestingRamarcha KumarNo ratings yet
- Lesson 12 - Introduction To Regression and Correlation Analysis Regression AnalysisDocument39 pagesLesson 12 - Introduction To Regression and Correlation Analysis Regression AnalysisFe GregorioNo ratings yet
- Lecture 5Document19 pagesLecture 5Blytzx GamesNo ratings yet
- Chapter3 PDFDocument52 pagesChapter3 PDFHuy AnhNo ratings yet
- Nota Topik 1Document25 pagesNota Topik 1nursyafira8927No ratings yet
- QM PDFDocument62 pagesQM PDFtharani1771_32442248No ratings yet
- Multi KolDocument44 pagesMulti KolEcca Caca CacaNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 8: Stochastic Regressors and Measurement ErrorsDocument32 pagesIntroduction To Econometrics, 5 Edition: Chapter 8: Stochastic Regressors and Measurement ErrorsRamarcha KumarNo ratings yet
- CLRM Assumptions Multicollinearity Detection RemediesDocument95 pagesCLRM Assumptions Multicollinearity Detection RemediesLâm Bulls0% (1)
- Kiær Et Al 2007 p2Document1 pageKiær Et Al 2007 p2Lars KiærNo ratings yet
- Mathematical Statistics Lecture Notes: Chapter 0: Review of ProbabilityDocument117 pagesMathematical Statistics Lecture Notes: Chapter 0: Review of Probabilityjifeng sunNo ratings yet
- Principal Component AnalysisDocument24 pagesPrincipal Component AnalysisAidaRCastroNo ratings yet
- U X V and y V X UDocument24 pagesU X V and y V X UAshaNo ratings yet
- FEM Example 2D TrussDocument10 pagesFEM Example 2D TrussTheCandiceJNo ratings yet
- Multiple Regression Analysis: y + X + X + - . - X + UDocument43 pagesMultiple Regression Analysis: y + X + X + - . - X + UMike JonesNo ratings yet
- U II AssignmentDocument7 pagesU II AssignmentHari KrushnaNo ratings yet
- Multiple Linear Regression Model: E y To Depend On More Than One ExplanatoryDocument42 pagesMultiple Linear Regression Model: E y To Depend On More Than One Explanatoryrakib chowdhuryNo ratings yet
- Econometrie - Prof - JulaDocument60 pagesEconometrie - Prof - JulaMike ManNo ratings yet
- Ch5 Multivariate MethodsDocument26 pagesCh5 Multivariate MethodsRikiNo ratings yet
- Vector Calculus ProblemsDocument11 pagesVector Calculus ProblemsNishanth VigneshNo ratings yet
- Strss - Strain Problems1Document5 pagesStrss - Strain Problems1badr amNo ratings yet
- Tutorial 6Document1 pageTutorial 6Sandipan DharNo ratings yet
- Differential Equations - Additional Topics First Order ODEDocument34 pagesDifferential Equations - Additional Topics First Order ODEVincent Allen Corbilla IINo ratings yet
- Exam Formulas (2021)Document2 pagesExam Formulas (2021)9bpj6qfyhwNo ratings yet
- Multiple Regression Analysis (MLR)Document28 pagesMultiple Regression Analysis (MLR)Samara ChaudhuryNo ratings yet
- Lecture 11Document28 pagesLecture 11fffNo ratings yet
- Problem Set 1 - SOLUTIONS ECH-32306 Advanced Microeconomics, Part 1, Fall 2016Document6 pagesProblem Set 1 - SOLUTIONS ECH-32306 Advanced Microeconomics, Part 1, Fall 2016Adriana SenaNo ratings yet
- Typical Examples of UNIT-2Document8 pagesTypical Examples of UNIT-2iam prajapatiNo ratings yet
- The Lognormal Random Multivariate: An IntroductionDocument5 pagesThe Lognormal Random Multivariate: An IntroductionDiego Castañeda LeónNo ratings yet
- Stat Mining 47Document1 pageStat Mining 47Adonis HuaytaNo ratings yet
- Chapter 5 - Partial DerivativesDocument23 pagesChapter 5 - Partial Derivativesdbreddy287No ratings yet
- Regression Analysis ExplainedDocument28 pagesRegression Analysis ExplainedGidisa LachisaNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 2: Properties of The Regression Coefficients and Hypothesis TestingDocument35 pagesIntroduction To Econometrics, 5 Edition: Chapter 2: Properties of The Regression Coefficients and Hypothesis TestingRamarcha KumarNo ratings yet
- Linear Regression PartADocument34 pagesLinear Regression PartAAkshay kashyapNo ratings yet
- Mathematical ExpectationDocument28 pagesMathematical ExpectationKinPranNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 5: Dummy VariablesDocument15 pagesIntroduction To Econometrics, 5 Edition: Chapter 5: Dummy VariablesRamarcha KumarNo ratings yet
- Two Dimensional Random Variables ExplainedDocument38 pagesTwo Dimensional Random Variables ExplainedSneghaa PNo ratings yet
- Achieving The Efficient Frontier of Risky Asset PortfoliosDocument19 pagesAchieving The Efficient Frontier of Risky Asset Portfoliosjoherpe2000No ratings yet
- History and Basic Terms Example References Conclusions: Uncertainties of Measurement in ExcelDocument29 pagesHistory and Basic Terms Example References Conclusions: Uncertainties of Measurement in ExcelmanojvattavilaNo ratings yet
- Thvi 4Document29 pagesThvi 4oigres725No ratings yet
- Multiple Linear Regression Model Chapter SummaryDocument41 pagesMultiple Linear Regression Model Chapter SummarySourabh SinghNo ratings yet
- Multiple Linear Regression Model: (Or EquivalentlyDocument41 pagesMultiple Linear Regression Model: (Or EquivalentlySri VastavNo ratings yet
- Multiple Regression Analysis: y + X + X + - . - X + UDocument28 pagesMultiple Regression Analysis: y + X + X + - . - X + Uhabtamulegese24No ratings yet
- Lecture 07 03-11-21Document13 pagesLecture 07 03-11-21Tayyab HusaainNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisDocument28 pagesIntroduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 8: Stochastic Regressors and Measurement ErrorsDocument26 pagesIntroduction To Econometrics, 5 Edition: Chapter 8: Stochastic Regressors and Measurement ErrorsRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 8: Stochastic Regressors and Measurement ErrorsDocument32 pagesIntroduction To Econometrics, 5 Edition: Chapter 8: Stochastic Regressors and Measurement ErrorsRamarcha KumarNo ratings yet
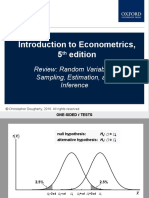
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument7 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisDocument25 pagesIntroduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument43 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument22 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisDocument21 pagesIntroduction To Econometrics, 5 Edition: Chapter 3: Multiple Regression AnalysisRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument40 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument33 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument62 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument13 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument22 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument40 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument62 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument43 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument7 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument21 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument28 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument12 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument39 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument12 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument16 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument13 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument16 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument28 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument7 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument5 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument21 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- Introduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceDocument26 pagesIntroduction To Econometrics, 5 Edition: Review: Random Variables, Sampling, Estimation, and InferenceRamarcha KumarNo ratings yet
- MS-DOS Basics GuideDocument40 pagesMS-DOS Basics GuidemancangkulNo ratings yet
- Career MapDocument1 pageCareer Mapapi-247973511No ratings yet
- Marcom Opc ProductsDocument8 pagesMarcom Opc ProductsMARCOM SRLNo ratings yet
- 2011 Sakura WSHP R410A - Installation ManualDocument12 pages2011 Sakura WSHP R410A - Installation ManualMaurizio DumitracheNo ratings yet
- Sec. 6.7 Peak Structural Response From The Response SpectrumDocument2 pagesSec. 6.7 Peak Structural Response From The Response SpectrumIt'x PathanNo ratings yet
- Malware PersistentDocument57 pagesMalware PersistentPhạmPhúQuíNo ratings yet
- Final Assignment 2 ChafikDocument16 pagesFinal Assignment 2 ChafikSaheed A BusuraNo ratings yet
- Acoustic Doppler Effect With Universal Counter: (Item No.: P2150405)Document7 pagesAcoustic Doppler Effect With Universal Counter: (Item No.: P2150405)Muhammad IshfaqNo ratings yet
- Excel Data Exploration for Lemonade Stand SalesDocument11 pagesExcel Data Exploration for Lemonade Stand SalesArif Marias0% (2)
- Business Data Toolset: Step 1: Create Module Pool Program - SAPLZFG - FSCM With Screen 9001. (Function Group: ZFG - FSCM)Document10 pagesBusiness Data Toolset: Step 1: Create Module Pool Program - SAPLZFG - FSCM With Screen 9001. (Function Group: ZFG - FSCM)Ivonne Rocio MeloNo ratings yet
- 48.3 Events and The Union and Intersection of Events#Document4 pages48.3 Events and The Union and Intersection of Events#Paulo EsguerraNo ratings yet
- Master Resource Book in Physics For JEE Main 2020 by D. B. SinghskksDocument1,425 pagesMaster Resource Book in Physics For JEE Main 2020 by D. B. SinghskksSAHIL YADAV 7825No ratings yet
- Motion in One Direction ProblemsDocument12 pagesMotion in One Direction ProblemsRoda Gayle RañadaNo ratings yet
- Experiment Number 2 Recrystallization and Melting Point DeterminationDocument5 pagesExperiment Number 2 Recrystallization and Melting Point DeterminationMaugri Grace Kristi LalumaNo ratings yet
- Guidlines For SeatrialsDocument14 pagesGuidlines For SeatrialsmariodalNo ratings yet
- Week 4 Home Learning PlanDocument11 pagesWeek 4 Home Learning PlanJessel CleofeNo ratings yet
- Inverse Laplace Transform by Partial FractionsDocument6 pagesInverse Laplace Transform by Partial Fractionsbessam123No ratings yet
- Biochem 12th Sept Amino AcidDocument4 pagesBiochem 12th Sept Amino AcidShreeraj BadgujarNo ratings yet
- DDW 2Document5 pagesDDW 2celmailNo ratings yet
- Interplast UPVC Pipe SpecificationDocument4 pagesInterplast UPVC Pipe SpecificationJOSEPH APPIAHNo ratings yet
- Standard Test Method For Splitting Tensile Strength of Cylindrical Concrete Specimens1Document5 pagesStandard Test Method For Splitting Tensile Strength of Cylindrical Concrete Specimens1Lupita RamirezNo ratings yet
- 3-1/2Document1 page3-1/2Mohamed FikryNo ratings yet
- Overcurrent Protection / 7SJ63Document38 pagesOvercurrent Protection / 7SJ63KnjigescribdNo ratings yet
- K Durga RamanjaneyuluDocument4 pagesK Durga RamanjaneyuluKAPIL ARORANo ratings yet
- Sultamicillin Tablets 375 MG IHSDocument14 pagesSultamicillin Tablets 375 MG IHSGiancarlo Alessandro VettorNo ratings yet
- Manual Controls C807Document40 pagesManual Controls C807Felipe Aguilar Rivera100% (1)
- What is a subnet and subnet maskDocument6 pagesWhat is a subnet and subnet maskAnuraj SrivastavaNo ratings yet
- Aws C5.6-89Document75 pagesAws C5.6-89venkateshNo ratings yet