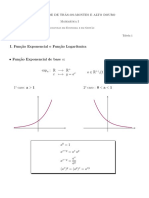
You might also like
- Lecture9 Helicity and ChiralityDocument16 pagesLecture9 Helicity and ChiralityEric Kumi BarimahNo ratings yet
- Problem 3.44 PDFDocument2 pagesProblem 3.44 PDFKauê BrittoNo ratings yet
- On The Resonant Lane-Emden Problem For The P-Laplacian: Grey ErcoleDocument20 pagesOn The Resonant Lane-Emden Problem For The P-Laplacian: Grey ErcoleJosé VanterlerNo ratings yet
- Qftnotes 3Document15 pagesQftnotes 3Arnab BhowmikNo ratings yet
- Derivation of The Jordan-Wigner Transformation: 1 Second QuantizationDocument2 pagesDerivation of The Jordan-Wigner Transformation: 1 Second QuantizationJay WhitfieldNo ratings yet
- Assignment 03 Number 04Document11 pagesAssignment 03 Number 04jaymart villartaNo ratings yet
- GR EquationsDocument1 pageGR EquationsJacob PearcyNo ratings yet
- HW Ch10 SolutionDocument5 pagesHW Ch10 SolutionMarceNo ratings yet
- AdvancedntDocument14 pagesAdvancedntDefault AccountNo ratings yet
- NotesDocument69 pagesNotescifarha venantNo ratings yet
- Cam Clay: Compliance Relationships: Soil Modelling: South East Asia: October-November 2010Document11 pagesCam Clay: Compliance Relationships: Soil Modelling: South East Asia: October-November 2010Anonymous v1blzDsEWANo ratings yet
- Christoffel SymbolsDocument5 pagesChristoffel SymbolsM Burhan JafeerNo ratings yet
- Partial Molar PropertiesDocument5 pagesPartial Molar PropertiesRojo JohnNo ratings yet
- HW 5Document4 pagesHW 5Tommy TangNo ratings yet
- Lagrange's Theorem: 1 NotationsDocument8 pagesLagrange's Theorem: 1 NotationsNadiaNo ratings yet
- A3 Structural Failure 2016 - Lesson 2Document29 pagesA3 Structural Failure 2016 - Lesson 2hassanbucheeri10No ratings yet
- Lifting The ExponentDocument4 pagesLifting The ExponentElchin MusazadeNo ratings yet
- Cosmology Exercises3Document11 pagesCosmology Exercises3adri95No ratings yet
- 09141210102012introducao A Fisica Estatistica Aula 7Document22 pages09141210102012introducao A Fisica Estatistica Aula 7Rafael BonatoNo ratings yet
- Tabel Apendix PKSDocument14 pagesTabel Apendix PKSNazia MahmudahNo ratings yet
- Tabela Funcoes TDocument8 pagesTabela Funcoes Tchelsia marisaNo ratings yet
- Introductory Chemical Engineering Thermodynamics: by J.R. Elliott and C.T. LiraDocument28 pagesIntroductory Chemical Engineering Thermodynamics: by J.R. Elliott and C.T. Lirapenelopezeus39No ratings yet
- Diagonalization and Powers of Matrices: Brian Krummel April 6, 2020Document7 pagesDiagonalization and Powers of Matrices: Brian Krummel April 6, 2020Sreeraj PavakkattuNo ratings yet
- Homework 8Document4 pagesHomework 8Brennan N Holly SchaeferNo ratings yet
- The Riemann Hypothesis and The Eulers Qu PDFDocument13 pagesThe Riemann Hypothesis and The Eulers Qu PDFarnoldo3551No ratings yet
- Artificial Neural Network - Hopfield Networks - TutorialspointDocument3 pagesArtificial Neural Network - Hopfield Networks - Tutorialspointprabhuraaj101No ratings yet
- Lectures 17-18Document100 pagesLectures 17-18Mr. WayneNo ratings yet
- Mock Commentary 2018: 05b Mathematics 2Document9 pagesMock Commentary 2018: 05b Mathematics 2Ha PhuongNo ratings yet
- Hamiltonian MechanicsDocument19 pagesHamiltonian MechanicsIjaz TalibNo ratings yet
- Kiritsis SolutionsDocument200 pagesKiritsis SolutionsSagnik MisraNo ratings yet
- Lec 14Document13 pagesLec 14semabayNo ratings yet
- QFT II Homework 5Document5 pagesQFT II Homework 5Evan RuleNo ratings yet
- Alice 1Document19 pagesAlice 1Nazmul AhsanNo ratings yet
- Goldstein Chapter 2.1 PDFDocument15 pagesGoldstein Chapter 2.1 PDFJulioCesarSanchezRodriguezNo ratings yet
- Homework 2 Solutions: 1. Quantized RotorDocument4 pagesHomework 2 Solutions: 1. Quantized RotorAzina KhanNo ratings yet
- Equi PartitionDocument3 pagesEqui PartitionZamasu DavidNo ratings yet
- Hracov EM2015Document8 pagesHracov EM2015StanNo ratings yet
- Jackson 3.4 Homework Problem SolutionDocument5 pagesJackson 3.4 Homework Problem SolutionMaria AmayaNo ratings yet
- GaussianintegralDocument12 pagesGaussianintegralJoy MenezesNo ratings yet
- 5 Quadratic Reciprocity Law: 5.1 Primitive Roots and Solutions of CongruencesDocument18 pages5 Quadratic Reciprocity Law: 5.1 Primitive Roots and Solutions of CongruencesPratik BorkarNo ratings yet
- Stability Analysis For OdesDocument13 pagesStability Analysis For OdesAbdul Latif AbroNo ratings yet
- Some Stability Results For Probability Spaces: H. L. Klein, C. Gupta, J. G Odel and I. WuDocument7 pagesSome Stability Results For Probability Spaces: H. L. Klein, C. Gupta, J. G Odel and I. WuweweqeNo ratings yet
- Lectures PDFDocument62 pagesLectures PDFAtul RaiNo ratings yet
- MA8353 PEC - by EasyEngineering - Net 02Document183 pagesMA8353 PEC - by EasyEngineering - Net 02SumanNo ratings yet
- P LaplaceDocument81 pagesP Laplaceandersongonzaga25yahoo.com.brNo ratings yet
- GS02-1093 - Introduction To Medical Physics I Basic Interactions Problem Set 2.2 SolutionsDocument6 pagesGS02-1093 - Introduction To Medical Physics I Basic Interactions Problem Set 2.2 SolutionsHanaTrianaNo ratings yet
- Kaku M. - Quantum Field TheoryDocument805 pagesKaku M. - Quantum Field Theoryapi-19626145100% (6)
- Problems For QCAPM: Questions and Solutions Compiled by Ka Man (Ambrose) YimDocument12 pagesProblems For QCAPM: Questions and Solutions Compiled by Ka Man (Ambrose) YimAmbrose YimNo ratings yet
- Gravitational Phase Transitions and The Sine-Gordon ModelDocument23 pagesGravitational Phase Transitions and The Sine-Gordon Modelwalter huNo ratings yet
- Ma6351 Pec UNIT - Tpde 1 PecDocument183 pagesMa6351 Pec UNIT - Tpde 1 PecEknath KrishNo ratings yet
- Chapter5 ScriptDocument5 pagesChapter5 ScriptAshwin BalajiNo ratings yet
- Problem 3.35 PDFDocument2 pagesProblem 3.35 PDFKauê BrittoNo ratings yet
- String TheoryDocument12 pagesString TheoryYashvinder SinghNo ratings yet
- Differentiation With Vectors and MatricesDocument2 pagesDifferentiation With Vectors and MatricesENJ0YY0URDAYNo ratings yet
- Qual 14 p2 SolDocument8 pagesQual 14 p2 SolKarishtain NewtonNo ratings yet
- 7.2 Vorticity in Inviscid Rotating Uids - Taylor - Proudman TheoremDocument2 pages7.2 Vorticity in Inviscid Rotating Uids - Taylor - Proudman TheoremRatovoarisoaNo ratings yet
- Jackson 3.5 Homework Problem SolutionDocument3 pagesJackson 3.5 Homework Problem Solution王孟謙No ratings yet
- The Spectral Theory of Toeplitz Operators. (AM-99), Volume 99From EverandThe Spectral Theory of Toeplitz Operators. (AM-99), Volume 99No ratings yet
- SMITH 2016 Essentials of Applied Econometrics Ch01Document18 pagesSMITH 2016 Essentials of Applied Econometrics Ch01Alexy FlemmingsNo ratings yet
- 02 Subat 28Document3 pages02 Subat 28Alexy FlemmingsNo ratings yet
- Barnett Seth 2019Document8 pagesBarnett Seth 2019Alexy FlemmingsNo ratings yet
- 2018 Klasik GC Ve CGC Farki LE 2018 Dynamic Connectedness of Global Currencies - A CGC ApproachDocument45 pages2018 Klasik GC Ve CGC Farki LE 2018 Dynamic Connectedness of Global Currencies - A CGC ApproachAlexy FlemmingsNo ratings yet
- BARNETT 2018 Misunderstandings Regarding The Application of Granger Causality in NeuroscienceDocument2 pagesBARNETT 2018 Misunderstandings Regarding The Application of Granger Causality in NeuroscienceAlexy FlemmingsNo ratings yet
- BARNETT 2017 Reply To Stokes and PurdonDocument2 pagesBARNETT 2017 Reply To Stokes and PurdonAlexy FlemmingsNo ratings yet
- Ales-Deneme 6 Cozum PDFDocument24 pagesAles-Deneme 6 Cozum PDFmetinNo ratings yet
- MJDF Mcqs - Mixed - PDFDocument19 pagesMJDF Mcqs - Mixed - PDFAyesha Awan0% (3)
- TSR 9440 - Ruined KingdomsDocument128 pagesTSR 9440 - Ruined KingdomsJulien Noblet100% (15)
- Mechanics of Materials 7th Edition Beer Johnson Chapter 6Document134 pagesMechanics of Materials 7th Edition Beer Johnson Chapter 6Riston Smith95% (96)
- A Mini-Review On New Developments in Nanocarriers and Polymers For Ophthalmic Drug Delivery StrategiesDocument21 pagesA Mini-Review On New Developments in Nanocarriers and Polymers For Ophthalmic Drug Delivery StrategiestrongndNo ratings yet
- FBISE Grade 10 Biology Worksheet#1Document2 pagesFBISE Grade 10 Biology Worksheet#1Moaz AhmedNo ratings yet
- Math - Snowflake With ProtractorsDocument4 pagesMath - Snowflake With Protractorsapi-347625375No ratings yet
- "Prayagraj ": Destination Visit ReportDocument5 pages"Prayagraj ": Destination Visit ReportswetaNo ratings yet
- Sip Poblacion 2019 2021 Revised Latest UpdatedDocument17 pagesSip Poblacion 2019 2021 Revised Latest UpdatedANNALLENE MARIELLE FARISCALNo ratings yet
- Higher Vapor Pressure Lower Vapor PressureDocument10 pagesHigher Vapor Pressure Lower Vapor PressureCatalina PerryNo ratings yet
- (LaSalle Initiative) 0Document4 pages(LaSalle Initiative) 0Ann DwyerNo ratings yet
- Brianna Pratt - l3stl1 - Dsu Lesson Plan TemplateDocument5 pagesBrianna Pratt - l3stl1 - Dsu Lesson Plan Templateapi-593886164No ratings yet
- Class 12 Unit-2 2022Document4 pagesClass 12 Unit-2 2022Shreya mauryaNo ratings yet
- IPMI Intelligent Chassis Management Bus Bridge Specification v1.0Document83 pagesIPMI Intelligent Chassis Management Bus Bridge Specification v1.0alexchuahNo ratings yet
- ETSI EG 202 057-4 Speech Processing - Transmission and Quality Aspects (STQ) - Umbrales de CalidaDocument34 pagesETSI EG 202 057-4 Speech Processing - Transmission and Quality Aspects (STQ) - Umbrales de Calidat3rdacNo ratings yet
- Quality Assurance Plan-75FDocument3 pagesQuality Assurance Plan-75Fmohamad chaudhariNo ratings yet
- Communication MethodDocument30 pagesCommunication MethodMisganaw GishenNo ratings yet
- 1Document14 pages1Cecille GuillermoNo ratings yet
- BSBSTR602 Project PortfolioDocument16 pagesBSBSTR602 Project Portfoliocruzfabricio0No ratings yet
- 4.1.1.6 Packet Tracer - Explore The Smart Home - ILM - 51800835Document4 pages4.1.1.6 Packet Tracer - Explore The Smart Home - ILM - 51800835Viet Quoc100% (1)
- LhiannanDocument6 pagesLhiannanGreybornNo ratings yet
- Matter Around Me: SC1 - Teaching Science in ElementaryDocument27 pagesMatter Around Me: SC1 - Teaching Science in ElementaryYanna Marie Porlucas Macaraeg50% (2)
- James KlotzDocument2 pagesJames KlotzMargaret ElwellNo ratings yet
- Marketing Plan Nokia - Advanced MarketingDocument8 pagesMarketing Plan Nokia - Advanced MarketingAnoop KeshariNo ratings yet
- An Analysis of The Cloud Computing Security ProblemDocument6 pagesAn Analysis of The Cloud Computing Security Problemrmsaqib1No ratings yet
- Promotion of Coconut in The Production of YoghurtDocument4 pagesPromotion of Coconut in The Production of YoghurtԱբրենիկա ՖերլինNo ratings yet
- Service Manual: NISSAN Automobile Genuine AM/FM Radio 6-Disc CD Changer/ Cassette DeckDocument26 pagesService Manual: NISSAN Automobile Genuine AM/FM Radio 6-Disc CD Changer/ Cassette DeckEduardo Reis100% (1)
- Case Studies InterviewDocument7 pagesCase Studies Interviewxuyq_richard8867100% (2)
- Know Your TcsDocument8 pagesKnow Your TcsRocky SinghNo ratings yet
- New KitDocument195 pagesNew KitRamu BhandariNo ratings yet
- Yuzu InstallerDocument3 pagesYuzu InstallerJohnnel PrietosNo ratings yet