You might also like
- Who Are The Pleiadian Emissaries of LightDocument3 pagesWho Are The Pleiadian Emissaries of LightMichelle88% (8)
- (Peter J. Olver, Chehrzad Shakiban) Instructor's SDocument357 pages(Peter J. Olver, Chehrzad Shakiban) Instructor's STasya NLNo ratings yet
- Switchword PairsDocument6 pagesSwitchword PairsLaleKulahli100% (7)
- CWI - Part A Fundamentals Examination (Full) PDFDocument43 pagesCWI - Part A Fundamentals Examination (Full) PDFJulian Ramirez Ospina100% (4)
- Does Cash App Have Business Accounts - Google SeaDocument1 pageDoes Cash App Have Business Accounts - Google SeaAdedayo CrownNo ratings yet
- Curve Fitting - DSDocument9 pagesCurve Fitting - DSDarsana Barathi100% (1)
- Drewry Capability StatementDocument9 pagesDrewry Capability Statementmanis_sgsNo ratings yet
- CIH EXAM Equations 2020 Explained by Expert Dr. Daniel FarcasDocument36 pagesCIH EXAM Equations 2020 Explained by Expert Dr. Daniel FarcasDaniel FarcasNo ratings yet
- Origin User Guide 2022b EDocument450 pagesOrigin User Guide 2022b Enagatopein6No ratings yet
- MAT Paper 2015 SolutionsDocument9 pagesMAT Paper 2015 SolutionsXu SarahNo ratings yet
- Rhythm MP - The Music Page - Theory Made Easy For Little Children Level 1Document9 pagesRhythm MP - The Music Page - Theory Made Easy For Little Children Level 1AmilacicNo ratings yet
- Problems and Solutions To Abstract Algebra Beachy Blair PDFDocument61 pagesProblems and Solutions To Abstract Algebra Beachy Blair PDFAngsNo ratings yet
- Aquilion ONE GENESIS Edition Transforming CTDocument40 pagesAquilion ONE GENESIS Edition Transforming CTSemeeeJuniorNo ratings yet
- Ch6 (2) Curve FittingDocument15 pagesCh6 (2) Curve FittingMd. Tanvir AhmedNo ratings yet
- MCA (Revised) Term-End Examination February, 2021 Mcse-004: Numerical and Statistical ComputingDocument6 pagesMCA (Revised) Term-End Examination February, 2021 Mcse-004: Numerical and Statistical ComputingRekha PathakNo ratings yet
- CIVN2010-2-Solutions of Equations of Only One VariableDocument20 pagesCIVN2010-2-Solutions of Equations of Only One VariableKavish DayaNo ratings yet
- Tutorial 3Document6 pagesTutorial 3Snehita NNo ratings yet
- Algebraic Equations in One Variable: Engalg1Document21 pagesAlgebraic Equations in One Variable: Engalg1Lia Sophia San MiguelNo ratings yet
- 1 2 3 4 5 6 7 Total Grade: Question 1: (5 Points)Document7 pages1 2 3 4 5 6 7 Total Grade: Question 1: (5 Points)fade abuqamarNo ratings yet
- Econometrics - Seminar 1Document3 pagesEconometrics - Seminar 1KNo ratings yet
- Final 2008 FDocument18 pagesFinal 2008 FMuhammad MurtazaNo ratings yet
- fractionalCalculusMinorThesis PDFDocument98 pagesfractionalCalculusMinorThesis PDFWalaa AltamimiNo ratings yet
- TestPaper_Basic_Calculus_3rd-Quarter_Review_TestDocument7 pagesTestPaper_Basic_Calculus_3rd-Quarter_Review_Testjmdiola14No ratings yet
- Practice Set 2Document7 pagesPractice Set 2jordanhub05No ratings yet
- Questions Answers Topic 5Document5 pagesQuestions Answers Topic 5GerardinNo ratings yet
- 01252022010211AnGeom - Q3 - Module 4 - More of Rotation of AxesDocument15 pages01252022010211AnGeom - Q3 - Module 4 - More of Rotation of AxesJeanne Emerose TalabuconNo ratings yet
- lab08-09Document4 pageslab08-09tenk8595No ratings yet
- Note 5 DDFHDocument7 pagesNote 5 DDFHMizanNo ratings yet
- Lesson Proper - Module 5: Definite IntegralDocument25 pagesLesson Proper - Module 5: Definite IntegralJack NapierNo ratings yet
- m4 Simp (1) PDFDocument4 pagesm4 Simp (1) PDFManoj MNo ratings yet
- Math 114 Activity 1Document4 pagesMath 114 Activity 1DanielNo ratings yet
- Physics 114: Lecture 17 Least Squares Fit To Polynomial: Dale E. GaryDocument12 pagesPhysics 114: Lecture 17 Least Squares Fit To Polynomial: Dale E. Garyawais33306No ratings yet
- STEM HUMSS Q3AS 11 Basic CalculusDocument6 pagesSTEM HUMSS Q3AS 11 Basic Calculusblockwriters20No ratings yet
- C H A P T E R 2 Limits and Their PropertiesDocument36 pagesC H A P T E R 2 Limits and Their Propertiesjoseph.parker496100% (11)
- Econ 115 D - Probset 1Document3 pagesEcon 115 D - Probset 1zhess 4096No ratings yet
- Iterated 2D Gaussian QuadratureDocument12 pagesIterated 2D Gaussian QuadratureVaibhavNo ratings yet
- Review Notes For Discrete MathematicsDocument10 pagesReview Notes For Discrete MathematicsJohn Robert BautistaNo ratings yet
- Tut 2Document2 pagesTut 2CK VigneshNo ratings yet
- Seminar QM Eng-7Document34 pagesSeminar QM Eng-7sevestreanalinNo ratings yet
- Q3 Parallel AssessmentDocument3 pagesQ3 Parallel AssessmentPRINCESS CLARIZZ JOY SALUDESNo ratings yet
- Final 2002F: InterpolationDocument3 pagesFinal 2002F: InterpolationmakrsnakminesNo ratings yet
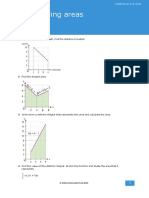
- 13.1 Finding Areas: Represents. 1.5 7 +Document3 pages13.1 Finding Areas: Represents. 1.5 7 +CAPTIAN BIBEKNo ratings yet
- MAFE208IU-L6 - Least Squares RegressionDocument47 pagesMAFE208IU-L6 - Least Squares RegressionThy VũNo ratings yet
- Problem 0: Akshya Gupta September 13, 2021Document48 pagesProblem 0: Akshya Gupta September 13, 2021Akshya_Gupta_8086No ratings yet
- Bachelor of Computer Applications (Bca) (Revised) Term-End Examination June, 2020Document7 pagesBachelor of Computer Applications (Bca) (Revised) Term-End Examination June, 2020Dilbagh SinghNo ratings yet
- Real Analysis Problem SolutionDocument6 pagesReal Analysis Problem SolutionAparajeeta GuhaNo ratings yet
- Answers Ch2.3-2.5Document5 pagesAnswers Ch2.3-2.5ntokozocecilia81No ratings yet
- Report: Integral Calculations Using C++ CodeDocument8 pagesReport: Integral Calculations Using C++ CodeYosua Heru IrawanNo ratings yet
- 1 Intro BisectionMethod PDFDocument11 pages1 Intro BisectionMethod PDFamir nabilNo ratings yet
- WTW 124: Selected Answers To Chapter 1 (1.1 To 1.4) Exercise 1.1Document4 pagesWTW 124: Selected Answers To Chapter 1 (1.1 To 1.4) Exercise 1.1ntokozocecilia81No ratings yet
- IPY3 Mathematics Revised NotesDocument28 pagesIPY3 Mathematics Revised NotesTyler HtooNo ratings yet
- Spring Exam 1718 Review JWDocument7 pagesSpring Exam 1718 Review JWOlivia GroeneveldNo ratings yet
- Week 3 - Module 3 Boolean AlgebraDocument5 pagesWeek 3 - Module 3 Boolean AlgebraBen GwenNo ratings yet
- Calculus II: Key Concepts and ApplicationsDocument38 pagesCalculus II: Key Concepts and ApplicationsTennysonNo ratings yet
- 2023 HSC Maths Ext 1Document20 pages2023 HSC Maths Ext 1n4eel3shNo ratings yet
- 1.1: The Bisection Method September 2019: MA385/530 - Numerical AnalysisDocument16 pages1.1: The Bisection Method September 2019: MA385/530 - Numerical AnalysisBashar JawadNo ratings yet
- Exam. Code: 107202 Subject Code: 1706Document2 pagesExam. Code: 107202 Subject Code: 1706Amrit KaurNo ratings yet
- Complex AnalysisDocument2 pagesComplex AnalysisAnsh RaghuwanshiNo ratings yet
- Computer Vision MCQ's For InterviewDocument12 pagesComputer Vision MCQ's For InterviewMallikarjun patilNo ratings yet
- Homework 3 Curve FittingDocument7 pagesHomework 3 Curve FittingAyech NabilNo ratings yet
- ML Question Bank and SolDocument12 pagesML Question Bank and SolPrabhu Prasad DevNo ratings yet
- Recursive algorithms chapterDocument24 pagesRecursive algorithms chapterAndrea CatalanNo ratings yet
- RootsDocument65 pagesRootsshiv ratnNo ratings yet
- Assignment II-2018 (MCSC-202)Document2 pagesAssignment II-2018 (MCSC-202)ramesh pokhrelNo ratings yet
- SM 17 18 XII Mathematics Unit-3 Section-BDocument6 pagesSM 17 18 XII Mathematics Unit-3 Section-BAkash PandeyNo ratings yet
- Revision - Final Exam Math 4Document14 pagesRevision - Final Exam Math 4Shahnizam SamatNo ratings yet
- Fitting curves and interpolation methodsDocument11 pagesFitting curves and interpolation methodsgobinathNo ratings yet
- Mastery in Gen. MathDocument2 pagesMastery in Gen. MathglaizacoseNo ratings yet
- Thesis AnttirtyDocument84 pagesThesis Anttirtynagatopein6No ratings yet
- PDFDocument31 pagesPDFnagatopein6No ratings yet
- Simulation of Neutronics For Advanced Reactors: Monte-Carlo MethodDocument54 pagesSimulation of Neutronics For Advanced Reactors: Monte-Carlo Methodnagatopein6No ratings yet
- 35015783Document10 pages35015783nagatopein6No ratings yet
- Planning For The Decommissioning of The ASTRA-ReactorDocument7 pagesPlanning For The Decommissioning of The ASTRA-Reactornagatopein6No ratings yet
- 10 Worker's Health SurveillanceDocument35 pages10 Worker's Health Surveillancenagatopein6No ratings yet
- Socn 1Document117 pagesSocn 1nagatopein6No ratings yet
- Safety Culture and Organisational Resilience in The Nuclear Industry Throughout The Different Lifecycle PhasesDocument132 pagesSafety Culture and Organisational Resilience in The Nuclear Industry Throughout The Different Lifecycle Phasesnagatopein6No ratings yet
- STUK-Proracun Zastite Za Med UstanoveDocument24 pagesSTUK-Proracun Zastite Za Med UstanoveMahiraNo ratings yet
- Compton Scattering ExperimentDocument37 pagesCompton Scattering ExperimentEka AziNo ratings yet
- Oversight of Nuclear Safety CultureDocument40 pagesOversight of Nuclear Safety Culturenagatopein6No ratings yet
- Author File Upload Guide: 18-June-2018Document11 pagesAuthor File Upload Guide: 18-June-2018Jarbas Vidal-FilhoNo ratings yet
- Fityk Manual: Release 1.3.1Document52 pagesFityk Manual: Release 1.3.1nagatopein6No ratings yet
- Boukamp 86 NonlinearDocument14 pagesBoukamp 86 Nonlinearnagatopein6No ratings yet
- Nonlinear Regression: What Is Nonlinear Model?Document19 pagesNonlinear Regression: What Is Nonlinear Model?nagatopein6No ratings yet
- Coincidence Gamma-Ray Spectrometry: Markovic, Nikola Roos, Per Nielsen, Sven PoulDocument6 pagesCoincidence Gamma-Ray Spectrometry: Markovic, Nikola Roos, Per Nielsen, Sven Poulnagatopein6No ratings yet
- Numerical Methods For Non-Linear Least Squares Curve FittingDocument55 pagesNumerical Methods For Non-Linear Least Squares Curve Fittingnagatopein6No ratings yet
- Algorithms 08 00082 v2 PDFDocument10 pagesAlgorithms 08 00082 v2 PDFहेम रामपालNo ratings yet
- REGDOC2 1 2 Safety Culture Final EngDocument31 pagesREGDOC2 1 2 Safety Culture Final Engnagatopein6No ratings yet
- Cuadrados Minimos Solver PDFDocument3 pagesCuadrados Minimos Solver PDFMachetin MachetinNo ratings yet
- Safety Culture and Organisational Resilience in The Nuclear Industry Throughout The Different Lifecycle PhasesDocument132 pagesSafety Culture and Organisational Resilience in The Nuclear Industry Throughout The Different Lifecycle Phasesnagatopein6No ratings yet
- Nonlinear Regression: What Is Nonlinear Model?Document19 pagesNonlinear Regression: What Is Nonlinear Model?nagatopein6No ratings yet
- PY 502, Computational Physics, Fall 2018 Numerical Solutions of The SCHR Odinger EquationDocument26 pagesPY 502, Computational Physics, Fall 2018 Numerical Solutions of The SCHR Odinger Equationnagatopein6No ratings yet
- Spent FuelDocument29 pagesSpent Fuelnagatopein6No ratings yet
- Inspector Alert Manual PDFDocument32 pagesInspector Alert Manual PDFnagatopein6No ratings yet
- Modeling and Simulation of Activated Corrosion Products Behavior Under Design-Based Variation of Neutron Flux Rate in AP-1000Document14 pagesModeling and Simulation of Activated Corrosion Products Behavior Under Design-Based Variation of Neutron Flux Rate in AP-1000nagatopein6No ratings yet
- Dickson Elijah D 2013Document45 pagesDickson Elijah D 2013nagatopein6No ratings yet
- DicksonElijahD2013 PDFDocument636 pagesDicksonElijahD2013 PDFnagatopein6No ratings yet
- AGUILA Automatic Coffee Machine User Manual - Instructions for Use EN DE FR ITDocument19 pagesAGUILA Automatic Coffee Machine User Manual - Instructions for Use EN DE FR ITPena Park HotelNo ratings yet
- Solution Map For Mining ppt3952 PDFDocument29 pagesSolution Map For Mining ppt3952 PDFHans AcainNo ratings yet
- Cardio Fitt Pin PostersDocument5 pagesCardio Fitt Pin Postersapi-385952225No ratings yet
- 1-Knowledge Assurance SM PDFDocument350 pages1-Knowledge Assurance SM PDFShahid MahmudNo ratings yet
- HBR - Michael Porter - Redefining Competition in Healthcare - 2004 PDFDocument14 pagesHBR - Michael Porter - Redefining Competition in Healthcare - 2004 PDFYusfin DelfitaNo ratings yet
- Rogers Lacaze Case InfoDocument1 pageRogers Lacaze Case InfomakeawishNo ratings yet
- Treatment: Animated Text Onstage:: Topic: Learning Objective: WMS Packages Module Introduction Display 1Document8 pagesTreatment: Animated Text Onstage:: Topic: Learning Objective: WMS Packages Module Introduction Display 1hikikNo ratings yet
- Manual vs Air Rotor Stripping SEM EvaluationDocument8 pagesManual vs Air Rotor Stripping SEM Evaluationlocos3dNo ratings yet
- Y10 ICT End of TermDocument7 pagesY10 ICT End of TermIvy Atuhairwe BisoborwaNo ratings yet
- Unit 14 Food Storage: StructureDocument13 pagesUnit 14 Food Storage: StructureRiddhi KatheNo ratings yet
- Week 1 - Revisiting and Evaluating FunctionsDocument12 pagesWeek 1 - Revisiting and Evaluating FunctionsShifra Jane PiqueroNo ratings yet
- UX5HPDocument2 pagesUX5HPNazih ArifNo ratings yet
- Mechanics of Solids by Sadhu Singhpdf Ebook and Ma PDFDocument1 pageMechanics of Solids by Sadhu Singhpdf Ebook and Ma PDFNeeraj Janghu0% (2)
- Samantha Serpas ResumeDocument1 pageSamantha Serpas Resumeapi-247085580No ratings yet
- BuildingDocument156 pagesBuildingMaya MayaNo ratings yet
- KORT RENZO C. BESARIO BS NURSING LESSON REVIEWDocument3 pagesKORT RENZO C. BESARIO BS NURSING LESSON REVIEWDummy AccountNo ratings yet
- Perspective Homework RubricDocument2 pagesPerspective Homework Rubricapi-244578825No ratings yet
- POMR Satiti Acute CholangitisDocument30 pagesPOMR Satiti Acute CholangitisIka AyuNo ratings yet
- Dialogo Ingles 4 FinalDocument3 pagesDialogo Ingles 4 FinalJoae KsnsnsNo ratings yet
- Visual Communication, Summary WritingDocument8 pagesVisual Communication, Summary WritingAsumpta MainaNo ratings yet
- LabVIEW Based EIT System TKBera IIScDocument6 pagesLabVIEW Based EIT System TKBera IISclatecNo ratings yet
- 3 Huang2015Document10 pages3 Huang2015kikoNo ratings yet