You might also like
- Image Characteristics: Photographically Electronically Images Photographs ImageDocument21 pagesImage Characteristics: Photographically Electronically Images Photographs ImageJayHatNo ratings yet
- Visual Image InterpretationDocument37 pagesVisual Image InterpretationlahiyaNo ratings yet
- 6 VIP-FinalDocument35 pages6 VIP-Finalprash_mceNo ratings yet
- Unit 5 Ce333 PDFDocument20 pagesUnit 5 Ce333 PDFShanmuga SundaramNo ratings yet
- Rs&gis Unit-2 MaterialDocument26 pagesRs&gis Unit-2 Materialsrilakshmimurala7No ratings yet
- Remote Sensing-Image InterpretationDocument19 pagesRemote Sensing-Image InterpretationAnurag Kumar100% (1)
- Week-2 Module-2 Principles of Image InterpretationDocument25 pagesWeek-2 Module-2 Principles of Image InterpretationAKASH MAURYANo ratings yet
- Aerial Photos & Satellite ImageriesDocument37 pagesAerial Photos & Satellite ImageriesPankaj KushwahaNo ratings yet
- Abhishek KushDocument17 pagesAbhishek KushAbhishek KushNo ratings yet
- Experiment 1.3 AGP-316Document6 pagesExperiment 1.3 AGP-316Tej pattaNo ratings yet
- Image Correction - FCC - ClassificationDocument8 pagesImage Correction - FCC - ClassificationrohitNo ratings yet
- LEC5 - Interpreting Earth Surface DigitallyDocument64 pagesLEC5 - Interpreting Earth Surface DigitallyNaim LotfiNo ratings yet
- Photo InterprtationDocument28 pagesPhoto Interprtationhaile akelokNo ratings yet
- Aerial PhotographyDocument22 pagesAerial PhotographyHaftamuNo ratings yet
- Assignment No.: 5: Aim: TheoryDocument3 pagesAssignment No.: 5: Aim: TheoryPratik BNo ratings yet
- What Is A Digital Image: Pixel Values Typically Represent Gray Levels, Colours, Heights, Opacities EtcDocument7 pagesWhat Is A Digital Image: Pixel Values Typically Represent Gray Levels, Colours, Heights, Opacities Etctest topprNo ratings yet
- Ce-636 4 - Image InterpretationDocument50 pagesCe-636 4 - Image InterpretationYogesh SharmaNo ratings yet
- Digital Image ProcessingDocument10 pagesDigital Image ProcessingAnil KumarNo ratings yet
- Digital Image Processing Full ReportDocument9 pagesDigital Image Processing Full ReportAkhil ChNo ratings yet
- 4 - Image Processing and AnalysisDocument21 pages4 - Image Processing and Analysisrajaanwar100% (1)
- Qgis - Training - LabDocument23 pagesQgis - Training - Labsushma chandrikaNo ratings yet
- Lab 4Document12 pagesLab 4raaaaajjjjjNo ratings yet
- Fundamental of Visual Image Interpretation & Its KeysDocument14 pagesFundamental of Visual Image Interpretation & Its KeysHari Prasad RaoNo ratings yet
- Visual Image Interpretation Visual Interpretation and Digital Image Processing Techniques Are Two Important Techniques of Data Analysis to Extract Resource Related Information Either Independently or in Combination With KmkmDocument2 pagesVisual Image Interpretation Visual Interpretation and Digital Image Processing Techniques Are Two Important Techniques of Data Analysis to Extract Resource Related Information Either Independently or in Combination With KmkmREVATHY TRADERSNo ratings yet
- Shading and Texturing: I've Not Come From Nowhere To Be Nothing - Module 2Document42 pagesShading and Texturing: I've Not Come From Nowhere To Be Nothing - Module 2Dept PhysNo ratings yet
- Image ProcessingDocument170 pagesImage ProcessingDineshNo ratings yet
- Digital Image ProcessingDocument7 pagesDigital Image ProcessingRajiv VaddiNo ratings yet
- RemoteSensing-DigitalImageProcessing 2Document534 pagesRemoteSensing-DigitalImageProcessing 2henokmisaye23No ratings yet
- MAP PDN Revision NotesDocument21 pagesMAP PDN Revision Notesgreyproperties88No ratings yet
- Vikram Narayan Research Engineer GREYC, University of CaenDocument19 pagesVikram Narayan Research Engineer GREYC, University of Caensargam111111No ratings yet
- Remote Sensing Image ProcessingDocument137 pagesRemote Sensing Image ProcessingMahesh Pal100% (1)
- Content Base Image Retrieval Using Phong Shading Phong ShadingDocument22 pagesContent Base Image Retrieval Using Phong Shading Phong ShadingQuaziEmanualALendeyNo ratings yet
- GGE 4203-Intro To Gis & RS: Image Interpretation& Digital ProcessingDocument35 pagesGGE 4203-Intro To Gis & RS: Image Interpretation& Digital ProcessingIanNo ratings yet
- SodaPDF-merged-Merging ResultDocument296 pagesSodaPDF-merged-Merging ResultShubham DhundaleNo ratings yet
- DIP Unit 1 (Intro, 2D - Sig+Sys, Convo, Transform)Document128 pagesDIP Unit 1 (Intro, 2D - Sig+Sys, Convo, Transform)Shubham DhundaleNo ratings yet
- Unit-IV CCDocument167 pagesUnit-IV CCjhaa98676No ratings yet
- ComputerGraphicsWeek3 (Rasterization)Document33 pagesComputerGraphicsWeek3 (Rasterization)Ayesha RahimNo ratings yet
- Image Processing and AnalysisDocument16 pagesImage Processing and AnalysispoojavvceNo ratings yet
- ASSIGNMENT 2 RS - Santosh Kumar MArch16-19Document8 pagesASSIGNMENT 2 RS - Santosh Kumar MArch16-19santoshNo ratings yet
- Digital Image ProcessingDocument10 pagesDigital Image ProcessingAkash SuryanNo ratings yet
- Chapter 4brev - Digital Image ProcessingDocument85 pagesChapter 4brev - Digital Image ProcessingFaran MasoodNo ratings yet
- Visual Image Interpretation-TextDocument18 pagesVisual Image Interpretation-TextSaurabh Suman100% (5)
- Unit 3Document94 pagesUnit 3Shobhit MishraNo ratings yet
- Brain Tumor Extraction From MRI Images Using Matlab: A State ArtDocument4 pagesBrain Tumor Extraction From MRI Images Using Matlab: A State ArtCristian Marq'zNo ratings yet
- Unit 4Document17 pagesUnit 4Manish SontakkeNo ratings yet
- Week 5 - Image Processing: AAIN Eka Karyawati Informatics FMIPA UnudDocument29 pagesWeek 5 - Image Processing: AAIN Eka Karyawati Informatics FMIPA UnudEko PotterNo ratings yet
- Fundamentals of Image ProcessingDocument103 pagesFundamentals of Image ProcessingAvadhraj VermaNo ratings yet
- 01 Introduction To Computer GraphicsDocument42 pages01 Introduction To Computer GraphicsAjay GhugeNo ratings yet
- Digital Image ProcessingDocument169 pagesDigital Image Processingsnake teethNo ratings yet
- Class Note - Image Processing and GIS (Repaired)Document73 pagesClass Note - Image Processing and GIS (Repaired)Sanjay SinghNo ratings yet
- Principals and Elements of Image InterpretationDocument16 pagesPrincipals and Elements of Image InterpretationRhea Lyn CayobitNo ratings yet
- Digital Image ProcessingDocument57 pagesDigital Image ProcessingYatish ChutaniNo ratings yet
- Visual Image InterpreDocument29 pagesVisual Image InterprerphmiNo ratings yet
- Speaker Shagufta Akbari Assistant Prof. KL UniversityDocument30 pagesSpeaker Shagufta Akbari Assistant Prof. KL UniversitymanojmuthyalaNo ratings yet
- Unit-I: Digital Image Fundamentals & Image TransformsDocument70 pagesUnit-I: Digital Image Fundamentals & Image TransformsNuzhath FathimaNo ratings yet
- Nota RS5Document42 pagesNota RS5sham2258No ratings yet
- Digital Image Processing: Greenfort Engg. CollegeDocument27 pagesDigital Image Processing: Greenfort Engg. CollegeJomin PjoseNo ratings yet
- M11U03 Handout4t Interpreting APSIDocument7 pagesM11U03 Handout4t Interpreting APSIJesus Emmanuel Perez SalinasNo ratings yet
- Tone Mapping: Tone Mapping: Illuminating Perspectives in Computer VisionFrom EverandTone Mapping: Tone Mapping: Illuminating Perspectives in Computer VisionNo ratings yet
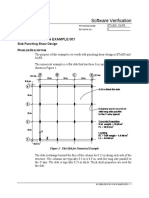
- HK Cp-2013 PT-SL Example 001Document6 pagesHK Cp-2013 PT-SL Example 001Aashu chaudharyNo ratings yet
- AS 3600-2018 RC-PN Example 001Document4 pagesAS 3600-2018 RC-PN Example 001Aashu chaudharyNo ratings yet
- Project ReportDocument41 pagesProject ReportAashu chaudhary100% (1)
- AS 3600-2018 PT-SL Example 001Document6 pagesAS 3600-2018 PT-SL Example 001Aashu chaudharyNo ratings yet
- BS 8110-1997 PT-SL Example 001Document6 pagesBS 8110-1997 PT-SL Example 001Aashu chaudharyNo ratings yet
- En 2-2004 RC-SL Example 001Document10 pagesEn 2-2004 RC-SL Example 001Aashu chaudharyNo ratings yet
- All Topic TSC and PSCDocument141 pagesAll Topic TSC and PSCAashu chaudharyNo ratings yet
- En 2-2004 RC-PN Example 001Document7 pagesEn 2-2004 RC-PN Example 001Aashu chaudharyNo ratings yet
- Certificate For COVID-19 Vaccination: Beneficiary DetailsDocument1 pageCertificate For COVID-19 Vaccination: Beneficiary DetailsAashu chaudharyNo ratings yet
- AR20 Civil 121121Document96 pagesAR20 Civil 121121Aashu chaudharyNo ratings yet
- Mix Design M - 40 GradeDocument3 pagesMix Design M - 40 GradeAashu chaudharyNo ratings yet
- ACKNOWLEDGEMENTDocument1 pageACKNOWLEDGEMENTAashu chaudharyNo ratings yet
- Mix Design M-40 GradeDocument2 pagesMix Design M-40 GradePruthvi TejaNo ratings yet
- AR20 Civil 121121Document96 pagesAR20 Civil 121121Aashu chaudharyNo ratings yet
- AR20 Mech 081121Document89 pagesAR20 Mech 081121Aashu chaudharyNo ratings yet
- Design of Beam Theory (Page 65-66)Document2 pagesDesign of Beam Theory (Page 65-66)Aashu chaudharyNo ratings yet
- 550x550 Column Design (Page 96-101)Document6 pages550x550 Column Design (Page 96-101)Aashu chaudharyNo ratings yet
- C1 RAILWAY ENGINEERING RajanDocument102 pagesC1 RAILWAY ENGINEERING RajanAashu chaudharyNo ratings yet
- Fly Ash Bricks PDFDocument46 pagesFly Ash Bricks PDFzilangamba_s4535100% (1)
- Design of Secondary Beam (Page 86-93)Document9 pagesDesign of Secondary Beam (Page 86-93)Aashu chaudharyNo ratings yet
- Elevator Wall Theory (Page 110)Document1 pageElevator Wall Theory (Page 110)Aashu chaudharyNo ratings yet
- Center of Mass and Center of Rigidity Calcuation A4Document1 pageCenter of Mass and Center of Rigidity Calcuation A4Aashu chaudharyNo ratings yet
- District Technical Office: Maintenance of Nepal Telecom BuildingDocument2 pagesDistrict Technical Office: Maintenance of Nepal Telecom BuildingAashu chaudharyNo ratings yet
- Project ReportDocument41 pagesProject ReportAashu chaudhary100% (1)
- 5.5 Transportation Engineering-I (PDF) by Akshay ThakurDocument91 pages5.5 Transportation Engineering-I (PDF) by Akshay ThakurAashu chaudharyNo ratings yet
- Unit 4 Construction of Roads and StressesDocument76 pagesUnit 4 Construction of Roads and StressesAashu chaudharyNo ratings yet
- Civil Engineering Aitam SyllabusDocument209 pagesCivil Engineering Aitam SyllabusAashu chaudharyNo ratings yet
- Project ReportDocument41 pagesProject ReportAashu chaudhary100% (1)
- Unit 4 Construction of Roads and StressesDocument76 pagesUnit 4 Construction of Roads and StressesAashu chaudharyNo ratings yet
- Presentation RAB Jalan Dan Jembatan PT. GUNUNG TANGINDocument9 pagesPresentation RAB Jalan Dan Jembatan PT. GUNUNG TANGINMuhammad Rabbil AlbadriNo ratings yet
- Dyneema Vs SteelDocument5 pagesDyneema Vs SteelSaurabh KumarNo ratings yet
- Gerus Air Driven Hydraulic PumpDocument7 pagesGerus Air Driven Hydraulic Pumpmahmoudayoub173No ratings yet
- Dharma: Basis of Human LifeDocument4 pagesDharma: Basis of Human LifeEstudante da Vedanta100% (1)
- Some Lower Bounds On The Reach of An Algebraic Variety: Chris La Valle Josué Tonelli-CuetoDocument9 pagesSome Lower Bounds On The Reach of An Algebraic Variety: Chris La Valle Josué Tonelli-CuetospanishramNo ratings yet
- Eagle: This Article Is About The Bird. For Other Uses, See - "Eagles" Redirects Here. For Other Uses, SeeDocument12 pagesEagle: This Article Is About The Bird. For Other Uses, See - "Eagles" Redirects Here. For Other Uses, SeeMegaEkaSetiawanNo ratings yet
- Pharmacology Antibiotics: Fluoroquinolone - Chloramphenicol - TetracycllineDocument40 pagesPharmacology Antibiotics: Fluoroquinolone - Chloramphenicol - TetracycllinemluthfidunandNo ratings yet
- Petroleum Products KolkataDocument3 pagesPetroleum Products KolkatabrijeshkynNo ratings yet
- Penetapan Kadar Sakarin, Asam Benzoat, Asam Sorbat, Kofeina, Dan Aspartam Di Dalam Beberapa Minuman Ringan Bersoda Secara Kro...Document13 pagesPenetapan Kadar Sakarin, Asam Benzoat, Asam Sorbat, Kofeina, Dan Aspartam Di Dalam Beberapa Minuman Ringan Bersoda Secara Kro...Wisnu WardhanaNo ratings yet
- ISolutions Lifecycle Cost ToolDocument8 pagesISolutions Lifecycle Cost ToolpchakkrapaniNo ratings yet
- Asus Prime b250m Plus RGDocument13 pagesAsus Prime b250m Plus RGRenattech SilvaNo ratings yet
- Geo PDFDocument13 pagesGeo PDFTezera Mark TmhNo ratings yet
- Front Axle, Tie Rod and Drag Link (A21) - 20: Parts ListDocument4 pagesFront Axle, Tie Rod and Drag Link (A21) - 20: Parts ListdgloshenNo ratings yet
- Ma2 - Acca - Chapter 1Document24 pagesMa2 - Acca - Chapter 1leducNo ratings yet
- OCDM2223 Tutorial7solvedDocument5 pagesOCDM2223 Tutorial7solvedqq727783No ratings yet
- 7 AcousticsDocument23 pages7 AcousticsSummer Yeoreumie100% (1)
- Computer Graphics Chapter-1Document61 pagesComputer Graphics Chapter-1abdi geremewNo ratings yet
- When A Migraine OccurDocument9 pagesWhen A Migraine OccurKARL PASCUANo ratings yet
- Anatomy ST1Document2 pagesAnatomy ST1m_kudariNo ratings yet
- How IoT Changed Our LifeDocument5 pagesHow IoT Changed Our LifeJawwad AhmadNo ratings yet
- Australian Mathematics Competition 2017 - SeniorDocument7 pagesAustralian Mathematics Competition 2017 - SeniorLaksanara KittichaturongNo ratings yet
- Analysis of Antioxidant Enzyme Activity During Germination of Alfalfa Under Salt and Drought StressesDocument8 pagesAnalysis of Antioxidant Enzyme Activity During Germination of Alfalfa Under Salt and Drought StressesJimenoNo ratings yet
- Vray MaterialsDocument206 pagesVray MaterialsDodeptrai BkNo ratings yet
- Manpower EstimationDocument28 pagesManpower EstimationRakesh Ranjan100% (2)
- Obturator / Orthodontic Courses by Indian Dental AcademyDocument97 pagesObturator / Orthodontic Courses by Indian Dental Academyindian dental academyNo ratings yet
- T 703Document4 pagesT 703Marcelo RojasNo ratings yet
- Neals Token InstrumentDocument39 pagesNeals Token InstrumentVikas Srivastav100% (2)
- Project: Study On Building Construction Using Foam ConcreteDocument5 pagesProject: Study On Building Construction Using Foam ConcreteAzhagesanNo ratings yet
- Model SS ChecklistDocument30 pagesModel SS ChecklistAnonymous PeuxGWWy8tNo ratings yet
- Ahmedabad BRTSDocument3 pagesAhmedabad BRTSVishal JainNo ratings yet