You might also like
- Measurement and Scaling ISM by HimanshuDocument39 pagesMeasurement and Scaling ISM by HimanshuAnshumaan Pratap BhagatNo ratings yet
- Measurement and ScalingDocument25 pagesMeasurement and ScalingmaNo ratings yet
- Measurement and Scaling RM2Document63 pagesMeasurement and Scaling RM2Roshel VargheseNo ratings yet
- Scaling & MeasurementDocument29 pagesScaling & MeasurementVinay AttriNo ratings yet
- (2022!03!03) Measurement and ScalingDocument44 pages(2022!03!03) Measurement and ScalingMahim WahaneNo ratings yet
- Measurement and ScaleDocument32 pagesMeasurement and ScaleBhumikaNo ratings yet
- Scaling (11 Files Merged) (2 Files Merged)Document642 pagesScaling (11 Files Merged) (2 Files Merged)Stark NixonNo ratings yet
- Marketing Research GuidelineDocument28 pagesMarketing Research GuidelineMETJI DigitalNo ratings yet
- Measurement and Scaling Techniques: BY Dr. Priyanka Rastogi (Guest Faculty)Document18 pagesMeasurement and Scaling Techniques: BY Dr. Priyanka Rastogi (Guest Faculty)priyanka386No ratings yet
- Measurementandscales 120411075801 Phpapp02 PDFDocument32 pagesMeasurementandscales 120411075801 Phpapp02 PDFshardultagalpallewarNo ratings yet
- Comparative ScaleDocument21 pagesComparative Scalerohan guptaNo ratings yet
- RMRP - Measurement and ScalingDocument47 pagesRMRP - Measurement and ScalingMayank TayalNo ratings yet
- 08 Fundamentals and Comparative ScalingDocument22 pages08 Fundamentals and Comparative ScalingAhanafNo ratings yet
- Measurement and Scaling: Fundamentals and Comparative ScalingDocument23 pagesMeasurement and Scaling: Fundamentals and Comparative ScalingmuneerppNo ratings yet
- Measurement and ScalingDocument44 pagesMeasurement and Scalingrathore.s.singh88No ratings yet
- Part 4 MeasurementDocument33 pagesPart 4 Measurementchaudharylalit025No ratings yet
- MeasurementDocument58 pagesMeasurementvenkatalakshmi lakshmiNo ratings yet
- Measurement: Assignment of Numbers or Symbols To Characteristics of Objects Example: Consumers' Perception Attitude Preferences It Is Like A MappingDocument37 pagesMeasurement: Assignment of Numbers or Symbols To Characteristics of Objects Example: Consumers' Perception Attitude Preferences It Is Like A MappingKumar SonuNo ratings yet
- BRM1Document41 pagesBRM1Anubhav GuptaNo ratings yet
- Descriptive Research DesignDocument43 pagesDescriptive Research Designjitender KUMARNo ratings yet
- 7-Measurement & ScalingDocument46 pages7-Measurement & ScalingPulkit DhanavaNo ratings yet
- Measurement and ScalingDocument12 pagesMeasurement and ScalingKartik AroraNo ratings yet
- Session 9Document24 pagesSession 9p23ayushmNo ratings yet
- Fdocuments - in t4 Measurement and ScalingDocument39 pagesFdocuments - in t4 Measurement and ScalingDEVADATTA B KOTENo ratings yet
- ScaleDocument36 pagesScalekd169No ratings yet
- Measurement and Scaling: Prof. (DR) Johney JohnsonDocument22 pagesMeasurement and Scaling: Prof. (DR) Johney JohnsonDevanarayanan SajiNo ratings yet
- Scales and Its TypesDocument9 pagesScales and Its Typesafaquek_2No ratings yet
- Scaling TechniquesDocument39 pagesScaling TechniquesGaurav ChauhanNo ratings yet
- Measurement and Scaling: UNIT:03Document36 pagesMeasurement and Scaling: UNIT:03Nishant JoshiNo ratings yet
- Measurement and ScalingDocument68 pagesMeasurement and ScalingRajendra LamsalNo ratings yet
- Chapter 7 - Scaling TechniqueDocument26 pagesChapter 7 - Scaling TechniquehairiNo ratings yet
- Business Research Methods-Unit II: Measurement & Scaling TechniquesDocument57 pagesBusiness Research Methods-Unit II: Measurement & Scaling TechniquesSuganya JagatheeshNo ratings yet
- Scales For Measurement Classification of Scaling TechniquesDocument25 pagesScales For Measurement Classification of Scaling TechniquesGowri J BabuNo ratings yet
- Questionnaire Design and Sampling: by Dr. Muhammad Ramzan, 03004487844 Edited by Ahsan Khan Eco 03008046243Document52 pagesQuestionnaire Design and Sampling: by Dr. Muhammad Ramzan, 03004487844 Edited by Ahsan Khan Eco 03008046243Shailendra PrajapatiNo ratings yet
- MR ScalingDocument34 pagesMR ScalingNiharika Satyadev JaiswalNo ratings yet
- Measurement and Scaling: Fundamentals and Comparative ScalingDocument23 pagesMeasurement and Scaling: Fundamentals and Comparative ScalingSasikala VaragunanNo ratings yet
- Measurement&Scaling AttitudeDocument66 pagesMeasurement&Scaling AttitudedeepanshuNo ratings yet
- Chapter Eight: Measurement and Scaling: Fundamentals and Comparative ScalingDocument26 pagesChapter Eight: Measurement and Scaling: Fundamentals and Comparative Scalingrahul_05622410No ratings yet
- Module 5Document49 pagesModule 5Tanvi DeshmukhNo ratings yet
- BRM Scaling 6Document43 pagesBRM Scaling 6jitender KUMARNo ratings yet
- Chapter Eight: Measurement and Scaling: Fundamentals and Comparative ScalingDocument11 pagesChapter Eight: Measurement and Scaling: Fundamentals and Comparative ScalingShrikant SahasrabudheNo ratings yet
- Measurement, Scaling, Sampling: Dr. Paurav ShuklaDocument21 pagesMeasurement, Scaling, Sampling: Dr. Paurav ShuklafikoNo ratings yet
- Scaling TechniquesDocument36 pagesScaling TechniquesSatya Sharma100% (1)
- Measurement & Scaling TechniquesDocument28 pagesMeasurement & Scaling TechniquesROHAN CHOPDENo ratings yet
- "Measurement in Research": H.Zothantluangi Research Scholar Management Deptt. Mizoram UniversityDocument23 pages"Measurement in Research": H.Zothantluangi Research Scholar Management Deptt. Mizoram UniversityMïMï Žöťhäñ HmäřNo ratings yet
- Measurement 1Document38 pagesMeasurement 1kami5185No ratings yet
- 04 BRMDocument43 pages04 BRMSatyajeet ChauhanNo ratings yet
- Measurement & Scaling TechniquesDocument34 pagesMeasurement & Scaling Techniquessaif_sheckh100% (1)
- Unit 3: Scaling TechniquesDocument13 pagesUnit 3: Scaling TechniquesPratibha GoswamiNo ratings yet
- Unit V Attitude Measurement ScaleDocument26 pagesUnit V Attitude Measurement ScaleNayan MorNo ratings yet
- Unit II ScalingDocument57 pagesUnit II ScalingGopal KrishnanNo ratings yet
- 2.9 Attitude ScalesDocument17 pages2.9 Attitude ScalesSYED ADNAN ALAMNo ratings yet
- Measurement and Scales For ResearcjhDocument72 pagesMeasurement and Scales For ResearcjhRomiNo ratings yet
- Business Research C6Document19 pagesBusiness Research C6tharun.dm254083No ratings yet
- Measurement ScalingDocument18 pagesMeasurement ScalingkanikaNo ratings yet
- Scaling: Business Research MethodsDocument23 pagesScaling: Business Research MethodsSatyajit GhoshNo ratings yet
- Measurement ScalesDocument27 pagesMeasurement ScalesYash GajwaniNo ratings yet
- Disastermanagement 220427172527Document111 pagesDisastermanagement 220427172527jinsi georgeNo ratings yet
- 10 - Chapter 1 DIabetic KineticsDocument12 pages10 - Chapter 1 DIabetic Kineticsjinsi georgeNo ratings yet
- Importance of Professional Values in Nursing Practice: Nurses PerspectiveDocument7 pagesImportance of Professional Values in Nursing Practice: Nurses Perspectivejinsi georgeNo ratings yet
- Problem.... New 2Document15 pagesProblem.... New 2jinsi georgeNo ratings yet
- MNSI HowtoDocument2 pagesMNSI HowtoEka BagaskaraNo ratings yet
- Fall RiskDocument10 pagesFall Riskjinsi georgeNo ratings yet
- Crisis Intervention: Sarina Giri Roll No:9 BSC NSG 3 YearDocument59 pagesCrisis Intervention: Sarina Giri Roll No:9 BSC NSG 3 Yearsimonjosan100% (1)
- Emerging Re Emerging Infections in India An.7Document13 pagesEmerging Re Emerging Infections in India An.7jinsi georgeNo ratings yet
- Viral EncephalitisDocument101 pagesViral EncephalitisalqyubiNo ratings yet
- Socioeconomic ScaleDocument5 pagesSocioeconomic ScaleElsy MayjoNo ratings yet
- Evidence Based Practice in Nuring-ContentsDocument13 pagesEvidence Based Practice in Nuring-Contentsjinsi georgeNo ratings yet
- Indian Nursing Council New Delhi Kerala Nurses & Midwives Council, ThiruvananthapuramDocument1 pageIndian Nursing Council New Delhi Kerala Nurses & Midwives Council, Thiruvananthapuramjinsi georgeNo ratings yet
- Acutemeningoencephalitis 170309112245Document41 pagesAcutemeningoencephalitis 170309112245jinsi georgeNo ratings yet
- Steps Review Ofb LiterarureDocument12 pagesSteps Review Ofb Literarurejinsi georgeNo ratings yet
- Thoracentesis PDFDocument5 pagesThoracentesis PDFjinsi georgeNo ratings yet
- Emerging Communicable Diseases, Biomedical WasteDocument11 pagesEmerging Communicable Diseases, Biomedical Wastejinsi georgeNo ratings yet
- Biomedical Waste ManagementDocument12 pagesBiomedical Waste ManagementAmanda Scarlet100% (5)
- Management of CADDocument99 pagesManagement of CADUmesh BabuNo ratings yet
- Lesson Plan Aptitude TestDocument2 pagesLesson Plan Aptitude Testjinsi georgeNo ratings yet
- Integrated TeachingDocument10 pagesIntegrated Teachingjinsi georgeNo ratings yet
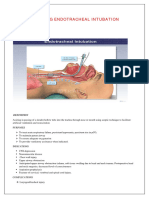
- Endo Trac IntubationDocument3 pagesEndo Trac Intubationjinsi georgeNo ratings yet
- Pulmonary RehabDocument7 pagesPulmonary Rehabjinsi georgeNo ratings yet
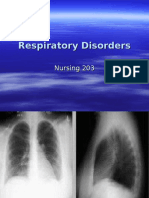
- Respiratory DisordersDocument82 pagesRespiratory DisordersJeffrey ViernesNo ratings yet
- Evaluationofeducationalprogramsinnursing 130309043334 Phpapp02Document22 pagesEvaluationofeducationalprogramsinnursing 130309043334 Phpapp02Anish VeettiyankalNo ratings yet
- Research TopDocument1 pageResearch Topjinsi georgeNo ratings yet
- RSPR - Volume 21 - Issue 1 - Pages 96-103Document8 pagesRSPR - Volume 21 - Issue 1 - Pages 96-103jinsi georgeNo ratings yet
- Creating An Effective PowerpointDocument37 pagesCreating An Effective Powerpointjinsi georgeNo ratings yet
- The Effect of Using Communication Boards On Ease.5Document5 pagesThe Effect of Using Communication Boards On Ease.5jinsi georgeNo ratings yet
- Buergerallenexerciseppt 220911014104 4e46516eDocument12 pagesBuergerallenexerciseppt 220911014104 4e46516ejinsi georgeNo ratings yet
- EQ JOURNAL 2 - AsioDocument3 pagesEQ JOURNAL 2 - AsioemanNo ratings yet
- Unit 2 - Industrial Engineering & Ergonomics - WWW - Rgpvnotes.inDocument15 pagesUnit 2 - Industrial Engineering & Ergonomics - WWW - Rgpvnotes.inSACHIN HANAGALNo ratings yet
- Web-Based Attendance Management System Using Bimodal Authentication TechniquesDocument61 pagesWeb-Based Attendance Management System Using Bimodal Authentication TechniquesajextopeNo ratings yet
- Sap New GL: Document Splitting - Configuration: ChooseDocument3 pagesSap New GL: Document Splitting - Configuration: ChooseChandra Sekhar PNo ratings yet
- Paul Wade - The Ultimate Isometrics Manual - Building Maximum Strength and Conditioning With Static Training-Dragon Door Publications (2020) - 120-146Document27 pagesPaul Wade - The Ultimate Isometrics Manual - Building Maximum Strength and Conditioning With Static Training-Dragon Door Publications (2020) - 120-146usman azharNo ratings yet
- Psychoanalytic Theory byDocument43 pagesPsychoanalytic Theory byjoy millano100% (1)
- Motivation Theories Description and CriticismDocument14 pagesMotivation Theories Description and CriticismAhmed Elgazzar89% (18)
- IMDSI22Document82 pagesIMDSI22Dang JinlongNo ratings yet
- Rishika Reddy Art Integrated ActivityDocument11 pagesRishika Reddy Art Integrated ActivityRishika ReddyNo ratings yet
- Unbound DNS Server Tutorial at CalomelDocument25 pagesUnbound DNS Server Tutorial at CalomelPradyumna Singh RathoreNo ratings yet
- Accounting Students' Perceptions On Employment OpportunitiesDocument7 pagesAccounting Students' Perceptions On Employment OpportunitiesAquila Kate ReyesNo ratings yet
- KCG-2001I Service ManualDocument5 pagesKCG-2001I Service ManualPatrick BouffardNo ratings yet
- Manual de Operacion y MantenimientoDocument236 pagesManual de Operacion y MantenimientoalexNo ratings yet
- The Rock Reliefs of Ancient IranAuthor (Document34 pagesThe Rock Reliefs of Ancient IranAuthor (mark_schwartz_41No ratings yet
- L5V 00004Document2 pagesL5V 00004Jhon LinkNo ratings yet
- Low Speed Aerators PDFDocument13 pagesLow Speed Aerators PDFDgk RajuNo ratings yet
- Persuasive Speech 2016 - Whole Person ParadigmDocument4 pagesPersuasive Speech 2016 - Whole Person Paradigmapi-311375616No ratings yet
- Battery Checklist ProcedureDocument1 pageBattery Checklist ProcedureKrauser ChanelNo ratings yet
- Getting Started With Citrix NetScalerDocument252 pagesGetting Started With Citrix NetScalersudharaghavanNo ratings yet
- Twin PregnancyDocument73 pagesTwin Pregnancykrishna mandalNo ratings yet
- Natural Cataclysms and Global ProblemsDocument622 pagesNatural Cataclysms and Global ProblemsphphdNo ratings yet
- Matrix PBX Product CatalogueDocument12 pagesMatrix PBX Product CatalogueharshruthiaNo ratings yet
- Healthymagination at Ge Healthcare SystemsDocument5 pagesHealthymagination at Ge Healthcare SystemsPrashant Pratap Singh100% (1)
- PNP Ki in July-2017 AdminDocument21 pagesPNP Ki in July-2017 AdminSina NeouNo ratings yet
- SavannahHarbor5R Restoration Plan 11 10 2015Document119 pagesSavannahHarbor5R Restoration Plan 11 10 2015siamak dadashzadeNo ratings yet
- Iec Codes PDFDocument257 pagesIec Codes PDFAkhil AnumandlaNo ratings yet
- Toshiba MotorsDocument16 pagesToshiba MotorsSergio Cabrera100% (1)
- Paper 1 AnalysisDocument2 pagesPaper 1 AnalysisNamanNo ratings yet
- Art of War Day TradingDocument17 pagesArt of War Day TradingChrispen MoyoNo ratings yet
- Introduction To Password Cracking Part 1Document8 pagesIntroduction To Password Cracking Part 1Tibyan MuhammedNo ratings yet