You might also like
- Implementation of A 16-Bit RISC Processor Using FPGA ProgrammingDocument25 pagesImplementation of A 16-Bit RISC Processor Using FPGA ProgrammingTejashree100% (3)
- Prasthanam Movie ScreenplayDocument191 pagesPrasthanam Movie ScreenplayAllTeluguFilms100% (2)
- Prasthanam Movie ScreenplayDocument191 pagesPrasthanam Movie ScreenplayAllTeluguFilms100% (2)
- Cbs BookDocument294 pagesCbs Bookadmiralninja100% (1)
- Past Simple Past ContinuousDocument2 pagesPast Simple Past ContinuousEsmeralda Gonzalez80% (5)
- ARM ProcessorDocument46 pagesARM Processoryixexi7070No ratings yet
- Cad For Vlsi 2 Pro Ject - Superscalar Processor ImplementationDocument10 pagesCad For Vlsi 2 Pro Ject - Superscalar Processor ImplementationkbkkrNo ratings yet
- Embedded Lecture 4 ARMDocument47 pagesEmbedded Lecture 4 ARMmsmukeshsinghmsNo ratings yet
- Module-3_ARMProgram_Notes.-16857877494142.pdfDocument5 pagesModule-3_ARMProgram_Notes.-16857877494142.pdfrockyv9964No ratings yet
- Embedded System Design Iv Ece - I Sem (PE-IV)Document31 pagesEmbedded System Design Iv Ece - I Sem (PE-IV)Bharath RamNo ratings yet
- Module-2: Microcontroller and Embedded SystemsDocument74 pagesModule-2: Microcontroller and Embedded Systemsswethaashok28No ratings yet
- 5-stage ARM pipeline organization and instruction executionDocument6 pages5-stage ARM pipeline organization and instruction executionchaitudscNo ratings yet
- EE6008 Unit 5Document8 pagesEE6008 Unit 5TakeItEasyDude TIEDNo ratings yet
- Computer Architecture: Pipelining: Dr. Ashok Kumar TurukDocument136 pagesComputer Architecture: Pipelining: Dr. Ashok Kumar TurukkoottyNo ratings yet
- Model Question Paper with solution for Advanced Embedded Systems DesignDocument26 pagesModel Question Paper with solution for Advanced Embedded Systems Designlaxmi shindeNo ratings yet
- ARM7 ARCHITECTURE OVERVIEWDocument8 pagesARM7 ARCHITECTURE OVERVIEWVipin TiwariNo ratings yet
- M-4 CODocument61 pagesM-4 COrohitrajww4No ratings yet
- Unit 4Document53 pagesUnit 4subithavNo ratings yet
- Solution Assignment No 2Document8 pagesSolution Assignment No 2Mian EjazNo ratings yet
- Instructions SchedulingDocument26 pagesInstructions SchedulingNishmika PothanaNo ratings yet
- RISC Instruction Set:: I) Data Manipulation InstructionsDocument8 pagesRISC Instruction Set:: I) Data Manipulation InstructionsSwarup BharNo ratings yet
- Architecture of Computers Lab1Document28 pagesArchitecture of Computers Lab1q5nfvkbyyrNo ratings yet
- ARM Organization OverviewDocument56 pagesARM Organization OverviewTakeItEasyDude TIEDNo ratings yet
- ARM - Advanced RISC Machines Architecture OverviewDocument60 pagesARM - Advanced RISC Machines Architecture OverviewPraveen EdulaNo ratings yet
- BITS Pilani Advanced Computer Architecture Test 1 SolutionsDocument4 pagesBITS Pilani Advanced Computer Architecture Test 1 SolutionsAman AgnihotriNo ratings yet
- Unit - IDocument47 pagesUnit - IcjramancjNo ratings yet
- Co Unit 2.1Document45 pagesCo Unit 2.1Prasanth ReddyNo ratings yet
- Assignment QuestionsDocument3 pagesAssignment QuestionsSarbendu PaulNo ratings yet
- Acorn RISC MachineDocument6 pagesAcorn RISC Machinesolomon girmaNo ratings yet
- Computer Organization-Single CycleDocument23 pagesComputer Organization-Single Cyclev2brotherNo ratings yet
- BCA-305 Computer Architecture Unit 1-Introduction: Dr. Santosh Kumar Lucknow Public College of Professional StudiesDocument34 pagesBCA-305 Computer Architecture Unit 1-Introduction: Dr. Santosh Kumar Lucknow Public College of Professional StudiessadsaNo ratings yet
- Introduction To MIPS ArchitectureDocument10 pagesIntroduction To MIPS ArchitectureJahanzaib AwanNo ratings yet
- UNIT 4 - Fundamental Concepts and Processor OrganizationDocument55 pagesUNIT 4 - Fundamental Concepts and Processor OrganizationMUHMMAD ZAID KURESHINo ratings yet
- Chapter 5 - The Processor, Datapath and ControlDocument23 pagesChapter 5 - The Processor, Datapath and ControlBijay MishraNo ratings yet
- Module - 5 - ARMDocument45 pagesModule - 5 - ARMatharv atreNo ratings yet
- ARM 1vDocument31 pagesARM 1vsuntosh_14No ratings yet
- The Acorn RISC Machine (ARM)Document12 pagesThe Acorn RISC Machine (ARM)Vikas SinghNo ratings yet
- ARM Instruction Set ArchitectureDocument71 pagesARM Instruction Set ArchitectureVamsi SomisettyNo ratings yet
- ARM 4 Part2Document9 pagesARM 4 Part2SUGYAN ANAND MAHARANANo ratings yet
- Second Operand: Shifted Register: EitherDocument13 pagesSecond Operand: Shifted Register: EitherGilberto VirgilioNo ratings yet
- ARM Microcontroller Introduction and FeaturesDocument21 pagesARM Microcontroller Introduction and FeatureskalyanNo ratings yet
- CS-3010 (HPC) - CS Mid Sept 2023Document7 pagesCS-3010 (HPC) - CS Mid Sept 2023rajeevkgrd20No ratings yet
- ARM Introduction & Instruction Set ArchitectureDocument71 pagesARM Introduction & Instruction Set ArchitecturebalaNo ratings yet
- ACE201slides 8Document75 pagesACE201slides 8alexistheNo ratings yet
- Advanced Risc MachinersDocument21 pagesAdvanced Risc MachinersAANCHALNo ratings yet
- ARMfinal 1Document114 pagesARMfinal 1Bhawandeep SinglaNo ratings yet
- Basic Processing UnitDocument49 pagesBasic Processing UnitritikNo ratings yet
- Instruction TypesDocument8 pagesInstruction Typestp2006sterNo ratings yet
- The Pipelined RiSC-16 ComputerDocument9 pagesThe Pipelined RiSC-16 Computerkb_lu232No ratings yet
- LU11-12 Instruction ExecutionDocument18 pagesLU11-12 Instruction ExecutionMani Bharathi VNo ratings yet
- Iat-4 McesDocument12 pagesIat-4 Mcesbhatt bhattNo ratings yet
- Data Processing InstructionsDocument21 pagesData Processing InstructionsShin chan HindiNo ratings yet
- ARM Instruction SetDocument58 pagesARM Instruction SetPoorva RathoreNo ratings yet
- ARM Organization and Implementation: Aleksandar MilenkovicDocument37 pagesARM Organization and Implementation: Aleksandar Milenkovicarthicse100% (1)
- Chapter 2 - Architecture of ARM ProcessorDocument43 pagesChapter 2 - Architecture of ARM Processor方勤No ratings yet
- CS501 Lecture Handout on Computer ArchitectureDocument12 pagesCS501 Lecture Handout on Computer ArchitectureSaira GillaniNo ratings yet
- ARM Assembly Language Programming IntroductionDocument34 pagesARM Assembly Language Programming IntroductionWeehao Siow100% (1)
- Chapter 3Document48 pagesChapter 3Aman Ethio LijNo ratings yet
- 3 Introduction PipelineDocument149 pages3 Introduction PipelineIshwar MhtNo ratings yet
- EEM 486 Computer Architecture Homework VI 1. Consider The Following Code SequenceDocument2 pagesEEM 486 Computer Architecture Homework VI 1. Consider The Following Code SequenceHalim KorogluNo ratings yet
- Lec4 Computer ArchitectureDocument37 pagesLec4 Computer ArchitectureAwe HughNo ratings yet
- M-5 CODocument95 pagesM-5 COrohitrajww4No ratings yet
- Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationFrom EverandPractical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationNo ratings yet
- MTU 2020 Byt: TS0vee PohiDocument1 pageMTU 2020 Byt: TS0vee PohiRohith ThurlapatiNo ratings yet
- Embedded SystemsDocument23 pagesEmbedded SystemsRohith ThurlapatiNo ratings yet
- Branch Instructions: Branch: B Label Branch With Link: BL Subroutine - LabelDocument7 pagesBranch Instructions: Branch: B Label Branch With Link: BL Subroutine - LabelRohith ThurlapatiNo ratings yet
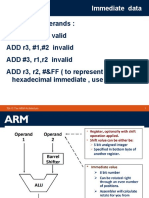
- Immediate Operands: ADD r3, r3, #1 Valid ADD r3, #1,#2 Invalid ADD #3, r1, r2 Invalid ADD r3, r2, #&FF (To Represent Hexadecimal Immediate, Use &)Document23 pagesImmediate Operands: ADD r3, r3, #1 Valid ADD r3, #1,#2 Invalid ADD #3, r1, r2 Invalid ADD r3, r2, #&FF (To Represent Hexadecimal Immediate, Use &)Rohith ThurlapatiNo ratings yet
- ARM Multiply InstructionsDocument39 pagesARM Multiply InstructionsRohith ThurlapatiNo ratings yet
- Lecture6 ARMDocument50 pagesLecture6 ARMRohith ThurlapatiNo ratings yet
- Lecture8 ARMDocument16 pagesLecture8 ARMRohith ThurlapatiNo ratings yet
- Introduction To Programming LanguagesDocument16 pagesIntroduction To Programming LanguagesSammy KumarNo ratings yet
- Graph Algorithms: Text Book: Introduction To Algorithms ByclrsDocument142 pagesGraph Algorithms: Text Book: Introduction To Algorithms ByclrsRohith ThurlapatiNo ratings yet
- Branch Instructions: Branch: B Label Branch With Link: BL Subroutine - LabelDocument7 pagesBranch Instructions: Branch: B Label Branch With Link: BL Subroutine - LabelRohith ThurlapatiNo ratings yet
- Online Summer Internship - EE-NITAP2020-FINAL PDFDocument1 pageOnline Summer Internship - EE-NITAP2020-FINAL PDFRohith ThurlapatiNo ratings yet
- ARM Architecture GuideDocument25 pagesARM Architecture GuideRohith ThurlapatiNo ratings yet
- Thumb InstructionDocument52 pagesThumb InstructionRohith ThurlapatiNo ratings yet
- ARM Architecture GuideDocument25 pagesARM Architecture GuideRohith ThurlapatiNo ratings yet
- Online Summer Internship - EE-NITAP2020-FINAL PDFDocument1 pageOnline Summer Internship - EE-NITAP2020-FINAL PDFRohith ThurlapatiNo ratings yet
- CRK GraphsDocument36 pagesCRK GraphsRohith ThurlapatiNo ratings yet
- BFS PPTDocument11 pagesBFS PPTRohith ThurlapatiNo ratings yet
- Online Summer Internship - EE-NITAP2020-FINAL PDFDocument1 pageOnline Summer Internship - EE-NITAP2020-FINAL PDFRohith ThurlapatiNo ratings yet
- OOAD Chapter 3Document7 pagesOOAD Chapter 3Rohith ThurlapatiNo ratings yet
- Pce 1003 HandbookDocument21 pagesPce 1003 HandbookVineetha LekkalaNo ratings yet
- BACnet Router ERED Algorithm for Congestion AvoidanceDocument4 pagesBACnet Router ERED Algorithm for Congestion AvoidanceRohith ThurlapatiNo ratings yet
- Estudio ArminioDocument13 pagesEstudio ArminioJavier LópezNo ratings yet
- Three Thousand Years of Longing 2022Document93 pagesThree Thousand Years of Longing 2022Ppper pepperNo ratings yet
- Wind Energy Services Brochure 4696 3 Da en PDFDocument62 pagesWind Energy Services Brochure 4696 3 Da en PDFghadasaudiNo ratings yet
- Math207 Portfolio1 2Document5 pagesMath207 Portfolio1 2api-297797024No ratings yet
- Kma 252 Exam 18 NewstyleDocument19 pagesKma 252 Exam 18 NewstyleSebin GeorgeNo ratings yet
- Underwater vessels, sensors, weapons and control systemsDocument1 pageUnderwater vessels, sensors, weapons and control systemsNguyễn ThaoNo ratings yet
- Gaudapadacharya - The Founder of The Tradition of Advaita VedantaDocument4 pagesGaudapadacharya - The Founder of The Tradition of Advaita VedantasukubhNo ratings yet
- Chapter 5Document42 pagesChapter 5Hong AnhNo ratings yet
- 3.19 Passive VoiceDocument10 pages3.19 Passive VoiceRetno RistianiNo ratings yet
- Roke TsanDocument53 pagesRoke Tsanhittaf_05No ratings yet
- Analysis of A Refrigeration Cycle With Coolprop PDFDocument6 pagesAnalysis of A Refrigeration Cycle With Coolprop PDFewan_73No ratings yet
- Section 6 - Diagnostic ProceduresDocument13 pagesSection 6 - Diagnostic Proceduresanon_152488453100% (1)
- Aquilion ONE GENESIS Edition Transforming CTDocument40 pagesAquilion ONE GENESIS Edition Transforming CTSemeeeJuniorNo ratings yet
- 40 Inventive Principles Applied to Service OperationsDocument16 pages40 Inventive Principles Applied to Service Operationssina yadegariNo ratings yet
- All+DPPs+in+One+ +M+and+DDocument136 pagesAll+DPPs+in+One+ +M+and+DSumit RajNo ratings yet
- Bonny Norton Peirce - Social Identity and InvestmentDocument24 pagesBonny Norton Peirce - Social Identity and InvestmentAllie SANo ratings yet
- CIE Master 2022 (New Master Programme) ENDocument171 pagesCIE Master 2022 (New Master Programme) ENZar MaghustNo ratings yet
- Modul Hots (Kbat) Kimia Tingkatan 5Document15 pagesModul Hots (Kbat) Kimia Tingkatan 5Hairul Razif Mohd IdrisNo ratings yet
- Palm Kernel Reinforced Composites for Brake Pad ApplicationsDocument18 pagesPalm Kernel Reinforced Composites for Brake Pad ApplicationsSachin SukumaranNo ratings yet
- Touch-Tone Recognition: EE301 Final Project April 26, 2010 MHP 101Document20 pagesTouch-Tone Recognition: EE301 Final Project April 26, 2010 MHP 101Sheelaj BabuNo ratings yet
- RRB NTPC Cut Off 2022 - CBT 2 Region Wise Cut Off Marks & Answer KeyDocument8 pagesRRB NTPC Cut Off 2022 - CBT 2 Region Wise Cut Off Marks & Answer KeyAkash guptaNo ratings yet
- Final CBLMDocument66 pagesFinal CBLMRanilyn UrbiztundoNo ratings yet
- Manual THT70 PDFDocument54 pagesManual THT70 PDFwerterNo ratings yet
- Elementary English Lesson LogsDocument9 pagesElementary English Lesson LogsApril Mendoza-ConradaNo ratings yet
- Multiple PDP Contexts User Guide Rev1Document16 pagesMultiple PDP Contexts User Guide Rev1ajit_balyan2003No ratings yet
- Basavarajeshwari Group of Institutions: Self Balancing UnicycleDocument15 pagesBasavarajeshwari Group of Institutions: Self Balancing UnicycleJeerigi DeepikaNo ratings yet
- Innovative Lp1 BlogDocument5 pagesInnovative Lp1 BlogArya ElizabethNo ratings yet
- R V Akeemly Grant & Andre WilliamsDocument5 pagesR V Akeemly Grant & Andre WilliamsKerry-Ann WilsonNo ratings yet