You might also like
- บทที่ 4 การออกแบบการทดลองทากูชิ PDFDocument26 pagesบทที่ 4 การออกแบบการทดลองทากูชิ PDFณัฐพล บุญใสNo ratings yet
- FunctionDocument25 pagesFunctionPattrawut Rukkachart100% (1)
- System of Linear EquationsDocument9 pagesSystem of Linear EquationsYotin MaimanNo ratings yet
- บทที่ 4 การออกแบบการทดลองทากูชิ PDFDocument26 pagesบทที่ 4 การออกแบบการทดลองทากูชิ PDFณัฐพล บุญใสNo ratings yet
- บทที่ 9 เเก้เเล้วDocument30 pagesบทที่ 9 เเก้เเล้วa0934187546No ratings yet
- ฟังก์ชันลอกาลิทึม PDFDocument44 pagesฟังก์ชันลอกาลิทึม PDFKeawalee SongsriNo ratings yet
- ฟังก์ชันเอกโพเนนเชียลDocument56 pagesฟังก์ชันเอกโพเนนเชียลGet The ChanceNo ratings yet
- O Eng31Document9 pagesO Eng31Smith SongkhlaNo ratings yet
- CS1323 ExtraHW65-651790Document9 pagesCS1323 ExtraHW65-651790OakkyKung CHNo ratings yet
- เฉลย pat 1 ปี 58 PDFDocument11 pagesเฉลย pat 1 ปี 58 PDFพีรพล คิดรอบคอบNo ratings yet
- Stat - 7 Random SamplingDocument77 pagesStat - 7 Random SamplingSirinobporn BangjabNo ratings yet
- LogDocument50 pagesLogสาริณี เพียรการNo ratings yet
- HemostasisDocument9 pagesHemostasisPitchya WangmeesriNo ratings yet
- YlvkDocument71 pagesYlvkSurayos SopitpongNo ratings yet
- UntitledDocument141 pagesUntitled014 จนัสธา ลาภยิ่งยงNo ratings yet
- 4 7 QC ToolsDocument30 pages4 7 QC ToolsKampol HarnkittisakulNo ratings yet
- Unit 07Document22 pagesUnit 07sushikeNo ratings yet
- เฉลยข้อสอบ PAT 1 2558 ชุดที่ 5Document20 pagesเฉลยข้อสอบ PAT 1 2558 ชุดที่ 5Kanchit SaehoNo ratings yet
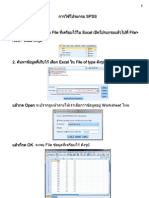
- การใช้โปรแกรม SPSSDocument29 pagesการใช้โปรแกรม SPSSธานินทร์ ทองกาล100% (1)
- ฟังชั่น บท2-M - 210917 - 113807Document18 pagesฟังชั่น บท2-M - 210917 - 113807MewSanmongkolNo ratings yet
- พหุนามDocument28 pagesพหุนามBankokChomchid67% (3)
- 5 Linear RegressionDocument52 pages5 Linear Regressionlnwwaii1234No ratings yet
- B X A ... X A X A: (Linear Equation System)Document14 pagesB X A ... X A X A: (Linear Equation System)Wachirawit YingchoedngamNo ratings yet
- สถิติและข้อมูลDocument80 pagesสถิติและข้อมูลสนธยา เสนามนตรี50% (2)
- MATLAB Basics ดร.จาตุรงค์ ตันติบัณฑิตDocument31 pagesMATLAB Basics ดร.จาตุรงค์ ตันติบัณฑิตBoonyarit KumkhetNo ratings yet
- เฉลยข้อสอบ PAT 1 2558 ชุดที่ 6Document10 pagesเฉลยข้อสอบ PAT 1 2558 ชุดที่ 6Kanchit SaehoNo ratings yet
- เฉลยข้อสอบ PAT 1 2558 ชุดที่ 3 PDFDocument9 pagesเฉลยข้อสอบ PAT 1 2558 ชุดที่ 3 PDFchaiNo ratings yet
- ฟังก์ชันDocument32 pagesฟังก์ชันZhicken KaiNo ratings yet
- จิรวรรณDocument17 pagesจิรวรรณPatamavan TrakanthaiNo ratings yet
- Nut LogarithmDocument17 pagesNut LogarithmAuthain KanvijittNo ratings yet
- Lecture 03Document40 pagesLecture 03Mai PanaNo ratings yet
- ใบงานแบบฝึกหัดคณิตศาสตร์ ป.3 เศษส่วนDocument36 pagesใบงานแบบฝึกหัดคณิตศาสตร์ ป.3 เศษส่วนJarawee HuipaoNo ratings yet
- กสพท 56Document5 pagesกสพท 56benz17716No ratings yet
- 7 QC ToolDocument22 pages7 QC ToolPradeep Mahalik0% (1)
- เอกสารติวหัวโขกฝา ฟังก์ชันDocument17 pagesเอกสารติวหัวโขกฝา ฟังก์ชันChaiwat SubatkamNo ratings yet
- เซตDocument3 pagesเซตK. JKNo ratings yet
- เอกสารประกอบครั้งที่ 1Document5 pagesเอกสารประกอบครั้งที่ 1patipon1664No ratings yet
- ระบบจำนวนจริงDocument166 pagesระบบจำนวนจริงKanyakarn Lappokachai100% (2)
- ฟังชั่น บท2-M - 210917 - 113807Document19 pagesฟังชั่น บท2-M - 210917 - 113807MewSanmongkolNo ratings yet
- ฟังชั่น บท2-M - 210917 - 113807Document19 pagesฟังชั่น บท2-M - 210917 - 113807MewSanmongkolNo ratings yet
- Function M5Document11 pagesFunction M5ญาณิศา รอดจันทึก 6109655149No ratings yet
- CEproj47 Planar-FrameDocument6 pagesCEproj47 Planar-FrameJirachai LaohaNo ratings yet
- ลิมิตและความต่อเนื่อง PDFDocument7 pagesลิมิตและความต่อเนื่อง PDFtop2No ratings yet
- Assignment G15 62015003 62015019Document12 pagesAssignment G15 62015003 62015019isaac vargasNo ratings yet
- ??????? 1.1 2Document2 pages??????? 1.1 2nee-301No ratings yet
- Final Exam 2550Document4 pagesFinal Exam 2550Anonymous uk7vv2No ratings yet
- แบบฝึกทักษะเรื่อง ระบบสมการเชิงเส้นDocument50 pagesแบบฝึกทักษะเรื่อง ระบบสมการเชิงเส้นBigchainarong YodBoonyalitNo ratings yet
- Multicollinearity ฉบับอาจารย์Document36 pagesMulticollinearity ฉบับอาจารย์leoNo ratings yet
- R For Beginners in ThaiDocument89 pagesR For Beginners in Thaiรัชนก บุญสีNo ratings yet
- 3 - 2 ข้อสอบปฏิบัติการ - TBO - 2019 - 3 - Cell - Edit 6 - April - เฉลยDocument14 pages3 - 2 ข้อสอบปฏิบัติการ - TBO - 2019 - 3 - Cell - Edit 6 - April - เฉลยkhwanpiya sae-limNo ratings yet
- ใบงาน ระบบสมการDocument6 pagesใบงาน ระบบสมการนางสาววินัญญา เณรภักดีNo ratings yet
- Multiple Linear Regression Report PDFDocument17 pagesMultiple Linear Regression Report PDFPRAPAS PANNANUSORNNo ratings yet
- ติวสบายคณิต (เพิ่มเติม) บทที่ 02 ระบบจำนวนจริงDocument52 pagesติวสบายคณิต (เพิ่มเติม) บทที่ 02 ระบบจำนวนจริงแมว ดำ100% (1)
- 317853380 ฟังก ชันลอกาลิทึม PDFDocument44 pages317853380 ฟังก ชันลอกาลิทึม PDFSirilak KlakwongNo ratings yet
- Log1 PDFDocument44 pagesLog1 PDFramjittiNo ratings yet
- สมบัติิของลิการิทึมDocument44 pagesสมบัติิของลิการิทึมsarinya.natbunNo ratings yet
- สมบัติของลอการิทึม PDFDocument44 pagesสมบัติของลอการิทึม PDFAtipoom0% (1)