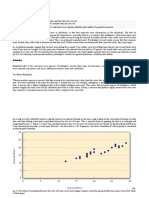
You might also like
- Course Data Analysis For Social Science Teachers Topic Module Id 1.3Document7 pagesCourse Data Analysis For Social Science Teachers Topic Module Id 1.3Abdul MohammadNo ratings yet
- Validity and ReliabilityDocument21 pagesValidity and ReliabilityKris Labios100% (1)
- Reliability and Validity of MeasurementDocument8 pagesReliability and Validity of MeasurementMian Adeel JeeNo ratings yet
- Reliability and Validity of Measurement: Learning ObjectivesDocument8 pagesReliability and Validity of Measurement: Learning ObjectivesToufik KoussaNo ratings yet
- Validity and Reliability: Rauf Ahmed (Bs 3 Year Morning) Research Methadology Assignment Submitted To Sir ShahanDocument6 pagesValidity and Reliability: Rauf Ahmed (Bs 3 Year Morning) Research Methadology Assignment Submitted To Sir ShahanMuhammad Umer FarooqNo ratings yet
- Module 3: Principles of Psychological Testing: Central Luzon State UniversityDocument14 pagesModule 3: Principles of Psychological Testing: Central Luzon State UniversityPATRICIA GOLTIAONo ratings yet
- Measurement ScalesDocument3 pagesMeasurement ScalesimadNo ratings yet
- TYPES OF DATA FOR QUANTITATIVE RESEARCHDocument38 pagesTYPES OF DATA FOR QUANTITATIVE RESEARCHpinoybsn26100% (1)
- Scaling TechniquesDocument29 pagesScaling TechniquesAnshika AroraNo ratings yet
- Scales of MeasurementDocument4 pagesScales of MeasurementRaye Pushpalatha67% (3)
- Interval ScaleDocument7 pagesInterval ScaleGilian PradoNo ratings yet
- Scale of MeasurementDocument5 pagesScale of MeasurementSTEPHY LANCYNo ratings yet
- Tem-515: Statistical Analyses With Computer Application: Lecture Series 1: Introduction To Data CollectionDocument37 pagesTem-515: Statistical Analyses With Computer Application: Lecture Series 1: Introduction To Data CollectionZC47No ratings yet
- M. Shah Jahan 100127 To SIR Farukh Gill (Task 2Document26 pagesM. Shah Jahan 100127 To SIR Farukh Gill (Task 2Roy JohnNo ratings yet
- Q.1 Describe Level of Measurement. Give Five Examples of Each Level and Explain The Role of Level of Measurement in Decision Making. Ans. Levels of MeasurementDocument27 pagesQ.1 Describe Level of Measurement. Give Five Examples of Each Level and Explain The Role of Level of Measurement in Decision Making. Ans. Levels of MeasurementashaNo ratings yet
- Statistical Analyses with Computer ApplicationsDocument32 pagesStatistical Analyses with Computer ApplicationsAdnan100% (1)
- Resumen - Escalas de MediciónDocument2 pagesResumen - Escalas de MediciónZAMORA GUERRERO RAFAELNo ratings yet
- TYPES OF DATA Bhs InggrisDocument3 pagesTYPES OF DATA Bhs InggrisCristian Totti Roniasi PangaribuanNo ratings yet
- Types of ScalesDocument8 pagesTypes of ScalesBahrouniNo ratings yet
- Norm-Referenced InstrumentsDocument10 pagesNorm-Referenced InstrumentsRatiey Sidraa100% (1)
- Chapter 1Document21 pagesChapter 1MoshiMoshi ChannelNo ratings yet
- Course PresentationDocument31 pagesCourse PresentationUpendra D.C.No ratings yet
- Essentials of A Good TestDocument6 pagesEssentials of A Good TestdanypereztNo ratings yet
- RESEARCH methedologyDocument21 pagesRESEARCH methedologyRavin SangwanNo ratings yet
- Review Notes Assessment of LearningDocument12 pagesReview Notes Assessment of LearningJohn Patrick CacatianNo ratings yet
- ResearchDocument44 pagesResearchAsif SaeedNo ratings yet
- 03 Measure 4thDocument8 pages03 Measure 4thSantai SajaNo ratings yet
- Levels of Measurement: Nominal, Ordinal, Interval, RatioDocument3 pagesLevels of Measurement: Nominal, Ordinal, Interval, RatioJasmine Morante AntonioNo ratings yet
- Kinds of Statistics and Types of DataDocument4 pagesKinds of Statistics and Types of DataNeatTater100% (1)
- 3business Research UNIT 3Document20 pages3business Research UNIT 3Swati MishraNo ratings yet
- Unit 7Document19 pagesUnit 7Susshmita UpadhayaNo ratings yet
- Reliability PDFDocument5 pagesReliability PDFbushra khanNo ratings yet
- Likert ScaleDocument8 pagesLikert ScaleNeelam ShuklaNo ratings yet
- Measurement in ResearchDocument8 pagesMeasurement in ResearchAF Ann RossNo ratings yet
- Essentials of A Good Psychological TestDocument6 pagesEssentials of A Good Psychological Testmguerrero1001No ratings yet
- Understanding Statistics: A Guide to Descriptive, Inferential, and Research MethodsDocument6 pagesUnderstanding Statistics: A Guide to Descriptive, Inferential, and Research MethodsSerenaNo ratings yet
- Chapter Nine Measurement and Scaling: Noncomparative Scaling TechniquesDocument6 pagesChapter Nine Measurement and Scaling: Noncomparative Scaling TechniquesInuri AnthonisNo ratings yet
- Measuring and Scaling of Quantitative Data: UNIT - IIIDocument28 pagesMeasuring and Scaling of Quantitative Data: UNIT - IIIVenu GopalNo ratings yet
- ScalingDocument12 pagesScalinggsampathNo ratings yet
- Psychmet 2atekhayeDocument8 pagesPsychmet 2atekhayeCherie Faye EstacioNo ratings yet
- Module 3 - Statistics RefresherDocument16 pagesModule 3 - Statistics RefresherTapia, DarleenNo ratings yet
- Reliability and Validity of Psychological TestsDocument29 pagesReliability and Validity of Psychological TestsR-wah LarounetteNo ratings yet
- Correlation and ANOVA TechniquesDocument6 pagesCorrelation and ANOVA TechniquesHans Christer RiveraNo ratings yet
- Field Methods - NotesDocument12 pagesField Methods - NotesangeliquefaithemnaceNo ratings yet
- 1.2the Nature of Sta & ProbaDocument25 pages1.2the Nature of Sta & ProbaMichaela Mae MarcaidaNo ratings yet
- Hi in This Video I Will Help You ChooseDocument7 pagesHi in This Video I Will Help You ChooseMixx MineNo ratings yet
- Test Validity and ReabilityDocument11 pagesTest Validity and ReabilityRamareziel Parreñas RamaNo ratings yet
- Ch3 - Measurement in ResearchDocument34 pagesCh3 - Measurement in Researchshagun.2224mba1003No ratings yet
- Research Designs and Variables GuideDocument30 pagesResearch Designs and Variables GuidefarahisNo ratings yet
- Measurement and Scaling ConceptDocument20 pagesMeasurement and Scaling ConceptVãńšh WädhwåNo ratings yet
- Reliability and ValidityDocument49 pagesReliability and ValidityDrAkhilesh SharmaNo ratings yet
- Islamic Values: o o o o o o o o o o o o o o o oDocument10 pagesIslamic Values: o o o o o o o o o o o o o o o oMitesh GandhiNo ratings yet
- Ale - Assignment 1Document2 pagesAle - Assignment 1ale.cristianNo ratings yet
- Scales of MeasurementDocument15 pagesScales of MeasurementRaziChughtaiNo ratings yet
- Lesson 5 Levels of Measurement - signedDBADocument9 pagesLesson 5 Levels of Measurement - signedDBALord sandell SequenaNo ratings yet
- PTT ResearchDocument98 pagesPTT ResearchTri Sasmito HarjonoNo ratings yet
- Quantitative Research Design and MethodsDocument35 pagesQuantitative Research Design and MethodskundagolNo ratings yet
- ID 14 (Measurement)Document6 pagesID 14 (Measurement)Md Abubokkor SiddikNo ratings yet
- NP 1Document12 pagesNP 1Soumya BullaNo ratings yet
- CRYSTALLOGRAPHY TECHNIQUESDocument36 pagesCRYSTALLOGRAPHY TECHNIQUESSoumya BullaNo ratings yet
- Biological Spectroscopy: (In VivoDocument1 pageBiological Spectroscopy: (In VivoSoumya BullaNo ratings yet
- Introduction To Spectroscopy: LiteratureDocument37 pagesIntroduction To Spectroscopy: LiteratureYahya RajputNo ratings yet
- Introduction To Quantum Mechanics: Department of Studies in Physics Davangere University, DavangereDocument6 pagesIntroduction To Quantum Mechanics: Department of Studies in Physics Davangere University, DavangereSoumya BullaNo ratings yet
- Author's Accepted Manuscript: Materials LettersDocument9 pagesAuthor's Accepted Manuscript: Materials LettersSoumya BullaNo ratings yet
- Optical and Electrical Studies of Polyaniline/Zno NanocompositeDocument7 pagesOptical and Electrical Studies of Polyaniline/Zno NanocompositeSoumya BullaNo ratings yet
- Information For Business CardDocument8 pagesInformation For Business CardHailay WeldegebrielNo ratings yet
- Templates of Field Instruction 2 RequirementsDocument21 pagesTemplates of Field Instruction 2 RequirementsEmily MaloloyonNo ratings yet
- Integrating CBMS in The CDP ProcessDocument18 pagesIntegrating CBMS in The CDP ProcessMPDC AringayNo ratings yet
- Observation MethodDocument7 pagesObservation Methodhumna naeemNo ratings yet
- Crystal M. Cartwright Leadership Philosphy Leadership Competency Project October FINAL 2 PDFDocument17 pagesCrystal M. Cartwright Leadership Philosphy Leadership Competency Project October FINAL 2 PDFcrystal cartwrightNo ratings yet
- Mccall 1986Document4 pagesMccall 1986Ivan FirmandaNo ratings yet
- The Complexity Scale: A Routine Creating Multi-Dimensional Mental ModelsDocument1 pageThe Complexity Scale: A Routine Creating Multi-Dimensional Mental ModelsMarianela FabroNo ratings yet
- South-South Dialogues on DecolonizationDocument112 pagesSouth-South Dialogues on DecolonizationsaschamiguelNo ratings yet
- Philosophical Foundations of Qualitative ResearchDocument2 pagesPhilosophical Foundations of Qualitative ResearchAdam LimbumbaNo ratings yet
- Apeejay School, Pitampura: Datesheet For Periodic Test - 1 SESSION - 2022 - 2023Document1 pageApeejay School, Pitampura: Datesheet For Periodic Test - 1 SESSION - 2022 - 2023HOPSCOTCH KIDSNo ratings yet
- Prefects HandbookDocument9 pagesPrefects HandbookPrince NaytsanzaNo ratings yet
- Hooker & Little 2001 Moral ParticularismDocument332 pagesHooker & Little 2001 Moral ParticularismCristóbal AstorgaNo ratings yet
- 1.a Sears 2015. Del Pensamiento Cientifico A La Teoria SocialDocument15 pages1.a Sears 2015. Del Pensamiento Cientifico A La Teoria SocialMati AmezcuaNo ratings yet
- Volker, S. Developing Urban Blue Health ResponsesDocument10 pagesVolker, S. Developing Urban Blue Health ResponsesCatarina FreitasNo ratings yet
- Theory of Knowledge Guide: Prepared By: Maria Fe Nicolau, PH.DDocument32 pagesTheory of Knowledge Guide: Prepared By: Maria Fe Nicolau, PH.DTasya RuswanNo ratings yet
- Karen Weixel-Dixon - Existential Group Counselling and Psychotherapy-Routledge (2020)Document186 pagesKaren Weixel-Dixon - Existential Group Counselling and Psychotherapy-Routledge (2020)Marcel NitanNo ratings yet
- FULL Download Ebook PDF Human Geography Places and Regions in Global Context 7th Edition PDF EbookDocument41 pagesFULL Download Ebook PDF Human Geography Places and Regions in Global Context 7th Edition PDF Ebookarthur.mattingly873100% (30)
- Superhuman Eye Contact Training - How To Radiate Confidence, Attract Others, and Demand Respect With Just Your Eyes (PDFDrive)Document50 pagesSuperhuman Eye Contact Training - How To Radiate Confidence, Attract Others, and Demand Respect With Just Your Eyes (PDFDrive)Al XavierNo ratings yet
- Peyton James-Bradford - Final Draft Essay 2 - Room For Debate - 3824896Document4 pagesPeyton James-Bradford - Final Draft Essay 2 - Room For Debate - 3824896api-614445822No ratings yet
- Adriana Cavarero Feminist PhilosophyDocument6 pagesAdriana Cavarero Feminist PhilosophybesciamellaNo ratings yet
- BSWE-001/2019-20 Introduction To Social Work 1) Discuss Social Justice and Social Policy As Social Work Concepts. 20Document13 pagesBSWE-001/2019-20 Introduction To Social Work 1) Discuss Social Justice and Social Policy As Social Work Concepts. 20ok okNo ratings yet
- Importance of Effective Communication in Interpersonal RelationshipsDocument12 pagesImportance of Effective Communication in Interpersonal RelationshipsThe Shining100% (1)
- The Spiritual Meaning of the OhikariDocument2 pagesThe Spiritual Meaning of the Ohikarinutimarin1998No ratings yet
- Fcomp-05-1210421-From Fear To Action AI Governance and Opportunities For AllDocument4 pagesFcomp-05-1210421-From Fear To Action AI Governance and Opportunities For AllfherreraugrNo ratings yet
- Contemporary Philosophy Primary Bearers Truth Belief Propositional Attitudes Referents Meanings SentencesDocument4 pagesContemporary Philosophy Primary Bearers Truth Belief Propositional Attitudes Referents Meanings SentencesMalote Elimanco AlabaNo ratings yet
- PMT Report PresentationDocument25 pagesPMT Report PresentationMitch Shyrelle BaclaoNo ratings yet
- CBNRMDocument7 pagesCBNRMFarisi TarwiraNo ratings yet
- Semiotic: Sign LanguageDocument19 pagesSemiotic: Sign LanguageAlyiah Zhalel LawasNo ratings yet
- 5280 Home - Jun & Jul 2021Document104 pages5280 Home - Jun & Jul 2021Dan In-marNo ratings yet