You might also like
- DLL - Math 8 - Q2Document19 pagesDLL - Math 8 - Q2Jan neNo ratings yet
- Maths IIDocument88 pagesMaths IIAnish Kushwaha (Anshu)No ratings yet
- Statistics Previous Year Question PaperDocument12 pagesStatistics Previous Year Question Paperdericmoni8No ratings yet
- Adobe Scan 24-Aug-2023Document1 pageAdobe Scan 24-Aug-2023SK ASHIKNo ratings yet
- Fea Viva QuestionsDocument11 pagesFea Viva QuestionsSamir ShaikhNo ratings yet
- 3.2 Classification and Regression Models KNNDocument14 pages3.2 Classification and Regression Models KNNRajaNo ratings yet
- APP SyllabusDocument3 pagesAPP SyllabusFaker KumarNo ratings yet
- Grade 6 Matrix 1Document3 pagesGrade 6 Matrix 1darlene bianzonNo ratings yet
- Prof. A.C. Pandey: Pre - PHD SeminarDocument53 pagesProf. A.C. Pandey: Pre - PHD SeminarSaurabh KRNo ratings yet
- Web Eng TemplateDocument34 pagesWeb Eng TemplateBangkaw RowelNo ratings yet
- Jurnal Nilai Kritis LabDocument16 pagesJurnal Nilai Kritis LabAmalia EnggarNo ratings yet
- Mathematics 3Document67 pagesMathematics 3Kaushik DwivediNo ratings yet
- Video and Material - Programming in Java Materials - PROGRAMMING IN JAVA.21668851319440Document1 pageVideo and Material - Programming in Java Materials - PROGRAMMING IN JAVA.21668851319440Kabilesh CmNo ratings yet
- Module No. 1Document7 pagesModule No. 1Annalyn ArnaldoNo ratings yet
- Maggieb Lesson Plan 4Document4 pagesMaggieb Lesson Plan 4api-711469324No ratings yet
- @StudyTime - Channel Maths-4 PDFDocument12 pages@StudyTime - Channel Maths-4 PDFSipra PaulNo ratings yet
- @StudyTime - Channel Maths-4Document12 pages@StudyTime - Channel Maths-4Sipra PaulNo ratings yet
- Easy Education: ECON 2123Document10 pagesEasy Education: ECON 2123Vinton LauNo ratings yet
- Comp1012 (2015)Document16 pagesComp1012 (2015)FoxyDee Tsugi NoMaiNo ratings yet
- A Guide To PRMOIOQM Resonance Module (Resonance Eduventures Limited) (Z-Library)Document95 pagesA Guide To PRMOIOQM Resonance Module (Resonance Eduventures Limited) (Z-Library)KIngNo ratings yet
- Develop Tools For The Analysis and Design of Basic Linear Electric CircuitsDocument37 pagesDevelop Tools For The Analysis and Design of Basic Linear Electric Circuits김여명No ratings yet
- Feedback FormDocument2 pagesFeedback Formashish_9876No ratings yet
- CLASS VII - Operations On Rational NumbersDocument25 pagesCLASS VII - Operations On Rational NumbersAbhijit PatraNo ratings yet
- Exam 2023Document3 pagesExam 2023Muhammad UsmanNo ratings yet
- Chapter 1 Introduction To Differential Equation23 STUDENTSDocument6 pagesChapter 1 Introduction To Differential Equation23 STUDENTSFayi ToguinayNo ratings yet
- TOS 2nd Quarter Mathematics 7 NewDocument2 pagesTOS 2nd Quarter Mathematics 7 NewMechael ManzanoNo ratings yet
- Caie A2 Biology 9700 Practical v1Document10 pagesCaie A2 Biology 9700 Practical v1ARMANI ROYNo ratings yet
- Mathematics 2Document88 pagesMathematics 2avsharma7777No ratings yet
- q3 Mathematics 2Document6 pagesq3 Mathematics 2rozel.joy.ranola060317No ratings yet
- LSPU Self-Paced Learning Module (SLM) : CalculusDocument88 pagesLSPU Self-Paced Learning Module (SLM) : CalculusDharwyn Avy Advento CalmaNo ratings yet
- DLL - Mathematics 5 - Q3 - W1Document8 pagesDLL - Mathematics 5 - Q3 - W1Angelica De Vera LabayNo ratings yet
- 3 BusimathDocument2 pages3 BusimathJudy Ann ManansalaNo ratings yet
- First Order Differential EquationsDocument67 pagesFirst Order Differential EquationsMaalmalan KeekiyyaaNo ratings yet
- Heterogeneous Graph Attention NetworkDocument21 pagesHeterogeneous Graph Attention NetworkVikas KumarNo ratings yet
- AJP Unit-III ByOmiiiDocument4 pagesAJP Unit-III ByOmiiiOmanand SwamiNo ratings yet
- The Method of Partial Fractions: Preparation StepsDocument8 pagesThe Method of Partial Fractions: Preparation StepsZak KeroumNo ratings yet
- Module-4Document35 pagesModule-4Belle RoseNo ratings yet
- School Grade Level Teacher Learning Area General Mathematics Teaching Dates and Time Quarter I. ObjectivesDocument3 pagesSchool Grade Level Teacher Learning Area General Mathematics Teaching Dates and Time Quarter I. ObjectivesAdolf Ochia Odani50% (2)
- 02 Differential Equation Jeemain - Guru PDFDocument41 pages02 Differential Equation Jeemain - Guru PDFGaurav KumarNo ratings yet
- Mathematics 2Document4 pagesMathematics 2redaNo ratings yet
- Dip Das AssignmentDocument3 pagesDip Das AssignmentDip DasNo ratings yet
- CSE 3rd Sem SyllabusDocument19 pagesCSE 3rd Sem SyllabusArkadip ChowdhuryNo ratings yet
- Matrix 1Document8 pagesMatrix 1Paulo James SangotanNo ratings yet
- DA4675 CFA Level II SmartSheet 2020 PDFDocument10 pagesDA4675 CFA Level II SmartSheet 2020 PDFMabelita Flores100% (3)
- Engl ISH: Quarter 1, Module 5, Week 8Document8 pagesEngl ISH: Quarter 1, Module 5, Week 8Monaliza SequigNo ratings yet
- Lesson 1.5 - 2022Document18 pagesLesson 1.5 - 2022Aliph HamzahNo ratings yet
- Module7 PCA Clustering November 9-13-2023Document41 pagesModule7 PCA Clustering November 9-13-2023Sarwan ShahNo ratings yet
- Statistics Formula TablesDocument8 pagesStatistics Formula TablesSamantha RodriguezNo ratings yet
- Math 3 Third Periodic TestDocument6 pagesMath 3 Third Periodic TestMarianNo ratings yet
- Assignment Projct ManagmntDocument17 pagesAssignment Projct ManagmntIkramNo ratings yet
- Solution: Course Material 20-22Document8 pagesSolution: Course Material 20-22Gandhi Jenny Rakeshkumar BD20029No ratings yet
- Gantt Chart - Emma PHDDocument4 pagesGantt Chart - Emma PHDNURUL HIQMAH BINTI NORDINNo ratings yet
- DLL - Mathematics 5 - Q3 - W1Document5 pagesDLL - Mathematics 5 - Q3 - W1Gina Temple GarciaNo ratings yet
- Lesson 1 Differential Equations IntroDocument1 pageLesson 1 Differential Equations IntroeulaNo ratings yet
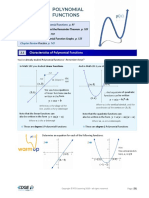
- 2.1 - Characteristics of Polynomial Functions Math 30-1Document14 pages2.1 - Characteristics of Polynomial Functions Math 30-1Math 30-1 EDGE Study Guide Workbook - by RTD LearningNo ratings yet
- Peer Review Audit 04 05 2022Document6 pagesPeer Review Audit 04 05 2022Amos WeislibNo ratings yet
- 11 - 4 - p12 - Minimum Distance Between Can ModesDocument6 pages11 - 4 - p12 - Minimum Distance Between Can Modessiavash mollayiNo ratings yet
- Cidam StatDocument4 pagesCidam StatJanisah Abdulsamad60% (5)
- Python Basics (Notes)Document92 pagesPython Basics (Notes)SURABHI ANNIGERI100% (1)
- Aspen Plus ReformerDocument134 pagesAspen Plus ReformerIbrahim RagabNo ratings yet
- Problems Solutions An Interactive Introduction To Mathematical Analysis - Lewin PDFDocument429 pagesProblems Solutions An Interactive Introduction To Mathematical Analysis - Lewin PDFFabio Jr da SilvaNo ratings yet
- 9702 w13 QP 4Document72 pages9702 w13 QP 4MehranurMajidNo ratings yet
- Analysis of ECG Signals by Dynamic Mode DecompositionDocument12 pagesAnalysis of ECG Signals by Dynamic Mode Decompositionmadhumita mishraNo ratings yet
- Sympy-0 7 2Document1,520 pagesSympy-0 7 2Luis Oliveira Silva100% (1)
- Theory Equilibrium Distribution of Solute Between Immiscible SolventDocument3 pagesTheory Equilibrium Distribution of Solute Between Immiscible Solventviwe100% (1)
- Chapter 4 Evaluating A Single ProjectDocument15 pagesChapter 4 Evaluating A Single ProjectAndrew GaaNo ratings yet
- 10 Simultaneous - in - Situ - Direction - Finding - and - Field - Manipulation - Based - On - Space-Time-Coding - Digital - MetasurfaceDocument10 pages10 Simultaneous - in - Situ - Direction - Finding - and - Field - Manipulation - Based - On - Space-Time-Coding - Digital - MetasurfaceAnuj SharmaNo ratings yet
- Maxwell 2D V14 Training - PriusDocument72 pagesMaxwell 2D V14 Training - PriusMostafa8425100% (1)
- Graph Theory MATH20150Document66 pagesGraph Theory MATH20150Sheetal KanelNo ratings yet
- 1D Colocated SIMPLE SolutionDocument14 pages1D Colocated SIMPLE Solutionosmanpekmutlu100% (1)
- Professor:Manish K Gupta Course: SC107 Calculus Fall 2016 Da-IictDocument5 pagesProfessor:Manish K Gupta Course: SC107 Calculus Fall 2016 Da-IictDhruvesh AsnaniNo ratings yet
- A Wavelet-Based Anytime Algorithm For K-Means Clustering of Time SeriesDocument12 pagesA Wavelet-Based Anytime Algorithm For K-Means Clustering of Time SeriesYaseen HussainNo ratings yet
- Particle Zoo: From Wikipedia, The Free EncyclopediaDocument7 pagesParticle Zoo: From Wikipedia, The Free EncyclopediajubaeNo ratings yet
- Circles For Grade 6Document6 pagesCircles For Grade 6pradeep LiyanaarachchiNo ratings yet
- Rapoport, A. 1986 Paradoxical Effects of Social BehaviorDocument186 pagesRapoport, A. 1986 Paradoxical Effects of Social BehaviorFernando Henao PachecoNo ratings yet
- Kenneth ArrowDocument11 pagesKenneth Arrowthomas555No ratings yet
- Aspects of Scientific Facts HempelDocument86 pagesAspects of Scientific Facts HempelAnonymous LOcT0gjqdSNo ratings yet
- Handbook of Anti-Gravity ResearchDocument727 pagesHandbook of Anti-Gravity ResearchSerguei L. Konovalenko100% (10)
- Contam 3.1Document307 pagesContam 3.1Reinhart85No ratings yet
- Java ExceptionDocument19 pagesJava ExceptionrajuvathariNo ratings yet
- A Maths 20-22Document316 pagesA Maths 20-22MattMattTv JapanNo ratings yet
- Materials: Science - Laboratory Instructions - Laboratory: Crime Scene SketchDocument4 pagesMaterials: Science - Laboratory Instructions - Laboratory: Crime Scene SketchboopNo ratings yet
- Boiler Tuning BasicsDocument18 pagesBoiler Tuning BasicsLester Pino100% (1)
- GMAT Quant Topic 1 (General Arithmetic) SolutionsDocument118 pagesGMAT Quant Topic 1 (General Arithmetic) SolutionsAndrew YeoNo ratings yet
- Paper1 PDFDocument13 pagesPaper1 PDFSebastianLopezNo ratings yet
- Numerical Control Machines-Notes-Kundra Rao & Tewari by AdityaDocument21 pagesNumerical Control Machines-Notes-Kundra Rao & Tewari by AdityaAditya Singh100% (2)
- Final MathDocument5 pagesFinal MathBrendan Lewis DelgadoNo ratings yet