You might also like
- Z-Transform of Discrete Functions for Digital Control SystemsDocument5 pagesZ-Transform of Discrete Functions for Digital Control SystemsSàazón KasulaNo ratings yet
- An Introduction To Malliavin Calculus With Applications To EconomicsDocument83 pagesAn Introduction To Malliavin Calculus With Applications To EconomicsselivesNo ratings yet
- Risk Analysis by Simulation (Monte Carlo Simulation) : Michael Wood, October, 2006 (Minor Revisions January 2009)Document3 pagesRisk Analysis by Simulation (Monte Carlo Simulation) : Michael Wood, October, 2006 (Minor Revisions January 2009)EdwinHarNo ratings yet
- 1 Time Series and Stationarity: Example Class 8Document2 pages1 Time Series and Stationarity: Example Class 8Marvin LieNo ratings yet
- Transformada ZDocument17 pagesTransformada Znikika1No ratings yet
- M475 - c2 - L4 - Z TransformDocument8 pagesM475 - c2 - L4 - Z TransformAli AlmakhmariNo ratings yet
- Handout Time Series For Sem II 2020 PDFDocument24 pagesHandout Time Series For Sem II 2020 PDFAkanksha DeyNo ratings yet
- DCS 2Document20 pagesDCS 2Anna BrookeNo ratings yet
- On A New Multivariate Sampling Paradigm and A Polyspline Shannon FunctionDocument23 pagesOn A New Multivariate Sampling Paradigm and A Polyspline Shannon FunctionKounchevNo ratings yet
- Chapter 5a Z-TransformDocument55 pagesChapter 5a Z-Transformfarina ilyanaNo ratings yet
- Electronic Realization of Fractional-Order SystemsDocument7 pagesElectronic Realization of Fractional-Order SystemsVignesh RamakrishnanNo ratings yet
- Physics Final - My VersionDocument48 pagesPhysics Final - My VersiondfbdbNo ratings yet
- On Frequency Domain Criterion of FiniteDocument8 pagesOn Frequency Domain Criterion of FiniteAlexander VoltaNo ratings yet
- EP 5511 - Lecture 02Document32 pagesEP 5511 - Lecture 02Solomon Tadesse AthlawNo ratings yet
- Lecture 2: Discrete-Time Systems and Z-TransformDocument18 pagesLecture 2: Discrete-Time Systems and Z-TransformFaheem AbbasiNo ratings yet
- Sy - Integral CalculusDocument12 pagesSy - Integral CalculusNeelam KapoorNo ratings yet
- Divide Conquer 2Document31 pagesDivide Conquer 2Mithil JogiNo ratings yet
- 3.1 Time-Domain Analysis of Control Systems: Unit-IiiDocument23 pages3.1 Time-Domain Analysis of Control Systems: Unit-IiiRajasekhar AtlaNo ratings yet
- Testing Residuals For White Noise in Time SeriesDocument16 pagesTesting Residuals For White Noise in Time Seriesali_alfaNo ratings yet
- DTState SpaceDocument11 pagesDTState SpaceWonbae ChoiNo ratings yet
- Unit-5 - Spectral Rep&EstimationDocument9 pagesUnit-5 - Spectral Rep&EstimationAntush TesfayeNo ratings yet
- Lecture 14Document15 pagesLecture 14gprem89No ratings yet
- Problems JacobiansDocument5 pagesProblems Jacobiansjiales225No ratings yet
- Discrete Approximation of Continuous Systems: CSE 421 Digital ControlDocument15 pagesDiscrete Approximation of Continuous Systems: CSE 421 Digital ControlAhmed YounisNo ratings yet
- Vibrating Measuring InstrumentDocument96 pagesVibrating Measuring InstrumentVishnu UpadyayaNo ratings yet
- 3D Bright-Bright Peregrine Triple-One Structures in A Nonautonomous Partially Nonlocal Vector Nonlinear SCHR Odinger Model Under A Harmonic PotentialDocument15 pages3D Bright-Bright Peregrine Triple-One Structures in A Nonautonomous Partially Nonlocal Vector Nonlinear SCHR Odinger Model Under A Harmonic PotentialJustin MibaileNo ratings yet
- Time Series Station, AR, MADocument30 pagesTime Series Station, AR, MAHospital BasisNo ratings yet
- Application of Lagrange Equations To 2D Double Spring-Pendulum in Generalized CoordinatesDocument15 pagesApplication of Lagrange Equations To 2D Double Spring-Pendulum in Generalized CoordinatesM SRINIVAS RAONo ratings yet
- SUTD EPD Homework SolutionsDocument8 pagesSUTD EPD Homework SolutionsMak Wai YongNo ratings yet
- Lecture-9 D.K Analysis-1Document36 pagesLecture-9 D.K Analysis-1Krishna KulkarniNo ratings yet
- IC6701 May 18 With KeyDocument14 pagesIC6701 May 18 With KeyAnonymous yO7rcec6vuNo ratings yet
- MHS11 Z TransformDocument16 pagesMHS11 Z TransformHassan El-kholyNo ratings yet
- Z TransformDocument12 pagesZ TransformKunal KundanamNo ratings yet
- Chapter2 Lect3Document14 pagesChapter2 Lect3Olga Joy Labajo GerastaNo ratings yet
- Chapter2 Lect3Document14 pagesChapter2 Lect3nctgayarangaNo ratings yet
- 8 Periodic Linear Di Erential Equations - Floquet TheoryDocument5 pages8 Periodic Linear Di Erential Equations - Floquet Theorycanoninha2No ratings yet
- 3 Fourier Series Representation of Periodic SignalsDocument31 pages3 Fourier Series Representation of Periodic SignalspatelIbrahimNo ratings yet
- Unit 3Document113 pagesUnit 3Jai Sai RamNo ratings yet
- Process Dynamic and Control - IntroDocument156 pagesProcess Dynamic and Control - IntroNuzul RamadhaniNo ratings yet
- Discrete Fourier Transform (DFT) : DR Malaya Kumar Hota (Prof., SENSE, VIT University)Document27 pagesDiscrete Fourier Transform (DFT) : DR Malaya Kumar Hota (Prof., SENSE, VIT University)Anirudh sai ReddyNo ratings yet
- 1 Random Processes: " " Is Considered An Important Background To Communication StudyDocument239 pages1 Random Processes: " " Is Considered An Important Background To Communication StudyPretty FibberNo ratings yet
- Control System Design ProjectDocument8 pagesControl System Design ProjectTulio Ernesto HernándezNo ratings yet
- WK 11Document36 pagesWK 11Muhammad BilalNo ratings yet
- Electromagnetic Field On Antenna-Eng+ItaDocument64 pagesElectromagnetic Field On Antenna-Eng+ItaLeonardo RubinoNo ratings yet
- EENG 226 Midterm Exam F13-14 SolnDocument6 pagesEENG 226 Midterm Exam F13-14 SolnTlektes SagingaliyevNo ratings yet
- Digital Control SystemsDocument82 pagesDigital Control SystemsMuthuraj BoseNo ratings yet
- Topic Two: II. Stationarity and ARMA ModellingDocument24 pagesTopic Two: II. Stationarity and ARMA ModellingCollins MuseraNo ratings yet
- Chapter 2 - Lecture NotesDocument20 pagesChapter 2 - Lecture NotesJoel Tan Yi JieNo ratings yet
- DCS 3Document22 pagesDCS 3Anna BrookeNo ratings yet
- Z Plane AnalizDocument47 pagesZ Plane Analizysm111No ratings yet
- BSC Honours in Statistics: HSTS 203: Time Series Analysis University of ZimbabweDocument6 pagesBSC Honours in Statistics: HSTS 203: Time Series Analysis University of ZimbabweKeith Tanyaradzwa MushiningaNo ratings yet
- Introduction to Random ProcessesDocument61 pagesIntroduction to Random Processesfouzia_qNo ratings yet
- Unit I Discrete State-Variable Technique 9Document15 pagesUnit I Discrete State-Variable Technique 9Arockia Pricilla SNo ratings yet
- Analysis of The Conical Piezoelectric Acoustic Emission TransducerDocument12 pagesAnalysis of The Conical Piezoelectric Acoustic Emission TransducerEmotional V.I.PNo ratings yet
- PDFDocument88 pagesPDFArjun NandyNo ratings yet
- EP 5511 - Lecture 09Document23 pagesEP 5511 - Lecture 09Solomon Tadesse AthlawNo ratings yet
- Non-Seasonal Box-Jenkins ModelsDocument75 pagesNon-Seasonal Box-Jenkins ModelsCarl AlbNo ratings yet
- An Over View of Digital Control SystemDocument46 pagesAn Over View of Digital Control SystemAnimesh JainNo ratings yet
- And Orbifold Models: DPKU-8903 May 1, 1989Document12 pagesAnd Orbifold Models: DPKU-8903 May 1, 1989Enrique EscalanteNo ratings yet
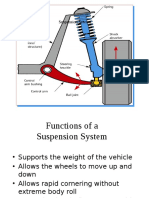
- SuspensionDocument26 pagesSuspensionTiliksew Wudie AssabeNo ratings yet
- Moter CHAPTER ONE-1Document56 pagesMoter CHAPTER ONE-1Tiliksew Wudie AssabeNo ratings yet
- Moter Chapter 5Document98 pagesMoter Chapter 5Tiliksew Wudie AssabeNo ratings yet
- SuspensionDocument26 pagesSuspensionTiliksew Wudie AssabeNo ratings yet
- Ic EngineDocument72 pagesIc Enginekedirabduri88No ratings yet
- Instrumentation Final ExamDocument25 pagesInstrumentation Final ExamTiliksew Wudie AssabeNo ratings yet
- Introduction To Time Series Analysis: Gloria González-Rivera and Jesús Gonzalo U. Carlos III de MadridDocument25 pagesIntroduction To Time Series Analysis: Gloria González-Rivera and Jesús Gonzalo U. Carlos III de MadridTiliksew Wudie AssabeNo ratings yet
- Adigrat University: College of Engineering and Technology Department of Chemical EnginneringDocument37 pagesAdigrat University: College of Engineering and Technology Department of Chemical EnginneringTiliksew Wudie AssabeNo ratings yet
- Chapter Three Materials and MethodologyDocument5 pagesChapter Three Materials and MethodologyTiliksew Wudie AssabeNo ratings yet
- Timeseries 586Document56 pagesTimeseries 586Anonymous iEtUTYPOh3No ratings yet
- Design ProjectDocument44 pagesDesign ProjectTiliksew Wudie AssabeNo ratings yet
- Chapter 3 MFG IIDocument145 pagesChapter 3 MFG IITiliksew Wudie Assabe100% (1)
- Vibration Chapter 1Document26 pagesVibration Chapter 1Tiliksew Wudie AssabeNo ratings yet
- Mechanical VibrationDocument16 pagesMechanical VibrationTiliksew Wudie AssabeNo ratings yet
- Apl StatisticsDocument353 pagesApl StatisticsDavor Babic100% (1)
- The Quadratic Formula and The Discriminant: You Should LearnDocument8 pagesThe Quadratic Formula and The Discriminant: You Should Learnfalcon724No ratings yet
- Basic Algebraic ExpressionsDocument5 pagesBasic Algebraic ExpressionsIlya SazwinaNo ratings yet
- Part3Module2 PDFDocument15 pagesPart3Module2 PDFKAUSTAV BASAKNo ratings yet
- Problem 19 Complex NumbersDocument1 pageProblem 19 Complex NumbersseansoniNo ratings yet
- Combinatorics 11695Document41 pagesCombinatorics 11695Klaus BudaNo ratings yet
- Excel - Functions & FormulasDocument9 pagesExcel - Functions & FormulasPrabodh VaidyaNo ratings yet
- NNC LustDocument38 pagesNNC Lustm_michael_cNo ratings yet
- Exercise Chapter 2Document11 pagesExercise Chapter 2anon_873980168No ratings yet
- D011493126Document38 pagesD011493126Mia VujisicNo ratings yet
- Mathematical Methods 3/4 Preparatory Exam: Question BookletDocument6 pagesMathematical Methods 3/4 Preparatory Exam: Question BookletLei LiNo ratings yet
- Matlab SignalDocument48 pagesMatlab SignalPanagiotis Giannoulis50% (2)
- 2014-2019 KG2 Maths Outcomes FinalDocument25 pages2014-2019 KG2 Maths Outcomes Finalhuda hamadNo ratings yet
- Complex Exponential and Logarithmic FunctionsDocument32 pagesComplex Exponential and Logarithmic FunctionsIr Raden PuspaNo ratings yet
- Module 1-Nature of Inquiry & ResearchDocument11 pagesModule 1-Nature of Inquiry & ResearchAngela Cuevas DimaanoNo ratings yet
- An Improved Optimization Method in Gas Allocation For Continuous Flow Gas-Lift SystemDocument12 pagesAn Improved Optimization Method in Gas Allocation For Continuous Flow Gas-Lift SystemAtrian RahadiNo ratings yet
- Group1 Theorem 6Document23 pagesGroup1 Theorem 6F- Baldado, Kathleen B.No ratings yet
- 2nd Quarter-St 1Document2 pages2nd Quarter-St 1April Dela Puerta SotomilNo ratings yet
- MATLAB Symbolic ExerciseDocument5 pagesMATLAB Symbolic Exercisesatya_vanapalli3422100% (1)
- Computation CDocument8 pagesComputation CVeeno DarveenaNo ratings yet
- Optimal ShockDocument16 pagesOptimal Shockjitendra25252No ratings yet
- Lesson 6 Techniques of IntegrationDocument27 pagesLesson 6 Techniques of IntegrationRaging PotatoNo ratings yet
- 7 Single Index ModelsDocument7 pages7 Single Index ModelsdssdNo ratings yet
- MATHEMATICAL FOUNDATIONS FOR COMPUTER SCIENCE PaperDocument1 pageMATHEMATICAL FOUNDATIONS FOR COMPUTER SCIENCE PaperAmrutha TarigopulaNo ratings yet
- On Some Characterization of Smarandache - Boolean Near - Ring With Sub-Direct Sum StructureDocument6 pagesOn Some Characterization of Smarandache - Boolean Near - Ring With Sub-Direct Sum StructureDon HassNo ratings yet
- Definition of Parametric EquationsDocument33 pagesDefinition of Parametric EquationsZhichein WongNo ratings yet
- Summative Test 3rd QuarterDocument9 pagesSummative Test 3rd QuarterIrish Diane Zales BarcellanoNo ratings yet
- 2.1 - 2.3 PDFDocument40 pages2.1 - 2.3 PDFMuhammad IkhwanNo ratings yet
- Paper of Linear ProgrammingDocument10 pagesPaper of Linear ProgrammingkhalishahNo ratings yet