You might also like
- 003 - Option B Chapter 14 Engineering Physics PDFDocument62 pages003 - Option B Chapter 14 Engineering Physics PDFyuke kristinaNo ratings yet
- DSP FormulasDocument5 pagesDSP FormulasGuru Prasad Iyer0% (1)
- Charles L. Bernheimer - Rainbow Bridge - Circling Navajo Mountain and Explorations in The Bad Lands of Southern Utah and Northern ArizonaDocument251 pagesCharles L. Bernheimer - Rainbow Bridge - Circling Navajo Mountain and Explorations in The Bad Lands of Southern Utah and Northern Arizonaannedorival6718100% (1)
- State EstimationDocument23 pagesState EstimationMohit SinghNo ratings yet
- Bayes Filter Reminder: Bel (X P (X Bel (XDocument26 pagesBayes Filter Reminder: Bel (X P (X Bel (XTaimoor ShakeelNo ratings yet
- Finite Volume Schemes For Two Phase Incompressible Darcy FlowsDocument53 pagesFinite Volume Schemes For Two Phase Incompressible Darcy FlowsAhamadi ElhouyounNo ratings yet
- Stochastic Control PrincetonDocument14 pagesStochastic Control PrincetonSamrat MukhopadhyayNo ratings yet
- Module 14Document16 pagesModule 14augustus1189No ratings yet
- Linearized Equations of Motion: How Is System Response Calculated?"Document22 pagesLinearized Equations of Motion: How Is System Response Calculated?"Víctor FerNo ratings yet
- E12 08 Lab4 Coupled PendulumDocument7 pagesE12 08 Lab4 Coupled PendulumnervthcNo ratings yet
- Numerical IntegrationDocument67 pagesNumerical IntegrationMisgun SamuelNo ratings yet
- Section1 3Document21 pagesSection1 3sonti11No ratings yet
- Taylor C Omplex Numbers: V V D L D L Du LDocument1 pageTaylor C Omplex Numbers: V V D L D L Du Lleah tivuldNo ratings yet
- Table of Useful IntegralsDocument6 pagesTable of Useful IntegralsAjdin PalavrićNo ratings yet
- Fractional Calculus: Basic Theory and Applications: (Part III)Document18 pagesFractional Calculus: Basic Theory and Applications: (Part III)Danyal SharNo ratings yet
- Integral TableDocument4 pagesIntegral TableWasyhun AsefaNo ratings yet
- 13 - Time Response PDFDocument11 pages13 - Time Response PDFNuta ConstantinNo ratings yet
- Geometric Transformations in OpenGLDocument44 pagesGeometric Transformations in OpenGLWinnie TandaNo ratings yet
- Cayley Hamilton 2011Document10 pagesCayley Hamilton 2011rammar147No ratings yet
- M2 Za Vjezbu 1.1 PDFDocument3 pagesM2 Za Vjezbu 1.1 PDFSasa NaricNo ratings yet
- M2 Za Vjezbu 1.1101 PDFDocument3 pagesM2 Za Vjezbu 1.1101 PDFSasa NaricNo ratings yet
- Draw PDFDocument21 pagesDraw PDFVeronica GeorgeNo ratings yet
- 4-Component " Lateral-Directional Equations of Motion"Document11 pages4-Component " Lateral-Directional Equations of Motion"Felipe Balboa PolancoNo ratings yet
- Maximum Likelihood Method: MLM: pick α to maximize the probability of getting the measurements (the x 's) that we did!Document8 pagesMaximum Likelihood Method: MLM: pick α to maximize the probability of getting the measurements (the x 's) that we did!Gharib MahmoudNo ratings yet
- Name: - Section: - ScoreDocument4 pagesName: - Section: - ScoreDina M. ValdoriaNo ratings yet
- Materi Statistik 2Document27 pagesMateri Statistik 2ERISTRA NUNGSATRIA TRESNA ERNAWANNo ratings yet
- Introduction To OptimizationDocument9 pagesIntroduction To Optimizationxeta123No ratings yet
- MAE546 Lecture 10Document14 pagesMAE546 Lecture 10Shivan BiradarNo ratings yet
- Discrete Random Variables: IntegralDocument7 pagesDiscrete Random Variables: IntegralKanchana RandallNo ratings yet
- SPM Add Maths Formula List Form4Document15 pagesSPM Add Maths Formula List Form4Ng Lay HoonNo ratings yet
- Midterm Exam: Formulae From Weeks 1 - 7: T X y Z T X y y Z ZDocument1 pageMidterm Exam: Formulae From Weeks 1 - 7: T X y Z T X y y Z ZΧρίστος ΠαπαναστασίουNo ratings yet
- Ada 05 CDocument2 pagesAda 05 CjohnismintNo ratings yet
- Table of Integrals: Basic Forms Integrals With RootsDocument4 pagesTable of Integrals: Basic Forms Integrals With RootsBob HopeNo ratings yet
- Tabella Integrali Fondamentali: F (X) DX DX F ' (X) DX DF (X) F (X) KDX KDF (X) KF (X) X DXDocument1 pageTabella Integrali Fondamentali: F (X) DX DX F ' (X) DX DF (X) F (X) KDX KDF (X) KF (X) X DXapi-251901021No ratings yet
- Lab Report: Dynamic Analysis and Control On Single Machine Infinite Bus SystemDocument10 pagesLab Report: Dynamic Analysis and Control On Single Machine Infinite Bus SystemJack SheehyNo ratings yet
- Mae 331 Lecture 1Document13 pagesMae 331 Lecture 1Vasantha KumarNo ratings yet
- BIOE 162 Final Review 2014 HODocument36 pagesBIOE 162 Final Review 2014 HOtennisstarbyfarNo ratings yet
- Integral DificilDocument3 pagesIntegral DificilDaniel TomasNo ratings yet
- Mat 2Document2 pagesMat 2kurjakpaganskiNo ratings yet
- Tutorial 1Document5 pagesTutorial 1Kisalay KumarNo ratings yet
- Calculus Cheat Sheet AllDocument11 pagesCalculus Cheat Sheet AllDr Milan Glendza Petrovic NjegosNo ratings yet
- List of EquationsDocument4 pagesList of EquationsAnonymous y8WGaZOINo ratings yet
- Chapter 2. Deriving The Vlasov Equation From The Klimontovich EquationDocument6 pagesChapter 2. Deriving The Vlasov Equation From The Klimontovich Equationsujayan2005No ratings yet
- Table of Integrals: Basic Forms Integrals With RootsDocument4 pagesTable of Integrals: Basic Forms Integrals With RootsMuraliNo ratings yet
- Gases: Short Range, Important at Longer Range, Important atDocument10 pagesGases: Short Range, Important at Longer Range, Important atSaad AnisNo ratings yet
- Chapt Ere MiDocument4 pagesChapt Ere MiPrasit NakonratNo ratings yet
- ForimulaDocument2 pagesForimulaThe flying peguine CụtNo ratings yet
- 2016 MarkingDocument71 pages2016 Markingshane lakshithaNo ratings yet
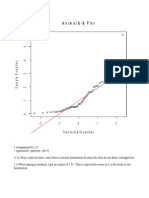
- Normal Q-Q Plot: - 2 - 1 0 1 2 Theoretical QuantilesDocument3 pagesNormal Q-Q Plot: - 2 - 1 0 1 2 Theoretical Quantilesnjs5277No ratings yet
- Section3 2Document19 pagesSection3 2sonti11No ratings yet
- Tutorial 1 - DDM MechatronicsDocument22 pagesTutorial 1 - DDM MechatronicsMuntoiaNo ratings yet
- Legendre Fortin MER2010 AppendagesDocument18 pagesLegendre Fortin MER2010 AppendagesCatalina Verdugo ArriagadaNo ratings yet
- Week 1 PDFDocument41 pagesWeek 1 PDFTanapat LapanunNo ratings yet
- 6 PolynomialsDocument21 pages6 PolynomialsDhanamalar VeerasimanNo ratings yet
- Lecture 1. Dipole Magnetic Field and Equations of Magnetic Field LinesDocument6 pagesLecture 1. Dipole Magnetic Field and Equations of Magnetic Field LinessoumitrahazraNo ratings yet
- Ten-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesFrom EverandTen-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesNo ratings yet
- Inverse Trigonometric Functions (Trigonometry) Mathematics Question BankFrom EverandInverse Trigonometric Functions (Trigonometry) Mathematics Question BankNo ratings yet
- Hyperbolic Functions (Trigonometry) Mathematics E-Book For Public ExamsFrom EverandHyperbolic Functions (Trigonometry) Mathematics E-Book For Public ExamsNo ratings yet
- Cases For Statcon 1Document6 pagesCases For Statcon 1Phoebe SG FanciscoNo ratings yet
- Exam 2Document6 pagesExam 2María Belkis Rozo MeloNo ratings yet
- Electromiografia RevneurolDocument14 pagesElectromiografia RevneurolCelia GodoyNo ratings yet
- Chara Dasha Calculation of Mahadasha Anthar Dasha and Prati Anthar DashDocument6 pagesChara Dasha Calculation of Mahadasha Anthar Dasha and Prati Anthar DashSunil RupaniNo ratings yet
- Passive Voice (Theory IMANOL)Document5 pagesPassive Voice (Theory IMANOL)Aitor Soto RuizNo ratings yet
- Hornby Panthers Turn 100Document1 pageHornby Panthers Turn 100Andrew VoermanNo ratings yet
- DT Analysis Guidelines v001.ALDocument14 pagesDT Analysis Guidelines v001.ALAkiro VianhNo ratings yet
- Solving Parts of A Triangle Using Circular FunctionDocument17 pagesSolving Parts of A Triangle Using Circular FunctionJisa PagodnasomuchNo ratings yet
- Ch-4 GSM Channels - and Interfaces LectureDocument105 pagesCh-4 GSM Channels - and Interfaces LectureShubham GargNo ratings yet
- Teza 1Document2 pagesTeza 1Mihaela NegreaNo ratings yet
- Fulltext 01Document54 pagesFulltext 01Shafayet UddinNo ratings yet
- The United Kingdom of Great Britain TextDocument1 pageThe United Kingdom of Great Britain TextDaniel BoscaneanuNo ratings yet
- LAS in PE 8 Quarter 1Document5 pagesLAS in PE 8 Quarter 1Reggie CorcueraNo ratings yet
- Art, Ancestors, and The Origins of Writing in ChinaDocument29 pagesArt, Ancestors, and The Origins of Writing in ChinaBenjamin HoshourNo ratings yet
- Audit 1Document25 pagesAudit 1Mohammad Saadman100% (1)
- Insights: The Faculty Journal of Austin SeminaryDocument44 pagesInsights: The Faculty Journal of Austin SeminaryaustinseminaryNo ratings yet
- Marathi Verb Morphology and POS Tagger: Veena DixitDocument10 pagesMarathi Verb Morphology and POS Tagger: Veena DixitarjunNo ratings yet
- Technical Assisstance Teachers 2022Document2 pagesTechnical Assisstance Teachers 2022Celeste MacalalagNo ratings yet
- Iiflar2011 12Document106 pagesIiflar2011 12Aisha GuptaNo ratings yet
- Semester 3 BpemDocument24 pagesSemester 3 BpemYOXE100% (1)
- unit5-MB 0001Document12 pagesunit5-MB 0001yogaknNo ratings yet
- DiflucanDocument1 pageDiflucanSheri490No ratings yet
- MT2204 Anum MT Regresi - Interpolasi PDFDocument17 pagesMT2204 Anum MT Regresi - Interpolasi PDFBoni PrakasaNo ratings yet
- SPA (With Title) - ConsentDocument15 pagesSPA (With Title) - ConsentsheniNo ratings yet
- Advisory Circular: 1. PURPOSE. This Advisory Circular (AC) Introduces The Concept of A SafetyDocument22 pagesAdvisory Circular: 1. PURPOSE. This Advisory Circular (AC) Introduces The Concept of A SafetyTrần Triệu PhongNo ratings yet
- Lesson PlansDocument7 pagesLesson Plansapi-316237434100% (1)
- Syllabus Information Retrieval TechniquesDocument2 pagesSyllabus Information Retrieval TechniquesDhurga DeviNo ratings yet