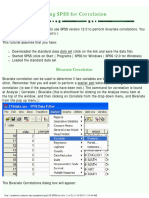
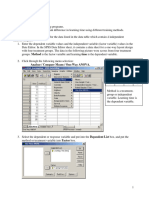
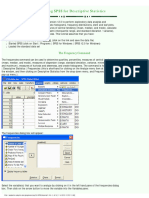
You might also like
- Notes5b TwosamplesttestDocument28 pagesNotes5b TwosamplesttestNazia SyedNo ratings yet
- ANOVADocument6 pagesANOVAmisganabbbbbbbbbbNo ratings yet
- L7 Hypothesis TestingDocument59 pagesL7 Hypothesis Testingمصطفى سامي شهيد لفتهNo ratings yet
- Independent Samples T TestDocument19 pagesIndependent Samples T TestKimesha BrownNo ratings yet
- Independent Samples T Test (LECTURE)Document10 pagesIndependent Samples T Test (LECTURE)Max SantosNo ratings yet
- Spss Tutorials: Independent Samples T TestDocument13 pagesSpss Tutorials: Independent Samples T TestMat3xNo ratings yet
- Student S T Statistic: Test For Equality of Two Means Test For Value of A Single MeanDocument35 pagesStudent S T Statistic: Test For Equality of Two Means Test For Value of A Single MeanAmaal GhaziNo ratings yet
- Mittal School of BusinessDocument9 pagesMittal School of Businessfae salNo ratings yet
- Section#7Document8 pagesSection#7Ahmed AlaaNo ratings yet
- Ch6 - Hypothesis TestingDocument31 pagesCh6 - Hypothesis Testingshagun.2224mba1003No ratings yet
- What Is A TDocument5 pagesWhat Is A TkamransNo ratings yet
- SM 38Document58 pagesSM 38ayushNo ratings yet
- Univariate Statistics: Statistical Inference: Testing HypothesisDocument28 pagesUnivariate Statistics: Statistical Inference: Testing HypothesisEyasu DestaNo ratings yet
- 123 T F Z Chi Test 2Document5 pages123 T F Z Chi Test 2izzyguyNo ratings yet
- T-Test For Uncorrelated Samples: Presented By: Mark Nelson Adrian Dela Cruz Kim David A. AbuqueDocument13 pagesT-Test For Uncorrelated Samples: Presented By: Mark Nelson Adrian Dela Cruz Kim David A. AbuqueNel zyNo ratings yet
- Chapter 19 Main TopicsDocument6 pagesChapter 19 Main TopicsAnusha IllukkumburaNo ratings yet
- L 13, Independent Samples T TestDocument16 pagesL 13, Independent Samples T TestShan AliNo ratings yet
- Assignment Date: 4 November, 2015: What Is ANOVA?Document9 pagesAssignment Date: 4 November, 2015: What Is ANOVA?ANo ratings yet
- Biostat - Group 3Document42 pagesBiostat - Group 3Jasmin JimenezNo ratings yet
- Two Sample T TestDocument8 pagesTwo Sample T TestjakejakeNo ratings yet
- Making Decisions For The Difference Between Two Independent Population MeansDocument10 pagesMaking Decisions For The Difference Between Two Independent Population MeansArnold ArceoNo ratings yet
- Lecture 12 - T-Test IDocument33 pagesLecture 12 - T-Test Iamedeuce lyatuuNo ratings yet
- Stats Hypothesis TestingDocument3 pagesStats Hypothesis TestingLiana BaluyotNo ratings yet
- Isds361b NotesDocument103 pagesIsds361b NotesHa NgoNo ratings yet
- Session 09Document6 pagesSession 09Osman Gani TalukderNo ratings yet
- Chapter 7 Class Notes Comparison of Two Independent Samples: Introduction To BiostatisticsDocument18 pagesChapter 7 Class Notes Comparison of Two Independent Samples: Introduction To BiostatisticsClaire NakilaNo ratings yet
- Hypothesis Testing - Means and VariancesDocument11 pagesHypothesis Testing - Means and VariancesJina Joan DcruzNo ratings yet
- Chapter10 StatsDocument7 pagesChapter10 StatsPoonam NaiduNo ratings yet
- Chapter 13Document8 pagesChapter 13allyssa orobiaNo ratings yet
- LU 6 Mean ComparisonDocument73 pagesLU 6 Mean ComparisonKristhel Jane Roxas NicdaoNo ratings yet
- Topic 4B. Inferential StatisticsDocument45 pagesTopic 4B. Inferential StatisticsYousou DIAGNENo ratings yet
- Topic 4B. Inferential StatisticsDocument45 pagesTopic 4B. Inferential StatisticsMirjeta ZymeriNo ratings yet
- Hypothesis Testing Vince ReganzDocument9 pagesHypothesis Testing Vince ReganzVince Edward RegañonNo ratings yet
- Unit 4 - Inference For Numerical Variables: Suggested Reading: Openintro Statistics, Suggested ExercisesDocument4 pagesUnit 4 - Inference For Numerical Variables: Suggested Reading: Openintro Statistics, Suggested ExercisesPuthpura PuthNo ratings yet
- Rank Biserial CorrelationDocument3 pagesRank Biserial Correlationryanosleep100% (1)
- Expi Psych Chapter 14-16Document9 pagesExpi Psych Chapter 14-16Morish Roi YacasNo ratings yet
- Compare Means: 1-One Sample T TestDocument18 pagesCompare Means: 1-One Sample T Testbzhar osmanNo ratings yet
- Design Based Upon Intraclass Correlation CoefficientDocument8 pagesDesign Based Upon Intraclass Correlation CoefficienthelgiarnoldNo ratings yet
- CRJ 503 PARAMETRIC TESTS DifferencesDocument10 pagesCRJ 503 PARAMETRIC TESTS DifferencesWilfredo De la cruz jr.No ratings yet
- Session 10Document10 pagesSession 10Osman Gani TalukderNo ratings yet
- Chi-Square Test: Advance StatisticsDocument26 pagesChi-Square Test: Advance StatisticsRobert Carl GarciaNo ratings yet
- Econ 335 Wooldridge CH 4Document29 pagesEcon 335 Wooldridge CH 4minhly12104No ratings yet
- The ChiDocument5 pagesThe Chikassa mnilkNo ratings yet
- Anova BiometryDocument33 pagesAnova Biometryadityanarang147No ratings yet
- Estimation and Hypothesis Testing: Two Populations (PART 1)Document46 pagesEstimation and Hypothesis Testing: Two Populations (PART 1)Sami Un BashirNo ratings yet
- Hypothesis TestingDocument38 pagesHypothesis TestingImran Ahmad SajidNo ratings yet
- qm2 NotesDocument9 pagesqm2 NotesdeltathebestNo ratings yet
- Analysis of Variance: - One-Way ANOVA - Two-Way ANOVADocument36 pagesAnalysis of Variance: - One-Way ANOVA - Two-Way ANOVAc3353359No ratings yet
- QTDocument16 pagesQTJainam ShahNo ratings yet
- Hypothesis TestingDocument39 pagesHypothesis TestingJames De Torres CarilloNo ratings yet
- Analyzing and InterpretingDocument18 pagesAnalyzing and InterpretingAeniNo ratings yet
- Unit 5 MTH302Document53 pagesUnit 5 MTH302Rohit KumarNo ratings yet
- Instalinotes - PREVMED IIDocument24 pagesInstalinotes - PREVMED IIKenneth Cuballes100% (1)
- Q.1 What Do You Know About? An Independent Sample T-Test. and A Paired Sample T-TestDocument12 pagesQ.1 What Do You Know About? An Independent Sample T-Test. and A Paired Sample T-TestSajawal ManzoorNo ratings yet
- 6 - Nonparametric TestsDocument10 pages6 - Nonparametric TestsThanhTuyenNguyenNo ratings yet
- BE.104 Spring Biostatistics: Detecting Differences and Correlations J. L. SherleyDocument9 pagesBE.104 Spring Biostatistics: Detecting Differences and Correlations J. L. Sherleyaleko100% (2)
- Chapter 5 (Part Ii)Document20 pagesChapter 5 (Part Ii)Natasha GhazaliNo ratings yet
- Related Topics/headings: Categorical Data Analysis Or, Nonparametric Statistics Or, Chi-SquareDocument17 pagesRelated Topics/headings: Categorical Data Analysis Or, Nonparametric Statistics Or, Chi-Squarebt2014No ratings yet
- Summary - Non - Parametric TestsDocument24 pagesSummary - Non - Parametric TestsSurvey_easyNo ratings yet
- 1 Correlation BDocument3 pages1 Correlation BNazia SyedNo ratings yet
- Edur 8131 Notes 5 T TestDocument23 pagesEdur 8131 Notes 5 T TestNazia SyedNo ratings yet
- 0 T-Tests ADocument17 pages0 T-Tests ANazia SyedNo ratings yet
- 0 Data Entry ADocument7 pages0 Data Entry ANazia SyedNo ratings yet
- 0 Correlation ADocument5 pages0 Correlation ANazia SyedNo ratings yet
- 0 Data Entry BDocument5 pages0 Data Entry BNazia SyedNo ratings yet
- Edur 8131 Notes 7 Chi SquareDocument16 pagesEdur 8131 Notes 7 Chi SquareNazia SyedNo ratings yet
- 0 Regression ADocument9 pages0 Regression ANazia SyedNo ratings yet
- SPSSChapter 8Document8 pagesSPSSChapter 8Syeda Sehrish KiranNo ratings yet
- 1 Frequencies BDocument3 pages1 Frequencies BNazia SyedNo ratings yet
- Edur 8131 Notes 2 Normal Standard ScoresDocument9 pagesEdur 8131 Notes 2 Normal Standard ScoresNazia SyedNo ratings yet
- Edur 8131 Notes 3 Statistical InferenceDocument9 pagesEdur 8131 Notes 3 Statistical InferenceNazia SyedNo ratings yet
- 0 Anova Oneway ADocument10 pages0 Anova Oneway ANazia SyedNo ratings yet
- EDUR8132 IntroductoryNotes 17august2010Document5 pagesEDUR8132 IntroductoryNotes 17august2010Nazia SyedNo ratings yet
- Correlation CoefficientsDocument9 pagesCorrelation CoefficientsNazia SyedNo ratings yet
- EDUR8132 IntroductoryNotesDocument6 pagesEDUR8132 IntroductoryNotesNazia SyedNo ratings yet
- Edur 8131 Notes 6 CorrelationDocument25 pagesEdur 8131 Notes 6 CorrelationNazia SyedNo ratings yet
- 1 Stemleaf CDocument3 pages1 Stemleaf CNazia SyedNo ratings yet
- 1 Graphs CDocument30 pages1 Graphs CNazia SyedNo ratings yet
- 1 Anova Oneway BDocument3 pages1 Anova Oneway BNazia SyedNo ratings yet
- Homework 2 Correlated Ttests AnswersDocument2 pagesHomework 2 Correlated Ttests AnswersNazia SyedNo ratings yet
- Edur 8131 Notes 4 (Revised) Hypothesis Testing and One Sample Z TestDocument16 pagesEdur 8131 Notes 4 (Revised) Hypothesis Testing and One Sample Z TestNazia SyedNo ratings yet
- Correlated Samples T-Test ExerciseDocument2 pagesCorrelated Samples T-Test ExerciseNazia SyedNo ratings yet
- Edur 8131 Graphical Display ExamplesDocument9 pagesEdur 8131 Graphical Display ExamplesNazia SyedNo ratings yet
- EDUR 8131 Notes 8a Simple RegressionDocument19 pagesEDUR 8131 Notes 8a Simple RegressionNazia SyedNo ratings yet
- Fraas Johnson Neyman Interaction ProcedureDocument11 pagesFraas Johnson Neyman Interaction ProcedureNazia SyedNo ratings yet
- 1 Frequencies ADocument8 pages1 Frequencies ANazia SyedNo ratings yet
- Chi Square ExerciseDocument5 pagesChi Square ExerciseNazia SyedNo ratings yet
- HypothesesDocument11 pagesHypothesesNazia SyedNo ratings yet
- EDUR 8131 Notes 8b Multiple RegressionDocument16 pagesEDUR 8131 Notes 8b Multiple RegressionNazia SyedNo ratings yet
- Chem Sem 2 Unit 1 LAB Pennies PDFDocument5 pagesChem Sem 2 Unit 1 LAB Pennies PDFCharles CaoNo ratings yet
- QraDocument10 pagesQraNakkolopNo ratings yet
- Data Science Methodologies: Current Challenges and Future ApproachesDocument22 pagesData Science Methodologies: Current Challenges and Future ApproachesNIKHIL WAKODENo ratings yet
- Chapter 1 Introduction To Quantitative AnalysisDocument12 pagesChapter 1 Introduction To Quantitative AnalysisGeorge VictorNo ratings yet
- Discriminant AnalysisDocument7 pagesDiscriminant AnalysisHisham ElhadidiNo ratings yet
- TFN Martha RogersDocument27 pagesTFN Martha RogersCamporedondo, Jessa D.No ratings yet
- Research CH 1..2Document20 pagesResearch CH 1..2Ermias AtalayNo ratings yet
- Fingerprints Scientific MethodDocument3 pagesFingerprints Scientific MethodricardoNo ratings yet
- Pictorial To Orthographic ExercisesDocument7 pagesPictorial To Orthographic ExercisesSaumyaNo ratings yet
- Metrology & SQC - NewDocument4 pagesMetrology & SQC - NewKashif RazaqNo ratings yet
- Merits and Demerits of Arithemetic MeanDocument10 pagesMerits and Demerits of Arithemetic Meantarun86% (7)
- M1GN1Document2 pagesM1GN1isabelNo ratings yet
- Econometrics moduleIIDocument114 pagesEconometrics moduleIIMegbaru100% (2)
- Isnatin Skripsi Upload Repository 9 20Document12 pagesIsnatin Skripsi Upload Repository 9 20Isnatin Nur Hidayah TBI 3BNo ratings yet
- Confidence IntervalsDocument50 pagesConfidence IntervalswedjefdbenmcveNo ratings yet
- Binomial Probability DistributionDocument17 pagesBinomial Probability Distributionsanjay reddyNo ratings yet
- Introduction To JurisprudenceDocument14 pagesIntroduction To JurisprudenceYash SinghNo ratings yet
- Brahmavarchas' Scientific Research of Spiritual SciencesDocument78 pagesBrahmavarchas' Scientific Research of Spiritual SciencesNikki*100% (1)
- Practice Mathematical and Statistical Problems Relevant To Breath and Blood Alcohol Testing ProgramsDocument18 pagesPractice Mathematical and Statistical Problems Relevant To Breath and Blood Alcohol Testing ProgramsBrko BrkoskiNo ratings yet
- Scientific Method Grade 8Document15 pagesScientific Method Grade 8Glydell AnnNo ratings yet
- Past Paper 2019Document7 pagesPast Paper 2019Choco CheapNo ratings yet
- Creating A Data Analysis Plan What ToDocument7 pagesCreating A Data Analysis Plan What TokaaanyuNo ratings yet
- Out 2Document204 pagesOut 2api-343702373No ratings yet
- A Review of Methods Used On IT Maturity Models Development A Systematic Literature Review and A Critical AnalysisDocument18 pagesA Review of Methods Used On IT Maturity Models Development A Systematic Literature Review and A Critical AnalysisBelther LeccaNo ratings yet
- L3 Hypothesis TestDocument17 pagesL3 Hypothesis TestMustafa BrifkaniNo ratings yet
- Math13 - Advanced Statistics Lecture Note: Case of K-SamplesDocument13 pagesMath13 - Advanced Statistics Lecture Note: Case of K-SamplesAbegail VillanuevaNo ratings yet
- Hypothesis Testing IIDocument48 pagesHypothesis Testing IISandra SureshNo ratings yet
- Ats1298 Lecture Answers - ResearchDocument3 pagesAts1298 Lecture Answers - ResearchJoey G CirilloNo ratings yet
- Test Bank For Chemistry Atoms First 4th Edition Julia Burdge Jason OverbyDocument65 pagesTest Bank For Chemistry Atoms First 4th Edition Julia Burdge Jason Overbyermintrudeletitia5lsyNo ratings yet
- The Full Skittles ProjectDocument6 pagesThe Full Skittles Projectapi-340271527100% (1)