You might also like
- School Grade Level 11 Teacher Learning Area General Mathematics Teaching Dates and Time Jan.6-10,2019 Quarter Third QuarterDocument52 pagesSchool Grade Level 11 Teacher Learning Area General Mathematics Teaching Dates and Time Jan.6-10,2019 Quarter Third Quarteremmanuel peraltaNo ratings yet
- Ch06 Tool KitDocument36 pagesCh06 Tool KitRoy HemenwayNo ratings yet
- Daphne Koller, Nir Friedman Probabilistic Graphical Models Principles and Techniques 2009Document1,270 pagesDaphne Koller, Nir Friedman Probabilistic Graphical Models Principles and Techniques 2009Sigvart Aaserud Midling-Hansen100% (10)
- Lecture 5 PDFDocument14 pagesLecture 5 PDFQuoc KhanhNo ratings yet
- Quiz 1 Praktikum SahrulG 2111221001 DDocument3 pagesQuiz 1 Praktikum SahrulG 2111221001 DSahrul GunaWanNo ratings yet
- Lampirn TbelDocument5 pagesLampirn Tbelirma oktafiantiNo ratings yet
- IverwillmarkussiburianDocument3 pagesIverwillmarkussiburianIver Will Markus Siburian 15No ratings yet
- Ajuste de CurvasDocument35 pagesAjuste de CurvasosourlNo ratings yet
- Statisticsmod 3Document6 pagesStatisticsmod 3taylor swizzleNo ratings yet
- Biostatistics (CM Theory-Practicals)Document2 pagesBiostatistics (CM Theory-Practicals)AravindNo ratings yet
- Taller No.1 LunesBogotaHomicidiosDocument182 pagesTaller No.1 LunesBogotaHomicidiosDannaNo ratings yet
- Course Completion Times (Hours) : Current Training Proposed Training Current TrainingDocument5 pagesCourse Completion Times (Hours) : Current Training Proposed Training Current TrainingHope Trinity EnriquezNo ratings yet
- Perocho StatboardDocument8 pagesPerocho StatboardJeane AbastasNo ratings yet
- Descriptive StatisticsDocument6 pagesDescriptive Statisticspool jesus araujo cardozaNo ratings yet
- Tugas SPSSDocument8 pagesTugas SPSSWITA KUSMAWATINo ratings yet
- ExcerciseDocument12 pagesExcercisesrinithiNo ratings yet
- Hypothesis Testing Two PopulationDocument36 pagesHypothesis Testing Two PopulationM.MONIKANo ratings yet
- SBST3203 Elementary Data Analysis MAY 2020: Name: Arif Soebah Id No: 830811125679001 Phone Number: 013-8880791 EmailDocument9 pagesSBST3203 Elementary Data Analysis MAY 2020: Name: Arif Soebah Id No: 830811125679001 Phone Number: 013-8880791 Emailanwar soebahNo ratings yet
- Tugas Individu Normality N HomogenityDocument25 pagesTugas Individu Normality N HomogenityIvan Dwi SandraNo ratings yet
- Testing Hypothesis About22Document26 pagesTesting Hypothesis About22tahirajamilNo ratings yet
- Case Study On: Real FoodsDocument21 pagesCase Study On: Real Foodskkraja9No ratings yet
- Bsi Chi SquareDocument6 pagesBsi Chi SquareSufi RajNo ratings yet
- Australia Positive Case of Covid-19 DailyDocument12 pagesAustralia Positive Case of Covid-19 DailyRIZKA FIDYA PERMATASARI 06211940005004No ratings yet
- One-Sample Kolmogorov-Smirnov Test: Npar TestsDocument6 pagesOne-Sample Kolmogorov-Smirnov Test: Npar TestsAndi Aso Amir RisaldiNo ratings yet
- Spss Modul 4Document5 pagesSpss Modul 4Arie RafffNo ratings yet
- Hasil Spss LogDocument6 pagesHasil Spss LogdboyszNo ratings yet
- Stats Lecture 06. Normal Distribution DataDocument46 pagesStats Lecture 06. Normal Distribution DataShair Muhammad hazaraNo ratings yet
- Output SPSSDocument5 pagesOutput SPSSIswadi IdrisNo ratings yet
- DR. Waqar Al - KubaisyDocument36 pagesDR. Waqar Al - KubaisyMarah Khalid BurganNo ratings yet
- Edur 8131 Notes 2 Normal Standard ScoresDocument9 pagesEdur 8131 Notes 2 Normal Standard ScoresNazia SyedNo ratings yet
- SPSS StatistikaDocument4 pagesSPSS StatistikaIqbaalNo ratings yet
- Return On Equity (Roe) Terhadap Return Saham"Document23 pagesReturn On Equity (Roe) Terhadap Return Saham"ENI INDRIANINo ratings yet
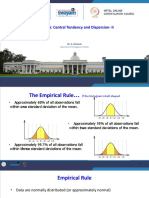
- Lecture 5: Central Tendency and Dispersion-II: Dr. A. RameshDocument19 pagesLecture 5: Central Tendency and Dispersion-II: Dr. A. RameshBattula SuryaNo ratings yet
- Statistical Tables: Useful FormulaeDocument5 pagesStatistical Tables: Useful FormulaeChris McLeanNo ratings yet
- Hoja de Datos Informe 1 Labo 1Document5 pagesHoja de Datos Informe 1 Labo 1flores.11060408No ratings yet
- Activity 6-Copai MethodDocument8 pagesActivity 6-Copai MethodᗷŁΔCᛕ CΔRDSNo ratings yet
- He So Giam Hoat TaiDocument10 pagesHe So Giam Hoat Taitekla gom-lua groupNo ratings yet
- rk-Smith-Ejm 5.1Document2 pagesrk-Smith-Ejm 5.1afsasfNo ratings yet
- Ncertainty Nalysis: Fixed Bias Errors (B) Errors Random Precision Errors (P)Document2 pagesNcertainty Nalysis: Fixed Bias Errors (B) Errors Random Precision Errors (P)Jacob OliphantNo ratings yet
- Hypothesis Testing Session 16Document28 pagesHypothesis Testing Session 16Mohit VermaNo ratings yet
- CHEGR 2650: Computer Methods in Chemical EngineeringDocument27 pagesCHEGR 2650: Computer Methods in Chemical EngineeringNebojsa MihajlovicNo ratings yet
- HC PoissonProcessesDocument14 pagesHC PoissonProcessesKELVIN JORDAN CASTILLO CASASOLANo ratings yet
- Balance Global Balance Por Componete 0.00315 Calculo de Reflureflujo Linea de Alimentacion Pendiente (m1) X yDocument3 pagesBalance Global Balance Por Componete 0.00315 Calculo de Reflureflujo Linea de Alimentacion Pendiente (m1) X yTanitDayanaPerezNo ratings yet
- Dokumen - Tips - Ken Black Qa ch10Document47 pagesDokumen - Tips - Ken Black Qa ch10Shreya ChutaniNo ratings yet
- 12 - Stat - Confidence Intervals For Variance and Standard Deviation 2024Document19 pages12 - Stat - Confidence Intervals For Variance and Standard Deviation 2024Ahsan SyafiiNo ratings yet
- SP Q4 Week 2 HandoutDocument10 pagesSP Q4 Week 2 HandoutLenard BelanoNo ratings yet
- Kuliah Korelasi 5 10 2022Document3 pagesKuliah Korelasi 5 10 2022Adi TamaNo ratings yet
- Regression Struktural 1: Descriptive StatisticsDocument6 pagesRegression Struktural 1: Descriptive StatisticsEdy SetyawanNo ratings yet
- ch06 Tool KitDocument36 pagesch06 Tool KitBrandon FrancomNo ratings yet
- Random Variables 2Document56 pagesRandom Variables 2Jaff LawrenceNo ratings yet
- Uji Pengaruh & Asumsi Klasik - HayatulDocument3 pagesUji Pengaruh & Asumsi Klasik - HayatulChandra SyahputraNo ratings yet
- RLB ContohDocument13 pagesRLB Contohluqmanul hakimNo ratings yet
- Curve Fitting: Instructor: Dr. Aysar Yasin Dep. of Energy and Env. EngineeringDocument18 pagesCurve Fitting: Instructor: Dr. Aysar Yasin Dep. of Energy and Env. EngineeringAmeer AlfuqahaNo ratings yet
- Outer ModelDocument144 pagesOuter ModelRaudhaNurJannahNo ratings yet
- Life Expentancy - 2Document18 pagesLife Expentancy - 2Samia AkterNo ratings yet
- Corelation and Reg.-12-27Document16 pagesCorelation and Reg.-12-27abhichugh2005No ratings yet
- Nama: Venesya Trisilia Pelupessy Nim: 51518011431 Oneway: WarningsDocument12 pagesNama: Venesya Trisilia Pelupessy Nim: 51518011431 Oneway: WarningsRemak RiskaNo ratings yet
- 15 - Simple Linear RegressionDocument21 pages15 - Simple Linear RegressionYow AkotoNo ratings yet
- Unit Task - Introduction To Statistical Inference and Summary of The Different Basic Statistical Tests (I)Document3 pagesUnit Task - Introduction To Statistical Inference and Summary of The Different Basic Statistical Tests (I)Kia GraceNo ratings yet
- Hypothesis Testing Two PopulationDocument30 pagesHypothesis Testing Two PopulationM.MONIKANo ratings yet
- Tugas 2Document15 pagesTugas 2Ari JwNo ratings yet
- Introduction to Statistics Through Resampling Methods and Microsoft Office ExcelFrom EverandIntroduction to Statistics Through Resampling Methods and Microsoft Office ExcelNo ratings yet
- BHI BrothDocument3 pagesBHI BrothHà Anh Minh LêNo ratings yet
- Biology: (Guidelines For The Preparation of The Entrance Exam To MSC Program in Biotechnology)Document304 pagesBiology: (Guidelines For The Preparation of The Entrance Exam To MSC Program in Biotechnology)Hà Anh Minh LêNo ratings yet
- Cooling A and Chilling of Milk-An Overview An Overview: Review Article Open AccessDocument9 pagesCooling A and Chilling of Milk-An Overview An Overview: Review Article Open AccessHà Anh Minh LêNo ratings yet
- Coagulase PlasmaDocument2 pagesCoagulase PlasmaHà Anh Minh LêNo ratings yet
- Coagulase Plasma (From Rabbit) (0.1gm Per Vial) : CompositionDocument1 pageCoagulase Plasma (From Rabbit) (0.1gm Per Vial) : CompositionHà Anh Minh LêNo ratings yet
- Chapter 1. Multivariable Calculus: Vietnam National University-Ho Chi Minh City International UniversityDocument88 pagesChapter 1. Multivariable Calculus: Vietnam National University-Ho Chi Minh City International UniversityHà Anh Minh LêNo ratings yet
- Cal2-Iu BT Chap3 Des SlidesDocument66 pagesCal2-Iu BT Chap3 Des SlidesHà Anh Minh LêNo ratings yet
- The International University (Iu) - Vietnam National University - HCMCDocument5 pagesThe International University (Iu) - Vietnam National University - HCMCHà Anh Minh LêNo ratings yet
- Cal2 IU BT Chapter1 Multivariable Calculus 2016 - SLIDESDocument69 pagesCal2 IU BT Chapter1 Multivariable Calculus 2016 - SLIDESHà Anh Minh LêNo ratings yet
- The International University (Iu) - Vietnam National University HCMCDocument8 pagesThe International University (Iu) - Vietnam National University HCMCHà Anh Minh LêNo ratings yet
- The International University (Iu) - Vietnam National University - HCMCDocument5 pagesThe International University (Iu) - Vietnam National University - HCMCHà Anh Minh LêNo ratings yet
- The International University (Iu) - Vietnam National University - HCMCDocument5 pagesThe International University (Iu) - Vietnam National University - HCMCHà Anh Minh LêNo ratings yet
- Grammar 16 Key: Practice 1: Supply The Correct Forms (To Infinitive or - Ing) of The Verbs in BracketsDocument3 pagesGrammar 16 Key: Practice 1: Supply The Correct Forms (To Infinitive or - Ing) of The Verbs in BracketsHà Anh Minh LêNo ratings yet
- Grammar 13 Key: A. Time Preposition (At, In, On, For, During )Document4 pagesGrammar 13 Key: A. Time Preposition (At, In, On, For, During )Hà Anh Minh LêNo ratings yet
- Grammar 19 Key: Example: An Ant? It's An Insect. Ants? Bees? They Are Insects.Document2 pagesGrammar 19 Key: Example: An Ant? It's An Insect. Ants? Bees? They Are Insects.Hà Anh Minh LêNo ratings yet
- Grammar 17 Key: International University - HCMC Department of EnglishDocument2 pagesGrammar 17 Key: International University - HCMC Department of EnglishHà Anh Minh LêNo ratings yet
- Grammar 18 Key: International University - HCMC Department of EnglishDocument3 pagesGrammar 18 Key: International University - HCMC Department of EnglishHà Anh Minh LêNo ratings yet
- Grammar 18 Reported Speech: A. Study This Example SituationDocument7 pagesGrammar 18 Reported Speech: A. Study This Example SituationHà Anh Minh LêNo ratings yet
- Grammar 20 ReviewDocument5 pagesGrammar 20 ReviewHà Anh Minh LêNo ratings yet
- This, That, These, Those, and One: Grammar 17Document4 pagesThis, That, These, Those, and One: Grammar 17Hà Anh Minh LêNo ratings yet
- Grammar 19 Countable and Uncountable NounsDocument7 pagesGrammar 19 Countable and Uncountable NounsHà Anh Minh LêNo ratings yet
- Lampiran Uji NormalitasDocument2 pagesLampiran Uji NormalitasAhmad Safi'iNo ratings yet
- Module 2 NotesDocument24 pagesModule 2 NotesKeshav MishraNo ratings yet
- Module 2 in IStat 1 Probability DistributionDocument6 pagesModule 2 in IStat 1 Probability DistributionJefferson Cadavos CheeNo ratings yet
- Shinozuka (1983) Basic Analysis of Structural SafetyDocument20 pagesShinozuka (1983) Basic Analysis of Structural SafetyFlavia GelattiNo ratings yet
- Strahler 1954Document25 pagesStrahler 1954Valter AlbinoNo ratings yet
- Research Article: An Integrated Expert System For Linear Scheduling Heavy Earthmoving OperationsDocument17 pagesResearch Article: An Integrated Expert System For Linear Scheduling Heavy Earthmoving OperationsOec EngNo ratings yet
- Comparison of Mean Using Paired-Observations: Two Populations Hypothesis TestingDocument9 pagesComparison of Mean Using Paired-Observations: Two Populations Hypothesis TestingNgoc NguyenNo ratings yet
- Chapter 5: Continuous Probability Distributions: Department of Mathematics Izmir University of EconomicsDocument42 pagesChapter 5: Continuous Probability Distributions: Department of Mathematics Izmir University of EconomicsCassidy Layug TañedoNo ratings yet
- Random Variables PDFDocument90 pagesRandom Variables PDFNJNo ratings yet
- Mathematics Honours Syllabus of Presidency UniversityDocument14 pagesMathematics Honours Syllabus of Presidency UniversityADITI LibraryNo ratings yet
- Pgm5 With OutputDocument13 pagesPgm5 With OutputManojNo ratings yet
- MBA Researcch ArticleDocument6 pagesMBA Researcch Articleghassan riazNo ratings yet
- Comprehensive Survey of RANSAC VariantsDocument34 pagesComprehensive Survey of RANSAC VariantsOlukanmi Peter Olubunmi100% (1)
- Solution For Assignment # 2 Sta 5206, 5126 & 4202Document27 pagesSolution For Assignment # 2 Sta 5206, 5126 & 4202Mon LuffyNo ratings yet
- IFoA Syllabus 2019-2017Document201 pagesIFoA Syllabus 2019-2017hvikashNo ratings yet
- On Spatial Contagion and mGARCH ModelsDocument36 pagesOn Spatial Contagion and mGARCH ModelsheraklisNo ratings yet
- MA8402-Probability and Queueing TheoryDocument21 pagesMA8402-Probability and Queueing TheoryPráviñ KumarNo ratings yet
- Stat 231 A1Document11 pagesStat 231 A1nathanNo ratings yet
- 5 Normal DistributionDocument34 pages5 Normal DistributionLa JeNo ratings yet
- 8 - Normal Distribution (Lecture)Document3 pages8 - Normal Distribution (Lecture)Jawwad Saeed KhanNo ratings yet
- Cumulative Standard Normal TableDocument1 pageCumulative Standard Normal TableDian Paul100% (1)
- Lesson 6 Normal DistributionDocument15 pagesLesson 6 Normal DistributionLoe HiNo ratings yet
- Statistics Text PDFDocument212 pagesStatistics Text PDFAnonymous XIwe3KKNo ratings yet
- Arfaoui - Et - Al - 2018 - An Optimal Multiscale Approach To Interpret Gravity DataDocument28 pagesArfaoui - Et - Al - 2018 - An Optimal Multiscale Approach To Interpret Gravity DataVinicius AntunesNo ratings yet
- Analysis of Covariance-ANCOVA-with Two Groups PDFDocument41 pagesAnalysis of Covariance-ANCOVA-with Two Groups PDFAmar BhanguNo ratings yet
- T TestDocument9 pagesT TestTushrNo ratings yet
- Regression and Correlation Methods in Highway Maintenance OperationsDocument11 pagesRegression and Correlation Methods in Highway Maintenance OperationsLestor NaribNo ratings yet
- RR 220101 Probability & StatisticsDocument2 pagesRR 220101 Probability & StatisticssivabharathamurthyNo ratings yet