You might also like
- Success Factors of Virtual Teams in the Conflict of Cross-Cultural Team StructuresFrom EverandSuccess Factors of Virtual Teams in the Conflict of Cross-Cultural Team StructuresNo ratings yet
- DocxDocument4 pagesDocxAbcdeNo ratings yet
- Topic 8 - Organization and Presentation of DataDocument30 pagesTopic 8 - Organization and Presentation of DataNeil Dave SuarezNo ratings yet
- PTM Group AssgnDocument9 pagesPTM Group AssgnNirta RathiNo ratings yet
- RSU Data Executive Report 2009Document40 pagesRSU Data Executive Report 2009frederickNo ratings yet
- Chapter # 4 Analysis: DegreeDocument8 pagesChapter # 4 Analysis: DegreeDure KashafNo ratings yet
- 4.jaw Crasher and Screen AnalysisDocument9 pages4.jaw Crasher and Screen Analysisazzam2 anwrNo ratings yet
- Ascendig Qty Q4 PeakDocument4 pagesAscendig Qty Q4 PeakarmantayebNo ratings yet
- 042 ANOVA2WAY1Document5 pages042 ANOVA2WAY1anuragbose0429No ratings yet
- Measuring Process Capability of Manufacturing ExperimentsDocument12 pagesMeasuring Process Capability of Manufacturing ExperimentsAman NagraleNo ratings yet
- 4 - 5947019371120429006econo F-TableDocument2 pages4 - 5947019371120429006econo F-TableBizu AtnafuNo ratings yet
- Chocolate Case StudyDocument6 pagesChocolate Case StudySagnik SharangiNo ratings yet
- ASMPDocument8 pagesASMPIjjaz MohamedNo ratings yet
- Individual Project: BUS 250/ECON 265 Issue Date: September 26, 2021 Submission Date: October 21, 2021Document12 pagesIndividual Project: BUS 250/ECON 265 Issue Date: September 26, 2021 Submission Date: October 21, 2021haseeb ahmedNo ratings yet
- Group 6 - AssignmentDocument2 pagesGroup 6 - AssignmentKundan KaumarNo ratings yet
- Laporan Praktikum StatDas2020 - Siti Rubi'Ah (G1B019069) FISIKA ADocument59 pagesLaporan Praktikum StatDas2020 - Siti Rubi'Ah (G1B019069) FISIKA ASiti Rubi'ahNo ratings yet
- Business Forecasting J. Holton (1) - 251-300Document50 pagesBusiness Forecasting J. Holton (1) - 251-300nabiilahhsaNo ratings yet
- Case 1Document23 pagesCase 1Emad RashidNo ratings yet
- FrequenciesDocument3 pagesFrequenciesricco andriNo ratings yet
- Tabel Akhir: Usia 35.49 12.304 18-72 32.62-38.36Document5 pagesTabel Akhir: Usia 35.49 12.304 18-72 32.62-38.36sumiyasihNo ratings yet
- Craig Mallinckrodt - Building Your Career As A Statistician - A Practical Guide To Longevity, Happiness, and Accomplishment-CRC Press - Chapman & Hall (2023)Document366 pagesCraig Mallinckrodt - Building Your Career As A Statistician - A Practical Guide To Longevity, Happiness, and Accomplishment-CRC Press - Chapman & Hall (2023)crazymoneyNo ratings yet
- SAT and College GPA RelationshipDocument3 pagesSAT and College GPA Relationshipشاهزیب علیNo ratings yet
- Anova analysis of IT professional evaluationsDocument10 pagesAnova analysis of IT professional evaluationsAngelica Irish Peradilla ChuaNo ratings yet
- Laporan Sementara Mie BasahDocument5 pagesLaporan Sementara Mie BasahRifqiDhiyaFauzanNo ratings yet
- RM - Multivariate AnalysisDocument19 pagesRM - Multivariate AnalysismuneerppNo ratings yet
- Apéndice B: B.4 Valores Críticos de La Distribución F en Un Nivel de Significancia de 5%Document2 pagesApéndice B: B.4 Valores Críticos de La Distribución F en Un Nivel de Significancia de 5%anthonyMNo ratings yet
- Chap 2 ComputationDocument6 pagesChap 2 ComputationSNo ratings yet
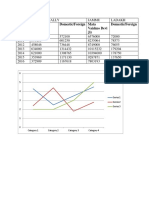
- Amaranth Ji Domestic/Foreign Mata Vaishno Devi Ji) Domestic/ForeignDocument12 pagesAmaranth Ji Domestic/Foreign Mata Vaishno Devi Ji) Domestic/ForeignMir AqibNo ratings yet
- Forecasting - Muhammad Idzhar Faisa - 120310200084Document10 pagesForecasting - Muhammad Idzhar Faisa - 120310200084MUHAMMAD IDZHAR FAISANo ratings yet
- Summary Table For Metabolic Calculations For Treadmill ExerciseDocument1 pageSummary Table For Metabolic Calculations For Treadmill ExercisePhuong le DinhNo ratings yet
- AlMunifPipes - PVC - CPVC - Pipes 1 PDFDocument1 pageAlMunifPipes - PVC - CPVC - Pipes 1 PDFAli KhiljiNo ratings yet
- Datos CategóricosDocument451 pagesDatos Categóricoslaura melissa100% (1)
- GLOBE Phase 2 Aggregated Societal Culture DataDocument58 pagesGLOBE Phase 2 Aggregated Societal Culture DataVaibhav BahlNo ratings yet
- Improving Yarn Quality and Productivity with Appropriate Spacer SelectionDocument4 pagesImproving Yarn Quality and Productivity with Appropriate Spacer SelectionDrWeaam AlkhateebNo ratings yet
- Effect of Spacers at Ring FrameDocument4 pagesEffect of Spacers at Ring Frameritesh0raj-2No ratings yet
- Sri Chaitanya IIT Academy., India.: JEE-MAIN (WTM-1)Document1 pageSri Chaitanya IIT Academy., India.: JEE-MAIN (WTM-1)Kumkum KumbarahalliNo ratings yet
- Quantitative Data Analysis ExplainedDocument18 pagesQuantitative Data Analysis ExplainedGautam KamraNo ratings yet
- Quiz 3Document7 pagesQuiz 3Mae Ann GonzalesNo ratings yet
- Welcome To Metads: Miles MPG MaintenanceDocument18 pagesWelcome To Metads: Miles MPG Maintenancemichael rose0% (1)
- SMS Project ReportDocument12 pagesSMS Project Reportshafikul37No ratings yet
- Exploring Rich Features for Sentiment Analysis Using Machine Learning ModelsDocument86 pagesExploring Rich Features for Sentiment Analysis Using Machine Learning ModelsramliNo ratings yet
- Melody F. GrimaldoDocument10 pagesMelody F. Grimaldoglenn maltoNo ratings yet
- StatsDocument8 pagesStatsprajaktbNo ratings yet
- Data - Analysis (AutoRecovered)Document13 pagesData - Analysis (AutoRecovered)SUJALNo ratings yet
- Ntse Stage Ii: CODE: 13 - 15 Answer KeysDocument31 pagesNtse Stage Ii: CODE: 13 - 15 Answer KeysSRANo ratings yet
- Suhail Assigment 1Document7 pagesSuhail Assigment 1Suhail AshrafNo ratings yet
- Microsoft Word - EXERCISESSIM-6pdfDocument4 pagesMicrosoft Word - EXERCISESSIM-6pdfDelvo EGNo ratings yet
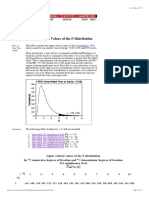
- Upper Critical Values of The F DistributionDocument11 pagesUpper Critical Values of The F DistributionYadi GugunNo ratings yet
- Date of Test: Non-Destructive Testing (NDT) / Ultrasonic Pulse Velocity (UPV) & Compressive Testing Strenght (CTM)Document65 pagesDate of Test: Non-Destructive Testing (NDT) / Ultrasonic Pulse Velocity (UPV) & Compressive Testing Strenght (CTM)GaneshNo ratings yet
- Operations Research Topics Survey Data SummaryDocument42 pagesOperations Research Topics Survey Data Summaryshifa asherNo ratings yet
- AnovaDocument3 pagesAnovaArvind KumarNo ratings yet
- We Can See The Cases From Cluster Membership Table Which Cases Belongs To Which ClustersDocument4 pagesWe Can See The Cases From Cluster Membership Table Which Cases Belongs To Which ClustersAman SankrityayanNo ratings yet
- Table A.12 Studentized Range Distribution Upper Percentage Points - Values of Q (0.05 K, V)Document1 pageTable A.12 Studentized Range Distribution Upper Percentage Points - Values of Q (0.05 K, V)Chris CahillNo ratings yet
- Cutting Time StudyDocument11 pagesCutting Time Studytanya guptaNo ratings yet
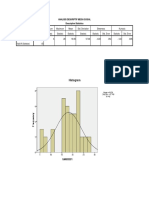
- Analisis Deskriptif Media Sosial Descriptive StatisticsDocument5 pagesAnalisis Deskriptif Media Sosial Descriptive StatisticsNur EvaNo ratings yet
- Research Methods Group Assignment Quantitative AnalysisDocument14 pagesResearch Methods Group Assignment Quantitative AnalysissaidaNo ratings yet
- Laporan Sementara Mie Basah-1Document5 pagesLaporan Sementara Mie Basah-1DindaAnggieNo ratings yet
- Basic Stats Assignment 1Document22 pagesBasic Stats Assignment 1Snimy StephenNo ratings yet
- Determination of Sensitive Proteins in Beer by Nephelometry - Submitted On Behalf of The Analysis Committee of The European Brewery ConventionDocument4 pagesDetermination of Sensitive Proteins in Beer by Nephelometry - Submitted On Behalf of The Analysis Committee of The European Brewery ConventionChí HữuNo ratings yet
- Frequencies: StatisticsDocument3 pagesFrequencies: Statisticsricco andriNo ratings yet
- Distance Calculation Between 2 Points On EarthDocument3 pagesDistance Calculation Between 2 Points On EarthGirish Madhavan Nambiar100% (2)
- ADVANCED PRACTICE TEST 2Document7 pagesADVANCED PRACTICE TEST 2phươngNo ratings yet
- Dosicard-R User's Manual (1) - FixedDocument67 pagesDosicard-R User's Manual (1) - Fixedbogdy0073No ratings yet
- Interpreting SNT TC 1A PDF 2Document1 pageInterpreting SNT TC 1A PDF 2Jagannath SahuNo ratings yet
- Defining Public HealthDocument36 pagesDefining Public Healthv.shivakumarNo ratings yet
- Revised Both Curri 2021-V3Document105 pagesRevised Both Curri 2021-V3mezigebu100% (1)
- Math6 q1 Mod5 AdditionofDecimals v4-SIGNEDDocument34 pagesMath6 q1 Mod5 AdditionofDecimals v4-SIGNEDARRIANE JOY TOLEDONo ratings yet
- PVT Behavior of Fluids: Dr. M. SubramanianDocument58 pagesPVT Behavior of Fluids: Dr. M. SubramanianRama GaurNo ratings yet
- Pragmatics Kel 2Document10 pagesPragmatics Kel 2i iNo ratings yet
- Green MarketingDocument20 pagesGreen MarketingMukesh PrajapatiNo ratings yet
- SAT Practice Test 1 Combined PDFDocument122 pagesSAT Practice Test 1 Combined PDFRay728No ratings yet
- LGU Performance Monitoring FrameworkDocument3 pagesLGU Performance Monitoring FrameworkMichelle GozonNo ratings yet
- MECHATRONICSSYSTEMSDocument12 pagesMECHATRONICSSYSTEMSAbolaji MuazNo ratings yet
- Division Quarterly Unified Test English 6Document21 pagesDivision Quarterly Unified Test English 6rogielynNo ratings yet
- CO2 Declaration Summary - Template - 1.2Document3 pagesCO2 Declaration Summary - Template - 1.2Musa GürsoyNo ratings yet
- Stellisept - Med - Scrub MSDSDocument10 pagesStellisept - Med - Scrub MSDSChoice OrganoNo ratings yet
- Read ChromaticDocument20 pagesRead ChromaticGURNOORNo ratings yet
- 9 E.T.H.E.RDocument53 pages9 E.T.H.E.Rjamjam_95678853100% (17)
- Literacy Day in IndiaDocument10 pagesLiteracy Day in IndiaThe United IndianNo ratings yet
- Isherwood A Single ManDocument66 pagesIsherwood A Single ManS A100% (3)
- Ucla Dissertation CommitteeDocument7 pagesUcla Dissertation CommitteeWriteMyPapersDiscountCodeCleveland100% (1)
- #500 Series Bearings: Lubo Industries, IncDocument25 pages#500 Series Bearings: Lubo Industries, IncmateenNo ratings yet
- School of Mathematics and Statistics Spring Semester 2013-2014 Mathematical Methods For Statistics 2 HoursDocument2 pagesSchool of Mathematics and Statistics Spring Semester 2013-2014 Mathematical Methods For Statistics 2 HoursNico NicoNo ratings yet
- Formulating Rules in Finding The NTH TermDocument17 pagesFormulating Rules in Finding The NTH TermMaximino Eduardo SibayanNo ratings yet
- ComparativeDocument5 pagesComparativeROUZBEH BANIHASHEMINo ratings yet
- đề 20Document5 pagesđề 20duongnguyenthithuy2008No ratings yet
- Danny Debois: Tips for Effective Whip Speeches in DebateDocument2 pagesDanny Debois: Tips for Effective Whip Speeches in DebateJOSE FRANCISCO VERGARA MUÑOZNo ratings yet
- IE423 PS1 Probability and Statistics Review QuestionsDocument5 pagesIE423 PS1 Probability and Statistics Review QuestionsYasemin YücebilgenNo ratings yet
- Technical Data Sheet: Product NameDocument3 pagesTechnical Data Sheet: Product NameAndres DelaCruzNo ratings yet
- MCQ BSTDocument57 pagesMCQ BSTraj photostateNo ratings yet