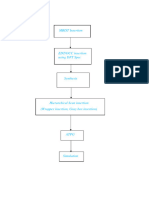
You might also like
- Two-Degree-of-Freedom Control Systems: The Youla Parameterization ApproachFrom EverandTwo-Degree-of-Freedom Control Systems: The Youla Parameterization ApproachNo ratings yet
- 4.2 Estimation of Absolute PerformanceDocument42 pages4.2 Estimation of Absolute PerformanceAnsh GanatraNo ratings yet
- Performance Evaluation of Computer Systems and Networks: SimulationDocument43 pagesPerformance Evaluation of Computer Systems and Networks: SimulationMedNo ratings yet
- 10 - Chapter 6 Statistical Analysis of Output From Terminating SimulationsDocument46 pages10 - Chapter 6 Statistical Analysis of Output From Terminating SimulationsAdriana GarciaNo ratings yet
- שפות סימולציה- הרצאה 13 - Output Data Analysis IIDocument48 pagesשפות סימולציה- הרצאה 13 - Output Data Analysis IIRonNo ratings yet
- 9 - Traffic Simulation ModelDocument11 pages9 - Traffic Simulation ModelDr. Ir. R. Didin Kusdian, MT.No ratings yet
- Analysis and statistical techniques for output from discrete event simulationsDocument7 pagesAnalysis and statistical techniques for output from discrete event simulationsShanjuJossiahNo ratings yet
- BIT 2212: Business Systems Modeling: Statistical InferenceDocument24 pagesBIT 2212: Business Systems Modeling: Statistical Inferencebeldon musauNo ratings yet
- Chapter 11Document35 pagesChapter 11derbew2112No ratings yet
- Simulation and Modelling: Chapter FourDocument19 pagesSimulation and Modelling: Chapter FourLet’s Talk TechNo ratings yet
- A Data-Driven Model For Software Reliability PredictionDocument32 pagesA Data-Driven Model For Software Reliability Predictionsleepanon4362No ratings yet
- Parte BDocument29 pagesParte Brenato otaniNo ratings yet
- MATLAB BasicDocument25 pagesMATLAB BasicAalu YadavNo ratings yet
- M&S 05 Output Data AnalysisDocument27 pagesM&S 05 Output Data AnalysisFelipe Vásquez MinayaNo ratings yet
- Books and resources for simulation and modelling courseDocument35 pagesBooks and resources for simulation and modelling courseuseless007No ratings yet
- 4.1 - Analysis Based On Transfer FunctionDocument56 pages4.1 - Analysis Based On Transfer FunctionMarceloNo ratings yet
- Simulation in Terminated SystemsDocument17 pagesSimulation in Terminated SystemsSaleem AlmaqashiNo ratings yet
- Digital Electronics Lab Manual: Prepared byDocument48 pagesDigital Electronics Lab Manual: Prepared bysomesh chandrakarNo ratings yet
- SSM Notes) - 132-149Document18 pagesSSM Notes) - 132-149Akansha JainNo ratings yet
- Modeling and Simulation of C&C NetworkDocument34 pagesModeling and Simulation of C&C NetworkMahamod IsmailNo ratings yet
- Algrothim Analysis: Time and Space ComplexityDocument28 pagesAlgrothim Analysis: Time and Space ComplexityOlawale SeunNo ratings yet
- Modeling Detailed OperationsDocument15 pagesModeling Detailed OperationsEunice AkwareNo ratings yet
- TSNotes 2Document28 pagesTSNotes 2YANGYUXINNo ratings yet
- Lecture - L5 - Time Series ECMDocument28 pagesLecture - L5 - Time Series ECMJaka PratamaNo ratings yet
- Recent Advances in Trade Theory and Policy Analysis Using Micro-Level DataDocument26 pagesRecent Advances in Trade Theory and Policy Analysis Using Micro-Level DataGuivis ZeufackNo ratings yet
- Digital control engineering lecture on z-transform and samplingDocument13 pagesDigital control engineering lecture on z-transform and samplingjin kazamaNo ratings yet
- Generacion de Pseudo NumerosDocument19 pagesGeneracion de Pseudo Numerosnicoletto8No ratings yet
- Digital Signal Processing - Chapter 7: Sampling TheoryDocument16 pagesDigital Signal Processing - Chapter 7: Sampling TheorymarwaNo ratings yet
- From Raw Eeg Data To Erp: Eva A.M. Van Poppel, MSCDocument30 pagesFrom Raw Eeg Data To Erp: Eva A.M. Van Poppel, MSCAbhinandan ChatterjeeNo ratings yet
- Chapitre 6 SimulationDocument32 pagesChapitre 6 Simulationcyrine khbouNo ratings yet
- Chapter 11 Output Analysis for a Single ModelDocument45 pagesChapter 11 Output Analysis for a Single ModelRaviteja MeesalaNo ratings yet
- Week 6aDocument15 pagesWeek 6ahairen jegerNo ratings yet
- CSCE626 Amato LN PerformanceAnalysisMethodologyDocument19 pagesCSCE626 Amato LN PerformanceAnalysisMethodologyRaj Kumar YadavNo ratings yet
- Digital Control System ModellingDocument28 pagesDigital Control System ModellingSonam AlviNo ratings yet
- 03 Models Z-TransformDocument55 pages03 Models Z-TransformaliNo ratings yet
- Maintenance Engineering 5Document38 pagesMaintenance Engineering 5Suienish SultangazinNo ratings yet
- Real-Time Scheduling of Periodic Tasks (1) : Advanced Operating SystemsDocument17 pagesReal-Time Scheduling of Periodic Tasks (1) : Advanced Operating SystemsNikita KukrejaNo ratings yet
- Output AnalysisDocument55 pagesOutput AnalysisFelipe Vásquez MinayaNo ratings yet
- Lumped Parameter Model AnalysisDocument20 pagesLumped Parameter Model AnalysisTezoquitl PantliNo ratings yet
- Continuous Random Variables and Their PropertiesDocument91 pagesContinuous Random Variables and Their PropertiesJeff HardyNo ratings yet
- Verilog Code for Frequency Division and FSMDocument40 pagesVerilog Code for Frequency Division and FSMYogesh TiwariNo ratings yet
- Development of Empirical Models From Process Data: - An Attractive AlternativeDocument10 pagesDevelopment of Empirical Models From Process Data: - An Attractive Alternative李承家No ratings yet
- WEEK 7 MODULE 7 - Analysis of Discrete Systems2Document49 pagesWEEK 7 MODULE 7 - Analysis of Discrete Systems2Adekoya IfeoluwaNo ratings yet
- Simulation and Modeling. Part 3Document11 pagesSimulation and Modeling. Part 3kaxapoNo ratings yet
- 5.g 129 - Oscillation Based Analog Testing - A Case StudyDocument6 pages5.g 129 - Oscillation Based Analog Testing - A Case StudyVančo LitovskiNo ratings yet
- ACFDocument27 pagesACFAnand SatsangiNo ratings yet
- Determination of Grinding Rate Constant of Lakan Lead and Zinc DepositDocument4 pagesDetermination of Grinding Rate Constant of Lakan Lead and Zinc DepositminingnovaNo ratings yet
- DFT DocumentationDocument20 pagesDFT Documentationyamini100% (1)
- Lecture 4 Estimation SummaryDocument70 pagesLecture 4 Estimation SummaryNegar AkbarzadehNo ratings yet
- Univariate Time SeriesDocument132 pagesUnivariate Time SeriesWesley Miller Perez OrtizNo ratings yet
- Stochastic Modeling For Random Testing Dvcon2009 Final 9009 NewDocument23 pagesStochastic Modeling For Random Testing Dvcon2009 Final 9009 NewvictorbesNo ratings yet
- ENG-PST Lecture2Document25 pagesENG-PST Lecture2Abdulrahman AlhomsiNo ratings yet
- Experimental DesignDocument47 pagesExperimental DesignHamiduNo ratings yet
- M ErginSahinDocument9 pagesM ErginSahinbbb bbbNo ratings yet
- Link Delay: - Processing Delay - Queuing Delay - Transmission Delay - Propagation DelayDocument53 pagesLink Delay: - Processing Delay - Queuing Delay - Transmission Delay - Propagation DelayKetki SawantNo ratings yet
- BE (Computer Systems) Spring 2022 Semester: Types of SimulationsDocument9 pagesBE (Computer Systems) Spring 2022 Semester: Types of SimulationsZubia FNo ratings yet
- Lecture 3. Growth of Functions Asymptotic NotationDocument9 pagesLecture 3. Growth of Functions Asymptotic NotationJasdeep Singh Pardeep SinghNo ratings yet
- Original 2Document15 pagesOriginal 2Ahmed Mohammed KebaishNo ratings yet
- ET4060 Fundamentals of Data Communication Networks: Queueing TheoryDocument26 pagesET4060 Fundamentals of Data Communication Networks: Queueing TheoryLoc DoNo ratings yet
- 06 Random Number GenerationDocument57 pages06 Random Number Generationsaruji_sanNo ratings yet
- 10 Verification and Validation of Simulation ModelsDocument32 pages10 Verification and Validation of Simulation Modelssaruji_sanNo ratings yet
- Discuss The 4 Keys To Staying Committed in A RelationshipDocument2 pagesDiscuss The 4 Keys To Staying Committed in A Relationshipsaruji_sanNo ratings yet
- Generate Random Variables Using Inverse TransformDocument44 pagesGenerate Random Variables Using Inverse Transformsaruji_sanNo ratings yet
- 09 Input ModelingDocument60 pages09 Input Modelingsaruji_sanNo ratings yet
- The Magic of Small Spaces PDFDocument423 pagesThe Magic of Small Spaces PDFyoga muktaNo ratings yet
- Overall Equipment Effectiveness (OEE) at The Laboratory of Structure TestingDocument11 pagesOverall Equipment Effectiveness (OEE) at The Laboratory of Structure Testingsaruji_sanNo ratings yet
- HW 11Document1 pageHW 11saruji_sanNo ratings yet
- Bodenmann - Stress Sex and Satisfaction PDFDocument19 pagesBodenmann - Stress Sex and Satisfaction PDFsaruji_sanNo ratings yet
- TED Talks Marriage ECDocument1 pageTED Talks Marriage ECsaruji_sanNo ratings yet
- HW 11Document1 pageHW 11saruji_sanNo ratings yet
- Eng BTSDocument62 pagesEng BTSKamleshNo ratings yet
- Math 5760 /6890: Introduction To Mathematical Finance I Fall 2020 SyllabusDocument4 pagesMath 5760 /6890: Introduction To Mathematical Finance I Fall 2020 Syllabussaruji_sanNo ratings yet
- Final Review - Quality and Intimate RelationshipsDocument16 pagesFinal Review - Quality and Intimate Relationshipssaruji_sanNo ratings yet
- Changing Feelings by Changing ThoughtsDocument3 pagesChanging Feelings by Changing Thoughtssaruji_sanNo ratings yet
- HW 11Document1 pageHW 11saruji_sanNo ratings yet
- Lectures Notes Printout April 2015Document8 pagesLectures Notes Printout April 2015saruji_sanNo ratings yet
- Probability Final Exam With SolutionsDocument10 pagesProbability Final Exam With Solutionssaruji_sanNo ratings yet
- Chapter 5.2, Problem 8PDocument6 pagesChapter 5.2, Problem 8Psaruji_sanNo ratings yet
- Oriental Motors DG SeriesDocument48 pagesOriental Motors DG Seriessaruji_sanNo ratings yet
- BPTCh1 PDFDocument45 pagesBPTCh1 PDFsaruji_sanNo ratings yet
- Stanley J. Farlow, Mathematics Partial Differential Equations For Scientists and Engineers PDFDocument214 pagesStanley J. Farlow, Mathematics Partial Differential Equations For Scientists and Engineers PDFAndré Berninzon100% (1)
- Java 2D Arrays TutorialDocument2 pagesJava 2D Arrays Tutorialsaruji_sanNo ratings yet
- HW1Document1 pageHW1saruji_sanNo ratings yet
- Laplace ExamplesDocument13 pagesLaplace Examplessaruji_sanNo ratings yet
- Stanley J. Farlow, Mathematics Partial Differential Equations For Scientists and Engineers PDFDocument214 pagesStanley J. Farlow, Mathematics Partial Differential Equations For Scientists and Engineers PDFAndré Berninzon100% (1)
- 5510 Notes F17 V1Document119 pages5510 Notes F17 V1saruji_sanNo ratings yet
- Discrete Mathmatics Exam1 PracticeDocument6 pagesDiscrete Mathmatics Exam1 Practicesaruji_sanNo ratings yet
- Sergei Ivanov Lecture 7-9 #35Document1 pageSergei Ivanov Lecture 7-9 #35saruji_sanNo ratings yet
- DLL - Week - 10 - Statistics and ProbabilityDocument3 pagesDLL - Week - 10 - Statistics and ProbabilityRoboCopyNo ratings yet
- Test Bank For Business Analytics Data Analysis and Decision Making 7th Edition Albright DownloadDocument42 pagesTest Bank For Business Analytics Data Analysis and Decision Making 7th Edition Albright Downloadchristopherzimmermanezotawqcyn100% (25)
- Bayes-xG Player and Position Correction On Expected Goals (XG) Using Bayesian Hierarchical ApproachDocument28 pagesBayes-xG Player and Position Correction On Expected Goals (XG) Using Bayesian Hierarchical Approachamy.jieyu.wuNo ratings yet
- EDA Notebook 6 Estimation of Population MeanDocument13 pagesEDA Notebook 6 Estimation of Population MeanCarl Jason ColomaNo ratings yet
- Lecture 5-BEC 260Document28 pagesLecture 5-BEC 260Freddie NsamaNo ratings yet
- An Introduction To Probability and Statistics - 2015 - Rohatgi - ReferencesDocument5 pagesAn Introduction To Probability and Statistics - 2015 - Rohatgi - ReferencesThiyagarajan GanesanNo ratings yet
- Unit 2 Interval Estimation-1Document31 pagesUnit 2 Interval Estimation-1PetrinaNo ratings yet
- Statistics For Data Science PDF - Statistics-for-Data-Science PDFDocument14 pagesStatistics For Data Science PDF - Statistics-for-Data-Science PDFFaridNo ratings yet
- MCRS Partial Exam 1 - NotesDocument32 pagesMCRS Partial Exam 1 - Noteskasia swiderskaNo ratings yet
- Australasian Business Statistics 4Th Edition Black Test Bank Full Chapter PDFDocument47 pagesAustralasian Business Statistics 4Th Edition Black Test Bank Full Chapter PDFsarahpalmerotpdkjcwfq100% (13)
- From Alpha To Omega: A Practical Solution To The Pervasive Problem of Internal Consistency EstimationDocument14 pagesFrom Alpha To Omega: A Practical Solution To The Pervasive Problem of Internal Consistency EstimationLuis Angel Hernandez MirandaNo ratings yet
- ch08 9QNP PDFDocument23 pagesch08 9QNP PDFpink pinkNo ratings yet
- Applied Statistics and Probability For Engineers Chapter - 8Document13 pagesApplied Statistics and Probability For Engineers Chapter - 8MustafaNo ratings yet
- LESSON 5 STATISTICS & PROBABILITYDocument18 pagesLESSON 5 STATISTICS & PROBABILITYJayNo ratings yet
- Introduction to Statistical InferenceDocument20 pagesIntroduction to Statistical InferenceMar LagmayNo ratings yet
- V2 Exam 1 AMDocument30 pagesV2 Exam 1 AMNeerajNo ratings yet
- Unit 2 Statistical EstimationDocument15 pagesUnit 2 Statistical EstimationEbsa AdemeNo ratings yet
- 2020 Mock Exam C - Afternoon Session (With Solutions)Document62 pages2020 Mock Exam C - Afternoon Session (With Solutions)Tushar Gupta100% (1)
- Statistics and Probability 1Document2 pagesStatistics and Probability 1Maria Theresa OndoyNo ratings yet
- Chapter 9Document22 pagesChapter 9Yazan Abu khaledNo ratings yet
- Statistics 3Rd Edition Agresti Test Bank Full Chapter PDFDocument47 pagesStatistics 3Rd Edition Agresti Test Bank Full Chapter PDFleogreenetxig100% (7)
- LM05 Sampling and Estimation IFT NotesDocument16 pagesLM05 Sampling and Estimation IFT NotesTANGO mikeNo ratings yet
- 04-Estimation of ParametersDocument36 pages04-Estimation of ParametersJude MetanteNo ratings yet
- First Course in Statistics 12Th Edition Mcclave Test Bank Full Chapter PDFDocument52 pagesFirst Course in Statistics 12Th Edition Mcclave Test Bank Full Chapter PDFJamesOrtegapfcs100% (10)
- PPT Statistics New Syllabus - Part 2Document70 pagesPPT Statistics New Syllabus - Part 2Shubham TambeNo ratings yet
- Point Estimate of Population MeanDocument2 pagesPoint Estimate of Population MeanJeff LacasandileNo ratings yet
- MathGazine QADocument14 pagesMathGazine QAMarianne AdarayanNo ratings yet
- Statistics and Probability Tutorial Summer 2022Document29 pagesStatistics and Probability Tutorial Summer 2022ValentinNo ratings yet
- Statistics - Course-Notes-365-Data-ScienceDocument36 pagesStatistics - Course-Notes-365-Data-Scienceutkarsh PromotiomNo ratings yet
- 7 - Sampling Distributions & Point Estimation of ParametersDocument45 pages7 - Sampling Distributions & Point Estimation of Parameters65011536No ratings yet