You might also like
- Practical Engineering, Process, and Reliability StatisticsFrom EverandPractical Engineering, Process, and Reliability StatisticsNo ratings yet
- Overview Of Bayesian Approach To Statistical Methods: SoftwareFrom EverandOverview Of Bayesian Approach To Statistical Methods: SoftwareNo ratings yet
- Central Tendency Measures ExplainedDocument22 pagesCentral Tendency Measures ExplainedEvelyn ArjonaNo ratings yet
- Central Tendencies Ver 3.1Document18 pagesCentral Tendencies Ver 3.1Aivan Lloyd CapuleNo ratings yet
- Measures of Central TendencyDocument30 pagesMeasures of Central TendencyYukti SharmaNo ratings yet
- Measures of Central Tendency: Mean, Median, ModeDocument28 pagesMeasures of Central Tendency: Mean, Median, ModeFerlyn Claire Basbano LptNo ratings yet
- Stat I CH- III PPTDocument19 pagesStat I CH- III PPTbrucknasu279No ratings yet
- Central Tendency Variation Skewness Individual Performance RelationshipsDocument9 pagesCentral Tendency Variation Skewness Individual Performance RelationshipsWena PurayNo ratings yet
- Arithmetic Mean, Median and Mode ExplainedDocument13 pagesArithmetic Mean, Median and Mode ExplainedNawazish KhanNo ratings yet
- Mean DefinitionDocument5 pagesMean Definitionapi-126876773No ratings yet
- Mean Median AnswersDocument10 pagesMean Median Answerstoy sanghaNo ratings yet
- Claudia-3m CorrectedDocument34 pagesClaudia-3m CorrectedLeoncio LumabanNo ratings yet
- Median and mode - key concepts, examples, and uses of measures of central tendencyDocument12 pagesMedian and mode - key concepts, examples, and uses of measures of central tendencyAkshay TiwariNo ratings yet
- 1 Mean, Mode, MedianDocument13 pages1 Mean, Mode, Median32 Jeswin KpNo ratings yet
- Statistical Analysis With Software Application: Module No. 3Document13 pagesStatistical Analysis With Software Application: Module No. 3Vanessa UbaNo ratings yet
- Lesson 4 Measure of Central TendencyDocument20 pagesLesson 4 Measure of Central Tendencyrahmanzaini100% (1)
- BS Unit 2Document37 pagesBS Unit 2Sneha DavisNo ratings yet
- Assessment - Learning 2.report. Siachongco - Tan.Document4 pagesAssessment - Learning 2.report. Siachongco - Tan.Jean LaurelNo ratings yet
- First Stage: Lecture ThreeDocument14 pagesFirst Stage: Lecture Three翻訳すると、40秒後に死にますOMGITZTWINZNo ratings yet
- Basics of Statistics: Descriptive Statistics Inferential StatisticsDocument6 pagesBasics of Statistics: Descriptive Statistics Inferential StatisticsKzy ayanNo ratings yet
- Research II Q4 Measures of VariabilityDocument54 pagesResearch II Q4 Measures of Variabilityhrhe heheNo ratings yet
- RM Final Chapter 1Document56 pagesRM Final Chapter 1Dhwani RajyaguruNo ratings yet
- AssessmentDocument43 pagesAssessmentlynethmarabiNo ratings yet
- Measures of Central TendencyDocument40 pagesMeasures of Central TendencyAnagha AnuNo ratings yet
- Asl Mean, Median ModeDocument13 pagesAsl Mean, Median ModeJiesel MayNo ratings yet
- Measure of Central TendencyDocument113 pagesMeasure of Central TendencyRajdeep DasNo ratings yet
- Chapter 1 Descriptives StatisticsDocument27 pagesChapter 1 Descriptives StatisticsKamil IbraNo ratings yet
- Measures of Central TendencyDocument40 pagesMeasures of Central TendencyAnagha AnuNo ratings yet
- A. Statistics - Information On The ProjectDocument15 pagesA. Statistics - Information On The ProjectAMIE ELCIT JOSE 20212065No ratings yet
- Measures of Central TendencyDocument6 pagesMeasures of Central TendencyShiv RanjanNo ratings yet
- MMW-7 2Document40 pagesMMW-7 2Unknown UnknownNo ratings yet
- Measures of Central Tendency: Part 3.1 MeanDocument33 pagesMeasures of Central Tendency: Part 3.1 MeanEdrianne Ranara Dela RamaNo ratings yet
- Basic Concepts in StatisticsDocument40 pagesBasic Concepts in StatisticsJeffrey CabarrubiasNo ratings yet
- Chapter 4 Describing Educational Data Libmanan GroupDocument31 pagesChapter 4 Describing Educational Data Libmanan Groupjoy borjaNo ratings yet
- State9 Project Work Statistics PDF May 24 2012-5-25 PM 1 8 Meg EvoziDocument27 pagesState9 Project Work Statistics PDF May 24 2012-5-25 PM 1 8 Meg EvoziMuhammadHazran100% (1)
- Measures of Central Tendency Dispersion and CorrelationDocument27 pagesMeasures of Central Tendency Dispersion and CorrelationFranco Martin Mutiso100% (1)
- Mba Semester 1 Mb0040 - Statistics For Management-4 Credits (Book ID: B1129) Assignment Set - 1 (60 Marks)Document10 pagesMba Semester 1 Mb0040 - Statistics For Management-4 Credits (Book ID: B1129) Assignment Set - 1 (60 Marks)amarendrasumanNo ratings yet
- Measures of Central Tendency: Learning Activity Sheets in Mathematics 7 Quarter Iv - Week 6 IntroductionsDocument7 pagesMeasures of Central Tendency: Learning Activity Sheets in Mathematics 7 Quarter Iv - Week 6 IntroductionsAliza Rose MarmitaNo ratings yet
- Measures of Central Tendency: Mean, Mode, MedianDocument30 pagesMeasures of Central Tendency: Mean, Mode, Medianafnan nabiNo ratings yet
- Stats NotesDocument16 pagesStats NotesDivyanshuNo ratings yet
- Mean Median ModeDocument12 pagesMean Median ModeSriram Mohan100% (2)
- Measures of Central TendencyDocument24 pagesMeasures of Central TendencyJoshua RaninNo ratings yet
- 3 Measures of Central TendencyDocument70 pages3 Measures of Central TendencyDennis ManejeroNo ratings yet
- Measures of Central TendencyDocument6 pagesMeasures of Central TendencyCarlo YambaoNo ratings yet
- Measures of Central Tendency: A Guide to AveragesDocument36 pagesMeasures of Central Tendency: A Guide to Averagesroshni100% (1)
- Measures of Central Tendency: Arithmetic Mean, Median and ModeDocument111 pagesMeasures of Central Tendency: Arithmetic Mean, Median and ModeVishal KumarNo ratings yet
- X X X X N X N: 1. Discuss/define Three Measures of Central TendencyDocument7 pagesX X X X N X N: 1. Discuss/define Three Measures of Central TendencyPandurang ThatkarNo ratings yet
- The Measures of Central TendencyDocument26 pagesThe Measures of Central TendencytojiflmsNo ratings yet
- Descriptive Statistics Chapter SummaryDocument15 pagesDescriptive Statistics Chapter Summary23985811100% (2)
- StatisticsDocument26 pagesStatisticscherryNo ratings yet
- CH-3 PPT For Basic Stat (Repaired)Document43 pagesCH-3 PPT For Basic Stat (Repaired)Sani MohammedNo ratings yet
- Why It Is Necessary To Summarise Data? Explain The Approaches Available To Summarize The Data Distributions?Document4 pagesWhy It Is Necessary To Summarise Data? Explain The Approaches Available To Summarize The Data Distributions?Chandan KishoreNo ratings yet
- Chapter 2 PPT EngDocument29 pagesChapter 2 PPT Engaju michaelNo ratings yet
- Mean, Median, and Mode For Ungrouped & Group DataDocument4 pagesMean, Median, and Mode For Ungrouped & Group DataSafa AbcNo ratings yet
- Measures of Central Tendency PositionDocument12 pagesMeasures of Central Tendency PositionCaren Pelayo JonelasNo ratings yet
- Statistics Miscellaneous QuestionsDocument3 pagesStatistics Miscellaneous QuestionsNipun GoyalNo ratings yet
- GE 104 Module 4Document24 pagesGE 104 Module 4TeacherNo ratings yet
- ChandruDocument27 pagesChandruSidhant BhayanaNo ratings yet
- HW #2 ResearchDocument1 pageHW #2 ResearchEvelyn ArjonaNo ratings yet
- Mind MapDocument1 pageMind MapEvelyn ArjonaNo ratings yet
- Financial Intermediaries: Diagram 4 A.) No IntermediaryDocument11 pagesFinancial Intermediaries: Diagram 4 A.) No IntermediaryEvelyn ArjonaNo ratings yet
- Chapter III FinDocument40 pagesChapter III FinEvelyn ArjonaNo ratings yet
- Stats AnalysisDocument2 pagesStats AnalysisEvelyn ArjonaNo ratings yet
- Government FinalDocument6 pagesGovernment FinalEvelyn ArjonaNo ratings yet
- HW #2 StatsDocument1 pageHW #2 StatsEvelyn ArjonaNo ratings yet
- Megaworld Corporation PFRS 15 adoption challenges and adjustmentsDocument2 pagesMegaworld Corporation PFRS 15 adoption challenges and adjustmentsEvelyn ArjonaNo ratings yet
- Business Research HW #1Document2 pagesBusiness Research HW #1Evelyn ArjonaNo ratings yet
- QuestionnaireDocument2 pagesQuestionnaireEvelyn ArjonaNo ratings yet
- HW #2 StatsDocument1 pageHW #2 StatsEvelyn ArjonaNo ratings yet
- HW #2 ResearchDocument1 pageHW #2 ResearchEvelyn ArjonaNo ratings yet
- Business Research HW #1Document2 pagesBusiness Research HW #1Evelyn ArjonaNo ratings yet
- Megaworld Corporation PFRS 15 adoption challenges and adjustmentsDocument2 pagesMegaworld Corporation PFRS 15 adoption challenges and adjustmentsEvelyn ArjonaNo ratings yet
- Nickel AsiaDocument2 pagesNickel AsiaEvelyn ArjonaNo ratings yet
- Nickel AsiaDocument2 pagesNickel AsiaEvelyn ArjonaNo ratings yet
- What Is A Fire Rainbow?Document2 pagesWhat Is A Fire Rainbow?Evelyn ArjonaNo ratings yet
- OntempDocument3 pagesOntempEvelyn ArjonaNo ratings yet
- OntempDocument3 pagesOntempEvelyn ArjonaNo ratings yet
- CinemaDocument2 pagesCinemaEvelyn ArjonaNo ratings yet
- CinemaDocument2 pagesCinemaEvelyn ArjonaNo ratings yet
- HistoryDocument4 pagesHistoryEvelyn ArjonaNo ratings yet
- Accounting Insight PDFDocument2 pagesAccounting Insight PDFEvelyn ArjonaNo ratings yet
- TransportationDocument5 pagesTransportationEvelyn ArjonaNo ratings yet
- Accounting Insight PDFDocument2 pagesAccounting Insight PDFEvelyn ArjonaNo ratings yet
- ScienceDocument22 pagesScienceEvelyn ArjonaNo ratings yet
- GovernmentDocument3 pagesGovernmentEvelyn ArjonaNo ratings yet
- Numeric MethodDocument66 pagesNumeric MethodashokNo ratings yet
- Quantitative Macroeconomics Log-LinearizationDocument20 pagesQuantitative Macroeconomics Log-LinearizationAmil MusovicNo ratings yet
- Exp 3 - Acid Daffa Madri AthaDocument6 pagesExp 3 - Acid Daffa Madri Athadaffa MadriNo ratings yet
- Implicitly Defined Curves and Their TangentsDocument5 pagesImplicitly Defined Curves and Their TangentsRaphael Sevilla0% (1)
- Multivariate Data AnalysisDocument24 pagesMultivariate Data AnalysisDenise MacielNo ratings yet
- Teaching of Structural AnalysisDocument34 pagesTeaching of Structural AnalysisOmar ST100% (2)
- Decision Analysis ContentDocument35 pagesDecision Analysis ContentHunger Beater100% (1)
- Nonlinear Control - Hassan K. KhalilDocument400 pagesNonlinear Control - Hassan K. KhalilTuhin Mitra100% (1)
- MatricesDocument1 pageMatricesDonboss LaitonjamNo ratings yet
- The characteristics of logarithm and exponential functionsDocument5 pagesThe characteristics of logarithm and exponential functionsbcsopiNo ratings yet
- Assignment 2 DISC 322: Optimization Instructor: Kamran Rashid Mirza Ameen Hyder 19110262 Jawwad Hassan 19110282Document8 pagesAssignment 2 DISC 322: Optimization Instructor: Kamran Rashid Mirza Ameen Hyder 19110262 Jawwad Hassan 19110282Mirza Ameen HyderNo ratings yet
- Statistical Service Form UndergradDocument1 pageStatistical Service Form UndergradBurento DesuNo ratings yet
- The Development of A Test On Critical Thinking: August 2008Document9 pagesThe Development of A Test On Critical Thinking: August 2008mvnivanNo ratings yet
- BSC Statistics Syllabus 01122015Document16 pagesBSC Statistics Syllabus 01122015sandhyaNo ratings yet
- Hypothesis Testing ChapterDocument84 pagesHypothesis Testing ChapterbullejarsoNo ratings yet
- Nota SemDocument39 pagesNota Semwartawan24100% (1)
- Risk Assessment and Analysis Methods Qualitative Quantitative - Joa - Eng - 0421Document6 pagesRisk Assessment and Analysis Methods Qualitative Quantitative - Joa - Eng - 0421Lee Taeyong, Kim Taehyung & exoNo ratings yet
- Buffer 2Document5 pagesBuffer 2April Cruz100% (1)
- MATH22558 Final Project - Winter 2018Document4 pagesMATH22558 Final Project - Winter 2018HardilazizNo ratings yet
- Continuity and DifferentiabilityDocument5 pagesContinuity and DifferentiabilitySurya Pratap SinghNo ratings yet
- CalcIII LectureWorkbook2020Document313 pagesCalcIII LectureWorkbook2020Nyannue FlomoNo ratings yet
- Basic Terms/Concepts IN Analytical ChemistryDocument53 pagesBasic Terms/Concepts IN Analytical ChemistrySheralyn PelayoNo ratings yet
- Today:: + Cos + Sin ,:, Arg Arg + Arg +Document20 pagesToday:: + Cos + Sin ,:, Arg Arg + Arg +IbrahimNo ratings yet
- Lecture 5: Overview of Numerical Methods (Cont'd)Document17 pagesLecture 5: Overview of Numerical Methods (Cont'd)Anonymous ueh2VMT5GNo ratings yet
- ODEs Modern Perspective Ebook 2003Document271 pagesODEs Modern Perspective Ebook 2003Hanan AltousNo ratings yet
- Operations ManagementDocument18 pagesOperations Managementliz_jc2No ratings yet
- Potentiometric TitrationDocument12 pagesPotentiometric TitrationTien Haminh100% (1)
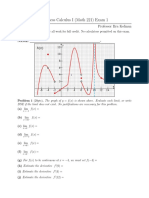
- Business Calculus I (Math 221) Exam 1: September 28, 2016 Professor Ilya KofmanDocument6 pagesBusiness Calculus I (Math 221) Exam 1: September 28, 2016 Professor Ilya KofmanFernando Lipardo Jr.No ratings yet
- Economic Load Dispatch Solution Neglecting LossesDocument21 pagesEconomic Load Dispatch Solution Neglecting LossesRAJESH ROYNo ratings yet
- Integral Calculus for Beginners ExplainedDocument304 pagesIntegral Calculus for Beginners ExplainedJhon Ray OtañesNo ratings yet