You might also like
- Effective Leadership 5th Edition Lussier Test BankDocument41 pagesEffective Leadership 5th Edition Lussier Test Bankreginagwyn0157y100% (22)
- Essentials of Business Law and The Legal Environment 12th Edition Mann Test BankDocument29 pagesEssentials of Business Law and The Legal Environment 12th Edition Mann Test Bankfelixedanafte5n100% (32)
- Essentials of Corporate Finance 1st Edition Parrino Solutions ManualDocument36 pagesEssentials of Corporate Finance 1st Edition Parrino Solutions Manualderrickgrantpnykbwjzfx100% (28)
- Financial Reporting 2nd Edition Loftus Solutions ManualDocument41 pagesFinancial Reporting 2nd Edition Loftus Solutions Manualmrsbrianajonesmdkgzxyiatoq100% (27)
- Contemporary Nutrition 9th Edition Wardlaw Test BankDocument35 pagesContemporary Nutrition 9th Edition Wardlaw Test Bankcolinshannonwoscyfzanm100% (31)
- Introduct Programmi C International 3rd Edition Liang Test BankDocument7 pagesIntroduct Programmi C International 3rd Edition Liang Test Bankadelaidelatifahjq8w5100% (37)
- Calculus Early Transcendental Functions 4th Edition Smith Test BankDocument25 pagesCalculus Early Transcendental Functions 4th Edition Smith Test Bankpeterrodriguezcwbqomdksi100% (36)
- Essentials of Anatomy and Physiology 6th Edition Martini Solutions ManualDocument12 pagesEssentials of Anatomy and Physiology 6th Edition Martini Solutions Manualscarletba4cc100% (34)
- Essentials of Contemporary Management 5th Edition Jones Solutions ManualDocument25 pagesEssentials of Contemporary Management 5th Edition Jones Solutions ManualEdwardBrooksqcoi100% (51)
- Entrepreneurship Starting and Operating A Small Business 4th Edition Mariotti Solutions ManualDocument18 pagesEntrepreneurship Starting and Operating A Small Business 4th Edition Mariotti Solutions Manualtruongjethrozt9wgt100% (34)
- Essentials of Corporate Finance 9th Edition Ross Solutions ManualDocument16 pagesEssentials of Corporate Finance 9th Edition Ross Solutions Manualadeliadacsc3o100% (24)
- Discover Sociology 3rd Edition Chambliss Test BankDocument24 pagesDiscover Sociology 3rd Edition Chambliss Test Bankdacdonaldnxv1zq100% (36)
- Step by Step To College and Career Success 6th Edition Gardner Test BankDocument11 pagesStep by Step To College and Career Success 6th Edition Gardner Test Bankedithhao6i4tmo100% (22)
- Solution Manual For SELL 3rd Edition Ingram LaForge Avila Schwepker Williams 113318832X 9781133188322Document36 pagesSolution Manual For SELL 3rd Edition Ingram LaForge Avila Schwepker Williams 113318832X 9781133188322jessicawhiteozdpyqwejn100% (25)
- Mcgraw Hills Taxation of Individuals and Business Entities 2019 10th Edition Spilker Test BankDocument49 pagesMcgraw Hills Taxation of Individuals and Business Entities 2019 10th Edition Spilker Test Bankolwenrowank93f100% (30)
- CCH Federal Taxation Comprehensive Topics 2013 1st Edition Harmelink Solutions ManualDocument17 pagesCCH Federal Taxation Comprehensive Topics 2013 1st Edition Harmelink Solutions Manualbodiandoncella9j9to100% (24)
- M Business Communication 3rd Edition Rentz Test BankDocument64 pagesM Business Communication 3rd Edition Rentz Test Bankpearlclement0hzi0100% (24)
- Accounting Information Systems The Crossroads of Accounting and It 2nd Edition Kay Test BankDocument27 pagesAccounting Information Systems The Crossroads of Accounting and It 2nd Edition Kay Test Bankmalabarhumane088100% (31)
- Cultural Anthropology 9th Edition Scupin Test BankDocument13 pagesCultural Anthropology 9th Edition Scupin Test Bankvaleriewashingtonfsnxgzyjbi100% (26)
- Test Bank For Experiencing Intercultural Communication An Introduction 7th Edition Judith Martin Thomas Nakayama Full DownloadDocument19 pagesTest Bank For Experiencing Intercultural Communication An Introduction 7th Edition Judith Martin Thomas Nakayama Full Downloadaaronwarrenpgozeainyq100% (18)
- Consumer Behaviour Buying Having and Being Canadian 7th Edition Solomon Solutions ManualDocument24 pagesConsumer Behaviour Buying Having and Being Canadian 7th Edition Solomon Solutions Manualbasilthoatuis6100% (27)
- Health Psychology A Cultural Approach 3rd Edition Gurung Test BankDocument9 pagesHealth Psychology A Cultural Approach 3rd Edition Gurung Test Bankflyblowpashawbt7k100% (32)
- Financial Markets and Institutions Global 7th Edition Mishkin Solutions ManualDocument25 pagesFinancial Markets and Institutions Global 7th Edition Mishkin Solutions ManualIanGaymkaf100% (64)
- Essentials of Corporate Finance 8th Edition Ross Solutions ManualDocument16 pagesEssentials of Corporate Finance 8th Edition Ross Solutions Manualtalliagepersonp5r7c100% (25)
- Corporate Finance Core Principles and Applications 4th Edition Ross Solutions ManualDocument14 pagesCorporate Finance Core Principles and Applications 4th Edition Ross Solutions Manualphungkhainwa7ow100% (29)
- E Commerce Essentials 1st Edition Laudon Test BankDocument18 pagesE Commerce Essentials 1st Edition Laudon Test Bankraphaelbacrqu100% (27)
- Essentials of Contemporary Business 1st Edition Boone Test BankDocument65 pagesEssentials of Contemporary Business 1st Edition Boone Test Bankderrickgrantpnykbwjzfx100% (29)
- Entrepreneurship The Art Science and Process For Success 2nd Edition Bamford Test BankDocument70 pagesEntrepreneurship The Art Science and Process For Success 2nd Edition Bamford Test Bankherbistazarole5fuyh6100% (22)
- Business Ethics Ethical Decision Making and Cases 9th Edition Ferrell Solutions ManualDocument6 pagesBusiness Ethics Ethical Decision Making and Cases 9th Edition Ferrell Solutions Manualkennethhue1tp64c100% (27)
- Consumer Behavior 11th Edition Schiffman Test BankDocument41 pagesConsumer Behavior 11th Edition Schiffman Test Bankciaramilcahbrpe100% (25)
- Solution Manual For Sexuality Today 11th Edition Kelly 0078035473 9780078035470Document36 pagesSolution Manual For Sexuality Today 11th Edition Kelly 0078035473 9780078035470ricardorobinsonpiabnjxgwm100% (21)
- Taxation of Individuals 5th Edition Spilker Test Bank 1Document36 pagesTaxation of Individuals 5th Edition Spilker Test Bank 1davidortizotgdfmjzis100% (26)
- Challenge of Democracy American Government in Global Politics 13th Edition Janda Test BankDocument19 pagesChallenge of Democracy American Government in Global Politics 13th Edition Janda Test Bankdrkevinlee03071984jki100% (35)
- Business in Action 6th Edition Bovee Solutions ManualDocument14 pagesBusiness in Action 6th Edition Bovee Solutions Manualnhatmaiqfanmk100% (32)
- Better Business 3rd Edition Solomon Solutions ManualDocument13 pagesBetter Business 3rd Edition Solomon Solutions Manualdorothydoij03k100% (24)
- Consumer Behavior 12th Edition Schiffman Test BankDocument31 pagesConsumer Behavior 12th Edition Schiffman Test Bankrowanbridgetuls3100% (24)
- Essentials of Corporate Finance 1st Edition Parrino Solutions ManualDocument25 pagesEssentials of Corporate Finance 1st Edition Parrino Solutions ManualAlexanderBoyerwoit100% (54)
- Essentials of Anatomy and Physiology 1st Edition Saladin Solutions ManualDocument5 pagesEssentials of Anatomy and Physiology 1st Edition Saladin Solutions Manualdaineil2td100% (31)
- Financial Reporting and Analysis 13th Edition Gibson Solutions ManualDocument23 pagesFinancial Reporting and Analysis 13th Edition Gibson Solutions ManualTiffanyHernandezerij100% (58)
- Macroeconomics 8th Edition Mankiw Test BankDocument22 pagesMacroeconomics 8th Edition Mankiw Test Bankberthaluyenkaq9w100% (26)
- Essentials of Contract Law 2nd Edition Frey Test BankDocument4 pagesEssentials of Contract Law 2nd Edition Frey Test Bankrachelhalecwqxjebfny100% (20)
- Challenge of Democracy 12th Edition Janda Test BankDocument36 pagesChallenge of Democracy 12th Edition Janda Test Bankrubydac7a9h05100% (36)
- Essentials of Contemporary Management 6th Edition Jones Solutions ManualDocument26 pagesEssentials of Contemporary Management 6th Edition Jones Solutions ManualBryanHarriswtmi100% (58)
- Organizational Theory Design and Change 7th Edition Jones Test BankDocument25 pagesOrganizational Theory Design and Change 7th Edition Jones Test Bankemilymorrowjmtafrqcdn100% (36)
- Essentials of Accounting For Governmental and Not For Profit Organizations 13th Edition Copley Solutions ManualDocument18 pagesEssentials of Accounting For Governmental and Not For Profit Organizations 13th Edition Copley Solutions Manualdaineil2td100% (28)
- Essentials of Geology 5th Edition Marshak Test BankDocument12 pagesEssentials of Geology 5th Edition Marshak Test Bankxavialaylacs4vl4100% (24)
- Illustrated Course Guide Microsoft Office 365 and Access 2016 Intermediate Spiral Bound Version 1st Edition Friedrichsen Solutions ManualDocument10 pagesIllustrated Course Guide Microsoft Office 365 and Access 2016 Intermediate Spiral Bound Version 1st Edition Friedrichsen Solutions Manualfizzexponeo04xv0100% (24)
- Essential Foundations of Economics 8th Edition Bade Solutions ManualDocument17 pagesEssential Foundations of Economics 8th Edition Bade Solutions Manualtannagemesodermh4ge100% (21)
- Investments Analysis and Management 12th Edition Jones Test BankDocument14 pagesInvestments Analysis and Management 12th Edition Jones Test Bankodilemelanie83au100% (29)
- Marketing International 17th Edition Hult Test BankDocument35 pagesMarketing International 17th Edition Hult Test Banktomurielkxrwey100% (21)
- Earth 1st Edition Thompson Test BankDocument8 pagesEarth 1st Edition Thompson Test Bankquynhagneskrv100% (36)
- International Monetary Financial Economics 1st Edition Daniels Solutions ManualDocument8 pagesInternational Monetary Financial Economics 1st Edition Daniels Solutions Manualhypatiadaisypkm100% (29)
- Operations Management Canadian 6th Edition Stevenson Solutions ManualDocument22 pagesOperations Management Canadian 6th Edition Stevenson Solutions Manualeiranguyenrd8t100% (25)
- Accounting Information Systems Global 14th Edition Romney Test BankDocument29 pagesAccounting Information Systems Global 14th Edition Romney Test Bankrobingomezwqfbdcaksn100% (38)
- Advanced Nutrition and Human Metabolism 7th Edition Gropper Test BankDocument21 pagesAdvanced Nutrition and Human Metabolism 7th Edition Gropper Test Bankrebeccagomezearndpsjkc100% (25)
- Contemporary Marketing 16th Edition Boone Solutions ManualDocument33 pagesContemporary Marketing 16th Edition Boone Solutions Manualoralieedanan5ilp100% (28)
- Core Concepts of Government and Not For Profit Accounting 2nd Edition Granof Test BankDocument15 pagesCore Concepts of Government and Not For Profit Accounting 2nd Edition Granof Test Bankphenicboxironicu9100% (36)
- Taxation of Individuals 2017 8th Edition Spilker Solutions Manual 1Document36 pagesTaxation of Individuals 2017 8th Edition Spilker Solutions Manual 1troysalazartxqiwygaoj100% (19)
- Solution Manual For Statistics Data Analysis and Decision Modeling 5th Edition Evans 0132744287 9780132744287Document7 pagesSolution Manual For Statistics Data Analysis and Decision Modeling 5th Edition Evans 0132744287 9780132744287tiffanybreweridearcpxmz100% (23)
- Essentials of Business Statistics Communicating With Numbers 1st Edition Jaggia Solutions Manual DownloadDocument27 pagesEssentials of Business Statistics Communicating With Numbers 1st Edition Jaggia Solutions Manual DownloadAlonzo Oliver100% (30)
- Instant Download Entrepreneurial Small Business 4th Edition Katz Test Bank PDF Full ChapterDocument32 pagesInstant Download Entrepreneurial Small Business 4th Edition Katz Test Bank PDF Full Chapterfelixedanafte5n100% (11)
- Instant Download Entrepreneurship 10th Edition Hisrich Solutions Manual PDF Full ChapterDocument32 pagesInstant Download Entrepreneurship 10th Edition Hisrich Solutions Manual PDF Full Chapterfelixedanafte5n100% (8)
- Instant Download Entrepreneurship 2008 1st Edition Bygrave Solutions Manual PDF Full ChapterDocument32 pagesInstant Download Entrepreneurship 2008 1st Edition Bygrave Solutions Manual PDF Full Chapterfelixedanafte5n100% (10)
- Instant Download Entrepreneurial Small Business 5th Edition Katz Solutions Manual PDF Full ChapterDocument32 pagesInstant Download Entrepreneurial Small Business 5th Edition Katz Solutions Manual PDF Full Chapterfelixedanafte5n100% (9)
- Essentials of Business Law 8th Edition Liuzzo Test BankDocument22 pagesEssentials of Business Law 8th Edition Liuzzo Test Bankfelixedanafte5n100% (31)
- Essential University Physics Volume II 3rd Edition Wolfson Solutions ManualDocument27 pagesEssential University Physics Volume II 3rd Edition Wolfson Solutions Manualfelixedanafte5n100% (26)
- Essential University Physics 3rd Edition Richard Wolfson Test BankDocument11 pagesEssential University Physics 3rd Edition Richard Wolfson Test Bankfelixedanafte5n100% (32)
- Toefl StructureDocument50 pagesToefl StructureFebrian AsharNo ratings yet
- Rotc Reviewer FinalsDocument11 pagesRotc Reviewer FinalsAngel Atienza100% (1)
- Why Do Kashmiris Need Self-Determination?: UncategorizedDocument16 pagesWhy Do Kashmiris Need Self-Determination?: UncategorizedFarooq SiddiqiNo ratings yet
- Lahainaluna High School Cafeteria: Lahaina, Maui, HawaiiDocument42 pagesLahainaluna High School Cafeteria: Lahaina, Maui, HawaiiKeerthy MoniNo ratings yet
- Avanquest Perfect Image V.12 User GuideDocument174 pagesAvanquest Perfect Image V.12 User GuideShafiq-UR-Rehman Lodhi100% (1)
- Introduction To Physiotherapy PracticeDocument22 pagesIntroduction To Physiotherapy PracticejNo ratings yet
- (AVA Academia) Lorraine Farrelly - The Fundamentals of architecture-AVA Academia (2012) - Trang-137-161Document25 pages(AVA Academia) Lorraine Farrelly - The Fundamentals of architecture-AVA Academia (2012) - Trang-137-161Thảo VyNo ratings yet
- Digital ThermometerDocument12 pagesDigital Thermometershahpatel19No ratings yet
- Construction of Perimeter Fence of BFP NHQ PDFDocument133 pagesConstruction of Perimeter Fence of BFP NHQ PDFYalla ChaitanyaNo ratings yet
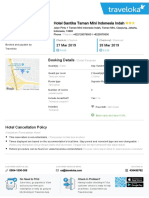
- Hotel Voucher: Itinerary ID Hotel Santika Taman Mini Indonesia IndahDocument2 pagesHotel Voucher: Itinerary ID Hotel Santika Taman Mini Indonesia IndahSyukron PribadiNo ratings yet
- Selux Installation Manual PDFDocument75 pagesSelux Installation Manual PDFIgorr75% (8)
- Modal Verbs of Ability and PossibilityDocument12 pagesModal Verbs of Ability and PossibilitymslolinrNo ratings yet
- Certain Application of Photovo PDFDocument235 pagesCertain Application of Photovo PDFaun_nustNo ratings yet
- PLX Model OfficialDocument105 pagesPLX Model OfficialBảo Ngọc LêNo ratings yet
- Analyse Bacterologique de L EauDocument6 pagesAnalyse Bacterologique de L Eaupeguy diffoNo ratings yet
- Full Download Human Biology 11th Edition Starr Solutions ManualDocument35 pagesFull Download Human Biology 11th Edition Starr Solutions Manualsheathe.zebrinny.53vubg100% (41)
- Thom22e ch03 FinalDocument44 pagesThom22e ch03 FinalDionisius AlvianNo ratings yet
- Movie Review of THORDocument8 pagesMovie Review of THORSiva LetchumiNo ratings yet
- Esp8285 Datasheet enDocument29 pagesEsp8285 Datasheet enJohn GreenNo ratings yet
- Van Daley - Leadership ResumeDocument1 pageVan Daley - Leadership Resumeapi-352146181No ratings yet
- Audit Committee and Corporate Governance: CA Pragnesh Kanabar Sir's The Audit Academy-CA Final AuditDocument17 pagesAudit Committee and Corporate Governance: CA Pragnesh Kanabar Sir's The Audit Academy-CA Final AuditPULKIT MURARKANo ratings yet
- Architech 06-2016 Room AssignmentDocument4 pagesArchitech 06-2016 Room AssignmentPRC Baguio100% (1)
- Architecture of Neural NWDocument79 pagesArchitecture of Neural NWapi-3798769No ratings yet
- UV-Visible Systems - Operational Qualification - Col23 PDFDocument10 pagesUV-Visible Systems - Operational Qualification - Col23 PDFIsabelle PlourdeNo ratings yet
- Autodesk Design Review: About DWF and DWFXDocument7 pagesAutodesk Design Review: About DWF and DWFXNesreNo ratings yet
- Data Analyst Chapter 3Document20 pagesData Analyst Chapter 3Andi Annisa DianputriNo ratings yet
- Teccrs 3800Document431 pagesTeccrs 3800Genus SumNo ratings yet
- Basic: M1736N Model: MW73VR Model Code: Mw73Vr/BwtDocument42 pagesBasic: M1736N Model: MW73VR Model Code: Mw73Vr/Bwtsantiago962No ratings yet
- Risk Assessment For ExcavationDocument6 pagesRisk Assessment For ExcavationAhmed GamalNo ratings yet
- STS Reviewer FinalsDocument33 pagesSTS Reviewer FinalsLeiNo ratings yet