You might also like
- 2 BoostDocument8 pages2 BoostArian100% (2)
- APQP Process FlowDocument13 pagesAPQP Process Flowkaca82No ratings yet
- Module 2 'Machine Learning-AI'Document19 pagesModule 2 'Machine Learning-AI'DE CASTRO, Xyra Kate D.No ratings yet
- AbInitio Tutorial OverviewDocument140 pagesAbInitio Tutorial OverviewSiriNo ratings yet
- AI and SecurityDocument11 pagesAI and SecurityASHUTOSH SONINo ratings yet
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (5)
- Free Traffic SourcesDocument12 pagesFree Traffic SourcesQuangdat NguyenNo ratings yet
- Artificial Intelligence Interview QuestionsDocument28 pagesArtificial Intelligence Interview QuestionsBrian GnorldanNo ratings yet
- What is AI? Artificial Intelligence Tutorial for BeginnersDocument56 pagesWhat is AI? Artificial Intelligence Tutorial for BeginnersSuman KumarNo ratings yet
- Machine Learning: Adaptive Behaviour Through Experience: Thinking MachinesFrom EverandMachine Learning: Adaptive Behaviour Through Experience: Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (5)
- AI: An overview of key concepts, applications, and technologiesDocument12 pagesAI: An overview of key concepts, applications, and technologiesAyeshaNo ratings yet
- Artificial IntelligenceDocument49 pagesArtificial IntelligenceKristopher France PunioNo ratings yet
- AI Revision QuestionsDocument14 pagesAI Revision QuestionsFonyuy TardzenyuyNo ratings yet
- AI Machine Learning 1 PDFDocument10 pagesAI Machine Learning 1 PDFADHD goingonNo ratings yet
- MFDM™ AiDocument48 pagesMFDM™ AiAyusman Panda50% (4)
- AI in HRMDocument108 pagesAI in HRMHari Prasad AnupojuNo ratings yet
- AI QuestionsDocument27 pagesAI QuestionsVaibhaw HirawatNo ratings yet
- Artificial Intelligence: Machine Learning, Deep Learning, and Automation ProcessesFrom EverandArtificial Intelligence: Machine Learning, Deep Learning, and Automation ProcessesRating: 5 out of 5 stars5/5 (2)
- AI Intro and Use CasesDocument6 pagesAI Intro and Use CasesKANWAR GAURAV SINGHNo ratings yet
- Artificial Intelligence (AI)Document14 pagesArtificial Intelligence (AI)Salaheddine Anamir100% (1)
- Artificial Intelligence: Data Analytics and Innovation for BeginnersFrom EverandArtificial Intelligence: Data Analytics and Innovation for BeginnersRating: 5 out of 5 stars5/5 (3)
- Artificial Intelligence: How Machine Learning, Robotics, and Automation Have Shaped Our SocietyFrom EverandArtificial Intelligence: How Machine Learning, Robotics, and Automation Have Shaped Our SocietyRating: 4.5 out of 5 stars4.5/5 (4)
- AI in Business and Data Analytics: Unleashing the Potential for Success: 1, #1From EverandAI in Business and Data Analytics: Unleashing the Potential for Success: 1, #1No ratings yet
- Conceptsforauto IDocument23 pagesConceptsforauto ImskcegNo ratings yet
- What Is Ai TechnologyDocument23 pagesWhat Is Ai TechnologyRyan FabianNo ratings yet
- Mba Programme School of Business and Management Christ (Deemed To Be University), BangaloreDocument10 pagesMba Programme School of Business and Management Christ (Deemed To Be University), BangaloreAkanksha Ranjan 2028039No ratings yet
- An Introduction to Artificial Intelligence (AIDocument10 pagesAn Introduction to Artificial Intelligence (AIAnurag TripathyNo ratings yet
- Finals Topic 2-Machine LearningDocument23 pagesFinals Topic 2-Machine LearningJeska GayanesNo ratings yet
- Digital TechDocument20 pagesDigital TechSaloni JainNo ratings yet
- Allaboutailuminarylabsjanuary122017 170112151616Document28 pagesAllaboutailuminarylabsjanuary122017 170112151616pruebaprueba00No ratings yet
- Artificial IntelligenceDocument14 pagesArtificial IntelligencekolarineNo ratings yet
- Chanllenges in AiDocument17 pagesChanllenges in AiKiruthiga RajendiranNo ratings yet
- CPE432 - Lecture Notes 1Document21 pagesCPE432 - Lecture Notes 1Rafael D. SanchezNo ratings yet
- AI (Artificial Intelligence) : Guide To AI in Customer Service Using Chatbots and NLPDocument16 pagesAI (Artificial Intelligence) : Guide To AI in Customer Service Using Chatbots and NLPdeepak rawatNo ratings yet
- Module 2 Section 5 AIDocument9 pagesModule 2 Section 5 AIElla MontefalcoNo ratings yet
- PdfScanner 1664335281137Document52 pagesPdfScanner 1664335281137Sohel MullaNo ratings yet
- Differt Artificial Intelligence CoursesDocument5 pagesDiffert Artificial Intelligence CoursesYogesh KareerNo ratings yet
- Results 4.1 Impact of Artificial IntelligenceDocument15 pagesResults 4.1 Impact of Artificial IntelligenceTRIZZANo ratings yet
- Forum 1 - MaulanaDocument4 pagesForum 1 - MaulanaMawie Hasan Maulana - AbdurahmanNo ratings yet
- 20Document19 pages20Amneet sistersNo ratings yet
- What is artificial intelligenceDocument5 pagesWhat is artificial intelligenceVadlamudi DhyanamalikaNo ratings yet
- MACHINELEARING UNIT 1materialDocument64 pagesMACHINELEARING UNIT 1materialAnonymous xMYE0TiNBcNo ratings yet
- Artificial Intelligence Research AreasDocument19 pagesArtificial Intelligence Research AreasSoufyane AyanouzNo ratings yet
- CPE432 - Lecture Notes 1Document26 pagesCPE432 - Lecture Notes 1afdsalado113No ratings yet
- Module - 1: Introduction To AIDocument128 pagesModule - 1: Introduction To AIJatadharNo ratings yet
- Edpm SbaDocument16 pagesEdpm SbaROYAL GAMINGNo ratings yet
- Ai PPT 1Document47 pagesAi PPT 1adĪtYa PàtHakNo ratings yet
- EdNex Proposal On AI IOT Autonomous Vehicle ARVR Blockchain For Industry 4.0Document47 pagesEdNex Proposal On AI IOT Autonomous Vehicle ARVR Blockchain For Industry 4.0janetNo ratings yet
- Artificial Intelligence & Machine LearningDocument10 pagesArtificial Intelligence & Machine LearningKESHAV JHANo ratings yet
- PR - 114 Task 2Document3 pagesPR - 114 Task 2seemaNo ratings yet
- AI, ML, DL and Data ScienceDocument13 pagesAI, ML, DL and Data ScienceSujitNo ratings yet
- Unit 1Document55 pagesUnit 1Harshita SharmaNo ratings yet
- Notes On Cognitive IntelligenceDocument4 pagesNotes On Cognitive IntelligenceshamNo ratings yet
- Lenovo AI PlaybookDocument18 pagesLenovo AI Playbookmarco.pozzoniNo ratings yet
- AI (Artificial Intelligence) : Expert Systems Speech Recognition Machine VisionDocument9 pagesAI (Artificial Intelligence) : Expert Systems Speech Recognition Machine VisionRasel moreNo ratings yet
- Machine Learning, history and types of MLDocument18 pagesMachine Learning, history and types of MLbhavana vashishthaNo ratings yet
- Emerging Tech Driving Business TransformationDocument35 pagesEmerging Tech Driving Business TransformationhimanshuNo ratings yet
- 3 - Chapitre 2 IADocument10 pages3 - Chapitre 2 IAGEEKGHAZINo ratings yet
- AI PresentationDocument5 pagesAI PresentationMurugappan AnnamalaiNo ratings yet
- SRS of Artificial IntellegenceDocument9 pagesSRS of Artificial IntellegenceVishnukant yadavNo ratings yet
- What Is The Significance of Artificial Intelligence and How Does It WorkDocument12 pagesWhat Is The Significance of Artificial Intelligence and How Does It WorkjackNo ratings yet
- Activity Sheet # 4Document5 pagesActivity Sheet # 4JaeNo ratings yet
- OFTW#2 - Emerging Technologies Artificial Intelligence (AI)Document8 pagesOFTW#2 - Emerging Technologies Artificial Intelligence (AI)depapcatNo ratings yet
- Winshuttle at PM: Rüdiger Weiss - RocheDocument20 pagesWinshuttle at PM: Rüdiger Weiss - Rochemahesh_rai44No ratings yet
- UA5000 Technical Manual PDFDocument161 pagesUA5000 Technical Manual PDFJames OmaraNo ratings yet
- Islem BenFraj CV Sep 2021Document1 pageIslem BenFraj CV Sep 2021saraaNo ratings yet
- ACCESSORIES and EQUIPMENT Communication - Non-DTC Based Diagnostics - Ram PickupDocument97 pagesACCESSORIES and EQUIPMENT Communication - Non-DTC Based Diagnostics - Ram PickupcharlesNo ratings yet
- Bai Tap Tieng Anh Lop 4 Chuong Trinh Moi Unit 18 What S Your Phone NumberDocument5 pagesBai Tap Tieng Anh Lop 4 Chuong Trinh Moi Unit 18 What S Your Phone NumberDevil -.-No ratings yet
- Administering Report SystemDocument472 pagesAdministering Report SystemvenuramNo ratings yet
- Certificate: Inderprastha Engineering College 63, Site - Iv Surya Nagar Flyover Road Sahibabad, GhaziabadDocument45 pagesCertificate: Inderprastha Engineering College 63, Site - Iv Surya Nagar Flyover Road Sahibabad, GhaziabadVèdãñt MíshrãNo ratings yet
- Test Equipment: Load Banks Test Benches Battery Discharge TestersDocument19 pagesTest Equipment: Load Banks Test Benches Battery Discharge TestersEduardo Puma AriasNo ratings yet
- Fiducial Markers For Pose EstimationDocument26 pagesFiducial Markers For Pose EstimationÃd ÄmNo ratings yet
- Cordova National High School: Quarter 1 Week 7Document12 pagesCordova National High School: Quarter 1 Week 7R TECHNo ratings yet
- Naveen Resume PDFDocument6 pagesNaveen Resume PDFNaveen ONo ratings yet
- Artificial Intelligence RCS 702: Faculty NameDocument37 pagesArtificial Intelligence RCS 702: Faculty NameChahatNo ratings yet
- Hmi PDFDocument15 pagesHmi PDFWalid KhalidNo ratings yet
- DP CAT 2015 Novasina EDocument18 pagesDP CAT 2015 Novasina EKang Gye-WonNo ratings yet
- Risk Score 0 Vulnerabilities: Useful LinksDocument5 pagesRisk Score 0 Vulnerabilities: Useful LinksMannan KhanNo ratings yet
- Manual System QBiX Plus EHLA6412 A1 - 20221213Document64 pagesManual System QBiX Plus EHLA6412 A1 - 20221213Nestor MartinezNo ratings yet
- Seeking Assignments, in Which I Can Get More Exposure To New Dimensions of SAP in A Company of ReputeDocument4 pagesSeeking Assignments, in Which I Can Get More Exposure To New Dimensions of SAP in A Company of ReputeRam MohanNo ratings yet
- Revolutionary Creative Thinking Method Unlocks Breakthrough IdeasDocument12 pagesRevolutionary Creative Thinking Method Unlocks Breakthrough IdeasDhanesh Kumar KasinathanNo ratings yet
- Marine HVAC Systems for Superior Comfort and EfficiencyDocument24 pagesMarine HVAC Systems for Superior Comfort and EfficiencyLucaNo ratings yet
- American International University-Bangladesh: Title: Design of A 2 To 4 Decoder and A Decimal To BCD EncoderDocument4 pagesAmerican International University-Bangladesh: Title: Design of A 2 To 4 Decoder and A Decimal To BCD EncoderAbid ChowdhuryNo ratings yet
- Test Bank For Fundamentals of Python Data Structures 2nd Edition Kenneth LambertDocument18 pagesTest Bank For Fundamentals of Python Data Structures 2nd Edition Kenneth LambertfrederickmarcusrxbsrNo ratings yet
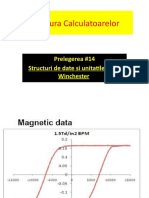
- Arhitectura Calculatoarelor: Prelegerea #14 Structuri de Date Si Unitatile de Tip WinchesterDocument19 pagesArhitectura Calculatoarelor: Prelegerea #14 Structuri de Date Si Unitatile de Tip WinchesterNelu TurcanuNo ratings yet
- Performance Optimization For Blockchain-Enabled Industrial Internet of Things (IIoT) Systems PDFDocument12 pagesPerformance Optimization For Blockchain-Enabled Industrial Internet of Things (IIoT) Systems PDFMumtahin HabibNo ratings yet
- Dokumen - Tips Kas 297a Maintenance Manual 006 05512 00033Document184 pagesDokumen - Tips Kas 297a Maintenance Manual 006 05512 00033plhoughtNo ratings yet
- Sysml OverviewDocument4 pagesSysml Overviewhornet82No ratings yet
- A Teaching Laboratory For Process ControlDocument6 pagesA Teaching Laboratory For Process Controlahmed ubeedNo ratings yet