You might also like
- Sample Chapter 2 MethodologyDocument9 pagesSample Chapter 2 MethodologyJOZEL PURAZONo ratings yet
- Chapter 3Document4 pagesChapter 3andengNo ratings yet
- Statistical Treatment of DataDocument1 pageStatistical Treatment of DataKaty Martha100% (1)
- Chapter IiiDocument4 pagesChapter IiiLian DolojanNo ratings yet
- Chapter 3Document8 pagesChapter 3Marc Jonas DiazNo ratings yet
- Data Gathering ProceduresDocument2 pagesData Gathering ProceduresYessaminNo ratings yet
- Chapter 3Document2 pagesChapter 3Renz Allen BanaagNo ratings yet
- Treatment of DataDocument3 pagesTreatment of DataMaria MiguelNo ratings yet
- Customer Satisfaction and Customer Loyalty Among Selected Restaurants in Panabo CityDocument3 pagesCustomer Satisfaction and Customer Loyalty Among Selected Restaurants in Panabo CityleizelNo ratings yet
- Chapter 3 Edited 7-26-22Document7 pagesChapter 3 Edited 7-26-22Raima CABARONo ratings yet
- Chapter 3Document14 pagesChapter 3Jericho EscanoNo ratings yet
- Chapter 3Document3 pagesChapter 3Mo NassifNo ratings yet
- Chapter 2Document8 pagesChapter 2Fidess Marie Malcaba AgbisitNo ratings yet
- Thesis Chapter IIIDocument4 pagesThesis Chapter IIIDarren BeltranNo ratings yet
- Chapter 3Document3 pagesChapter 3Jane SandovalNo ratings yet
- Statistical TreatmentDocument2 pagesStatistical TreatmentLi AriNo ratings yet
- Chapter 4 and 5 For DefenseDocument27 pagesChapter 4 and 5 For DefenseVhince Norben PiscoNo ratings yet
- Chapter IIIDocument12 pagesChapter IIIkevinmanansala26No ratings yet
- Descriptive Correlational Design Definition & Goals - 577 Words - Research Paper Example PDFDocument2 pagesDescriptive Correlational Design Definition & Goals - 577 Words - Research Paper Example PDFJenilyn CometaNo ratings yet
- STEM 11M TIOC (2) - Bautista, Sophia Heart C.Document2 pagesSTEM 11M TIOC (2) - Bautista, Sophia Heart C.Heart CruzNo ratings yet
- Chapter 2 Research MethodologyDocument6 pagesChapter 2 Research MethodologyshumaiylNo ratings yet
- Statistical TXDocument3 pagesStatistical TXJesse Israel TadenaNo ratings yet
- Impact of Service Quality On Customer Satisfaction and Customer Loyalty: Evidence From Banking SectorDocument24 pagesImpact of Service Quality On Customer Satisfaction and Customer Loyalty: Evidence From Banking SectorAssad BilalNo ratings yet
- Statistical Treatment of DataDocument2 pagesStatistical Treatment of DataKathrine CruzNo ratings yet
- 5th Chapter - COFFEE SHOPDocument10 pages5th Chapter - COFFEE SHOPRomel Remolacio AngngasingNo ratings yet
- Chapter 3 MethodologyDocument9 pagesChapter 3 MethodologyMarla Andrea SimbajonNo ratings yet
- Research ProposalDocument40 pagesResearch ProposalBrandon Alforque EsmasNo ratings yet
- Chapter 3Document0 pagesChapter 3Jermain HolmesNo ratings yet
- Research Chapter 5Document3 pagesResearch Chapter 5Robert Kcirde VallejoNo ratings yet
- Statistical TreatmentDocument1 pageStatistical Treatmentmonico39No ratings yet
- The Quantitative Data Obtained Through The Conduct of Survey Was Analyzed and Evaluated Using The Following Statistical TreatmentsDocument4 pagesThe Quantitative Data Obtained Through The Conduct of Survey Was Analyzed and Evaluated Using The Following Statistical TreatmentsAxel BumatayNo ratings yet
- Chapter 3 - Sabanal (90%)Document10 pagesChapter 3 - Sabanal (90%)Lemuel SabanalNo ratings yet
- RRLDocument6 pagesRRLNoemae CerroNo ratings yet
- Consumers Preference in Milk Tea Consumption in JaenDocument11 pagesConsumers Preference in Milk Tea Consumption in JaenJasmine Novelles ConstantinoNo ratings yet
- Chapter III (Thesis)Document7 pagesChapter III (Thesis)Leonora Erika RiveraNo ratings yet
- Motivating The Channel Members - IMT GHZ 011210Document22 pagesMotivating The Channel Members - IMT GHZ 011210gauravNo ratings yet
- Chapter 3Document14 pagesChapter 3JM Tomas RubianesNo ratings yet
- Statistical Treatment of DataDocument1 pageStatistical Treatment of DataTsundere DoradoNo ratings yet
- B. Form 2.2 Research Summary SheetDocument5 pagesB. Form 2.2 Research Summary SheetCristoper BodionganNo ratings yet
- Chapter 3Document4 pagesChapter 3bee byotchNo ratings yet
- Statistical Treatment of DataDocument1 pageStatistical Treatment of DataArrabellaNo ratings yet
- Chapter 3Document17 pagesChapter 3Luis OliveiraNo ratings yet
- Research MethodologyDocument3 pagesResearch Methodologynolan100% (1)
- Chapter 3 MelDocument6 pagesChapter 3 MelJefferson MoralesNo ratings yet
- RRL and RRS (Group 5)Document3 pagesRRL and RRS (Group 5)Ajeay PamintuanNo ratings yet
- Chapter 3Document7 pagesChapter 3Diane Iris AlbertoNo ratings yet
- CHAPTER 3 MethodologyDocument5 pagesCHAPTER 3 MethodologyKyla Jane GabicaNo ratings yet
- Orca Share Media1569579600307Document6 pagesOrca Share Media1569579600307Ronald AbletesNo ratings yet
- Chapter 3Document6 pagesChapter 3jeanne guarinoNo ratings yet
- Table 4.9 The Frequencies Distribution of The Respondents' GenderDocument6 pagesTable 4.9 The Frequencies Distribution of The Respondents' GenderMelinda Rahma ArulliaNo ratings yet
- Statistical Treatment of DataDocument29 pagesStatistical Treatment of DataRomar SantosNo ratings yet
- Thesis Methodology (Student Activism)Document4 pagesThesis Methodology (Student Activism)PJ Polanco ValenciaNo ratings yet
- Research in 3is REPARODocument30 pagesResearch in 3is REPAROMarigaille Hierco-BitangcorNo ratings yet
- Chapter 3Document5 pagesChapter 3Christine Joy GonzalesNo ratings yet
- Statistic Report Data GatheringDocument8 pagesStatistic Report Data GatheringFLORITA SERRANONo ratings yet
- Writing Chapter 4 - Data Analysis (Quantitative)Document6 pagesWriting Chapter 4 - Data Analysis (Quantitative)Jing Cruz100% (1)
- Chapter 3Document3 pagesChapter 3Ella DavidNo ratings yet
- Mathematicsunit 4lessonDocument67 pagesMathematicsunit 4lessonRami TounsiNo ratings yet
- Statistical Treatment of DataDocument3 pagesStatistical Treatment of DataEdward Aronciano100% (1)
- Statistical Treatment of DataDocument3 pagesStatistical Treatment of DataKim Ramos82% (33)
- My Personal Johari Window - Papa, John Christian C. - Abm 201Document1 pageMy Personal Johari Window - Papa, John Christian C. - Abm 201Christian PapaNo ratings yet
- Group 1 Research PaperDocument73 pagesGroup 1 Research PaperChristian PapaNo ratings yet
- ABM201 EAPP Group 3 02 Online Activity 1Document7 pagesABM201 EAPP Group 3 02 Online Activity 1Christian PapaNo ratings yet
- eLMS Quiz (Part 1) - ARGDocument3 pageseLMS Quiz (Part 1) - ARGPrince100% (3)
- ICA Terms and Conditions For Students For SY2021-22, First SemesterDocument2 pagesICA Terms and Conditions For Students For SY2021-22, First SemesterChristian PapaNo ratings yet
- The Reaction Paper, Review, and CritiqueDocument16 pagesThe Reaction Paper, Review, and CritiqueChristian PapaNo ratings yet
- Papa, John Christian C. ABM 201 - PEDocument1 pagePapa, John Christian C. ABM 201 - PEChristian PapaNo ratings yet
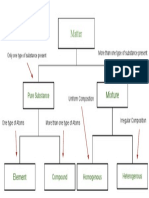
- Diagram of Classification of MatterDocument1 pageDiagram of Classification of MatterChristian PapaNo ratings yet
- Elms Quiz (Part 2) - ArgDocument1 pageElms Quiz (Part 2) - ArgChristian PapaNo ratings yet
- Market Trends & Market ObjectivesDocument2 pagesMarket Trends & Market ObjectivesChristian PapaNo ratings yet
- 01 Laboratory Exercise 1 1Document3 pages01 Laboratory Exercise 1 1Christian PapaNo ratings yet
- Black & Red Simple Completion CertificateDocument1 pageBlack & Red Simple Completion CertificateChristian PapaNo ratings yet
- Definition of TermsDocument2 pagesDefinition of TermsChristian PapaNo ratings yet
- Definition of TermsDocument2 pagesDefinition of TermsChristian PapaNo ratings yet
- Mercantilism Vs Physiocracy: The Brief Intro, Contribution, Pros & ConsDocument8 pagesMercantilism Vs Physiocracy: The Brief Intro, Contribution, Pros & ConsDaniyaNaiduNo ratings yet
- Effects of Background Music On The Behavior of Grade 12 Students in Sti College Novaliches A.Y. 2020-2021Document69 pagesEffects of Background Music On The Behavior of Grade 12 Students in Sti College Novaliches A.Y. 2020-2021Christian PapaNo ratings yet
- Address Telephone/Mobile Numbers Email Address: 2" X 2" Picture With White BackgroundDocument1 pageAddress Telephone/Mobile Numbers Email Address: 2" X 2" Picture With White BackgroundChristian PapaNo ratings yet
- Mind Map: Mental HealthDocument1 pageMind Map: Mental HealthChristian PapaNo ratings yet
- A Letter For MyselfDocument1 pageA Letter For MyselfChristian PapaNo ratings yet
- Economies: The Economic Impact of Lockdowns: A Persistent Inoperability Input-Output ApproachDocument14 pagesEconomies: The Economic Impact of Lockdowns: A Persistent Inoperability Input-Output ApproachFrancis Joseph Maano ReyesNo ratings yet
- Papa John Christian CDocument1 pagePapa John Christian CChristian PapaNo ratings yet
- Papa, John Christian C.Document1 pagePapa, John Christian C.Christian PapaNo ratings yet
- Chapter 4 PRDocument7 pagesChapter 4 PRChristian PapaNo ratings yet
- G123QW1 Worksheet - ResponsibilityDocument2 pagesG123QW1 Worksheet - ResponsibilityChristian PapaNo ratings yet
- Papa, John Christian C. RESUMEDocument1 pagePapa, John Christian C. RESUMEChristian PapaNo ratings yet
- ABM201 Group-3 MagazineDocument40 pagesABM201 Group-3 MagazineChristian PapaNo ratings yet
- CHAPTER 3 (Research Methodology) - Comfort RoomsDocument4 pagesCHAPTER 3 (Research Methodology) - Comfort RoomsJoseph Ong77% (43)
- HUMSS201 Papir Business-PlanDocument52 pagesHUMSS201 Papir Business-PlanChristian PapaNo ratings yet
- Statistical Treatment of DataDocument3 pagesStatistical Treatment of DataChristian PapaNo ratings yet
- Justification of The Analysis InterpretationDocument4 pagesJustification of The Analysis InterpretationChristian PapaNo ratings yet
- Customer Experience-An Analysis of The Concept and Its Performance inDocument11 pagesCustomer Experience-An Analysis of The Concept and Its Performance inIan AmadorNo ratings yet
- PSLP ASSIGNMENEtDocument4 pagesPSLP ASSIGNMENEtGyan AnandNo ratings yet
- Statistic Reviewer (Masters Degree)Document11 pagesStatistic Reviewer (Masters Degree)Japhet TendoyNo ratings yet
- Parts of A ThesisDocument1 pageParts of A Thesisyen100% (1)
- Quota Sampling - Research MethodologyDocument2 pagesQuota Sampling - Research MethodologySouroJeet100% (1)
- Perkiraan Karakteristika Curah Hujan Dengan Analisis Bangkitan DataDocument11 pagesPerkiraan Karakteristika Curah Hujan Dengan Analisis Bangkitan DataSyifa FauziyahNo ratings yet
- Probability SDocument9 pagesProbability SThenmozhi RavichandranNo ratings yet
- Presentation and Summary of DataDocument6 pagesPresentation and Summary of DataDr PNo ratings yet
- Lecture Note On Statistical Quality ControlDocument25 pagesLecture Note On Statistical Quality ControlKayode Samuel80% (5)
- Cha 5Document9 pagesCha 5Amalina Solahuddin50% (4)
- Science of The Total EnvironmentDocument8 pagesScience of The Total EnvironmentShakila Aulia ZahraNo ratings yet
- 1 Prob & Stats FAST (Final Term-Online Paper)Document3 pages1 Prob & Stats FAST (Final Term-Online Paper)RafayGhafoorNo ratings yet
- DWDM PPTDocument35 pagesDWDM PPTRakesh KumarNo ratings yet
- MATH 141L - Lab Course For MATH 141, Essentials of StatisticsDocument2 pagesMATH 141L - Lab Course For MATH 141, Essentials of StatisticsBrandon VelezNo ratings yet
- The Cost Performance and Causes of Overruns in Infrastructure Development Projects in AsiaDocument12 pagesThe Cost Performance and Causes of Overruns in Infrastructure Development Projects in AsiaTheGimhan123No ratings yet
- Practice A PDFDocument2 pagesPractice A PDFMiggy TanNo ratings yet
- Ge 21Document3 pagesGe 21Sanjay DebnathNo ratings yet
- Stock Price Simulation in RDocument37 pagesStock Price Simulation in Rthcm2011100% (1)
- ITC Notes 2Document36 pagesITC Notes 2Shanu NizarNo ratings yet
- Item Response Theory PDFDocument31 pagesItem Response Theory PDFSyahida Iryani100% (1)
- Knowledge of Tax Rights and Responsibilities1Document9 pagesKnowledge of Tax Rights and Responsibilities1ultramacNo ratings yet
- Artikel Ilmiah Aulia Sekar Pramesti 181100006Document13 pagesArtikel Ilmiah Aulia Sekar Pramesti 181100006auliaNo ratings yet
- Statistics 2009Document6 pagesStatistics 2009Tuki DasNo ratings yet
- Test Chap08Document13 pagesTest Chap08Elle Venchia0% (1)
- Visual Communications - MSc-Bharathiyaar UnivesityDocument10 pagesVisual Communications - MSc-Bharathiyaar UnivesityK SURESH KUMARNo ratings yet
- Machine Learning Project On Multiple Linear Regression ModelDocument12 pagesMachine Learning Project On Multiple Linear Regression ModelChewang Phuntsok BhutiaNo ratings yet
- ECOE 1302 Spring 2017 2slideDocument295 pagesECOE 1302 Spring 2017 2slideözgür YeniayNo ratings yet
- Pushpa Journal PresentationDocument10 pagesPushpa Journal Presentationpushpalogesh2006No ratings yet
- MATH3701 SyllabusDocument2 pagesMATH3701 SyllabusTimar Stay Focused JacksonNo ratings yet
- Khan Et AlDocument9 pagesKhan Et AlShoaib SulemaniNo ratings yet